لقد أجرينا اختباراً أعمى لتقنية TTS الخاصة بنا ضد جميع المنافسين الرئيسيين. إليكم النتائج.

لقد أجرينا اختباراً أعمى لتقنية TTS الخاصة بنا ضد جميع المنافسين الرئيسيين. إليكم النتائج.
أجرت Fish Audio اختبار A/B أعمى لمدة 10 أيام على حركة مرور فعلية من بيئة الإنتاج، حيث وضعت Fish Audio S2 Pro و S1 في مواجهة ElevenLabs و Inworld و MiniMax. تم جمع أكثر من 5,000 زوج من التفضيلات من مستخدمين حقيقيين لم يكن لديهم أي فكرة عن المزود الذي قام بإنتاج كل مقطع صوتي.
باختصار: النتائج
احتلت Fish Audio S2 Pro المرتبة الأولى إجمالاً بدرجة Bradley-Terry بلغت 3.07، وهو ما يقرب من 1.7 ضعف أفضل نموذج تالٍ. كما تفوق نموذجنا الأقدم، Fish Audio S1 (بدرجة 1.86)، على كل مزود خارجي في المجموع الكلي.
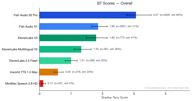
| المرتبة | النموذج | درجة BT | معدل الفوز | العينات |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3.07 | 65.7% | 4,573 |
| 2 | Fish Audio S1 | 1.86 | 41.0% | 3,560 |
| 3 | ElevenLabs V3 | 1.80 | 40.6% | 766 |
| 4 | ElevenLabs Multilingual V2 | 1.35 | 36.2% | 359 |
| 5 | ElevenLabs 2.5 Flash | 1.00 | 29.8% | 364 |
| 6 | Inworld TTS 1.5 Max | 0.59 | 20.1% | 373 |
| 7 | MiniMax Speech 2.8 HD | 0.12 | 5.0% | 201 |
المواجهات المباشرة الرئيسية:
- تفوق Fish S2 Pro على ElevenLabs V3 بنسبة 60% مقابل 40% (581 زوجاً)
- تفوق Fish S2 Pro على Inworld بنسبة 80% مقابل 20% (261 زوجاً)
- تفوق Fish S2 Pro على MiniMax بنسبة 95% مقابل 5% (142 زوجاً)
- تفوق Fish S1 على ElevenLabs V3 بنسبة 64% مقابل 36% (150 زوجاً)
لماذا فعلنا ذلك
مشكلة المقاييس التقليدية
لا يزال MOS (متوسط درجة الرأي) هو المعيار الواقعي لتقييم TTS، لكنه معيب للغاية. نادراً ما يتم الكشف عن ظروف الاختبار — فطول العينة، والتركيبة السكانية للمستمعين، وبيئة التشغيل، وتعليمات التقييم كلها تختلف عبر الدراسات، مما يجعل المقارنات بين الأوراق البحثية بلا معنى. وفي الوقت نفسه، يمكن أن يكون WER/CER (معدل خطأ الكلمات/الحروف) مقياساً عكسياً للتحسين: فدفع WER إلى مستويات منخفضة جداً غالباً ما يجبر النموذج على إصدار كلام آلي فائق النطق يضحي بالطبيعية والعروض الصوتي (prosody) من أجل الوضوح. النموذج الذي يتمتم أحياناً مثل إنسان حقيقي قد يبدو في الواقع أفضل من نموذج ينطق كل مقطع لفظي بدقة مثالية.
المشكلة في لوحات المتصدرين الموجودة
تقوم لوحات المتصدرين العامة مثل TTS-Arena-V2 و Artificial Analysis بتقييم النماذج بناءً على جمل قصيرة وبسيطة — عادة ما تكون سطراً واحداً من حوار أو سرداً وجيزاً. يفشل هذا في التقاط تعقيد استخدام TTS في العالم الحقيقي: المحتوى الطويل، الحوار بين متحدثين متعددين، وسوم العروض الصوتي التعبيرية، والنصوص متعددة اللغات.
بعيداً عن المنهجية، هناك مخاوف تتعلق بالنزاهة. واجهت TTS-Arena-V2 مشكلات معروفة تتعلق بـ تسريب ترويسة الصوت (audio header leaking)، حيث يمكن للبيانات الوصفية في ملف الصوت أن تكشف عن هوية المزود — مما يكسر فرضية التقييم الأعمى. نحن ندرك أيضاً أن التلاعب بلوحات المتصدرين (leaderboard gaming) منتشر على نطاق واسع: حيث يقوم المزودون بالتحسين خصيصاً لجمل القياس، أو تقديم نقاط تفتيش للنماذج منتقاة بعناية، أو تضخيم التصنيفات من خلال التصويت المنسق. أصبحت لوحات المتصدرين هذه أدوات تسويقية بدلاً من كونها إشارات موثوقة للجودة.
ما أردناه حقاً
كنا بحاجة إلى إشارة مكافأة داخلية موثوقة — مقياس حقيقي لـ "أي مخرجات TTS يفضلها المستخدمون الحقيقيون بالفعل؟" يمكننا الوثوق بها لاتخاذ قرارات تطوير النماذج. ليس رقماً من ورقة بحثية، ولا رتبة في لوحة متصدرين قابلة للتلاعب، بل تدفقاً مستمراً من بيانات التفضيل الصادقة من مستخدمين يتخذون خيارات حقيقية.
لذا، قمنا ببناء نظام تقييم أعمى مباشرة في منصتنا للإنتاج.
تصميم التجربة
المقارنة الزوجية العمياء
يعرض استوديو Fish Audio للمستخدمين نسختين صوتيتين جنباً إلى جنب لكل مهمة تحويل نص إلى كلام. كل نسخة لديها بشكل مستقل فرصة 10% ليتم توجيهها بصمت إلى مزود منافس بدلاً من واجهة Fish Audio الافتراضية. نفس النص، نفس الصوت المرجعي، نفس واجهة المستخدم — ليس لدى المستخدم أي فكرة عن المزود الذي أنتج كل صوت.
استمرت التجربة لمدة 10 أيام (26 مارس - 5 أبريل 2026) وجمعت أكثر من 71,000 مجموعة زوجية، منها 5,098 احتوت على مقارنات بين مزودين مختلفين استوفت معايير الجودة لدينا.
ما الذي يُعتبر "فوزاً"
نحن نستخدم إشارة سلوكية صارمة، وليس تقييماً ذاتياً:
- يجب على المستخدم تشغيل النسختين مرتين على الأقل لكل منهما — للتأكد من أنه قارن بينهما بالفعل.
- يتم تحميل نسخة واحدة فقط — وتلك هي الفائزة.
إشارة "الاستماع ثم التحميل" هذه أكثر موثوقية بكثير من تقييمات النجوم أو استطلاعات الاختيار القسري. يتخذ المستخدمون قرارات حقيقية بشأن الصوت الذي سيستخدمونه بالفعل.
تكوين المستخدمين
شملت التجربة حوالي 70% مستخدمين جدد و 30% مستخدمين عائدين. قد يقدم هذا التكوين انحيازاً طفيفاً لصالح Fish Audio (المستخدمون العائدون على دراية بالمنصة بالفعل)، ولكنه يضمن أيضاً أننا نلتقط تفضيلات الانطباع الأول الحقيقية من غالبية المشاركين.
اختيار الصوت
استخدمنا أفضل 500 صوت عام في المنصة للتجربة. تم استنساخ كل صوت في نظام المزود الخارجي مسبقاً، مما يضمن توفر نفس هوية الصوت المرجعي على كلا الجانبين.
المزودون والنماذج التي تم اختبارها
| المزود | النموذج | هدف التوجيه |
|---|---|---|
| Fish Audio | S2 Pro (الأحدث) | fish:s2-pro |
| Fish Audio | S1 (الجيل السابق) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
تغطية التقييم ودعم الوسوم
لا تدعم جميع الشركات المزودة نفس مجموعة الميزات. يدعم Fish Audio S2 Pro وسوم العروض الصوتي الغنية (مثل [laughs], [sighs]) ووسوم المتحدث (<|speaker:N|>) للمحتوى متعدد المتحدثين. هذا مهم لأن حركة مرور الإنتاج لدينا تتضمن طبيعياً نصوصاً موسومة.
- تلقى ElevenLabs V3 التقييم الأكثر اكتمالاً — فهو يدعم الوسوم العشوائية بعد تحويلها إلى شكل بين قوسين، لذا كان مؤهلاً لجميع الطلبات تقريباً بغض النظر عن المحتوى.
- ElevenLabs 2.5 Flash و Multilingual V2 — أرسلنا طلبات النص العادي فقط لهذه النماذج (بدون وسوم).
- Inworld — نص عادي فقط، ومقتصر على تنسيق مخرج
mp3، مما حد أكثر من حركة المرور المؤهلة له. - MiniMax — قبل وسوم الاعتراض (
(laughs),(sighs), إلخ) لكنه رفض أنواع الوسوم الأخرى. بسبب نتائج تفضيل المستخدم الضعيفة باستمرار، تم إيقاف التجربة مبكراً لتجنب المزيد من تدهور تجربة المستخدم.
التكلفة التي تحملناها
هذه التجارب ليست مجانية. واجهات برمجة تطبيقات TTS الخارجية مكلفة عند الاستخدام الواسع:
- ElevenLabs: تم إنفاق أكثر من 1,500 دولار على استدعاءات API.
- MiniMax: تم إنفاق 330 دولاراً (توقف مبكراً بسبب الأداء الضعيف).
- Inworld: تم إنفاق 170 دولاراً.

المنهجية الإحصائية
نموذج Bradley-Terry
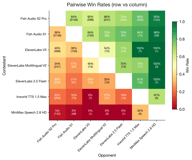
يمكن أن تكون معدلات الفوز الخام مضللة عندما تواجه نماذج مختلفة خصوماً مختلفين بترددات مختلفة. يحل نموذج Bradley-Terry ذلك عن طريق حساب درجة قوة عالمية من بيانات المقارنة الزوجية.
بالنسبة لنموذجين و بدرجات BT هما و :
فترات الثقة
نحن نبلغ عن فترات ثقة بوتستراب بنسبة 95% محسوبة من 200 عملية إعادة أخذ عينات من بيانات أزواج التفضيل.
النتائج حسب اللغة
لغات الأبجدية اللاتينية (الإنجليزية، الإسبانية، الفرنسية، الألمانية، ...)
تمثل اللغات المكتوبة بالأبجدية اللاتينية الجزء الأكبر بـ 4,173 زوج تفضيل.
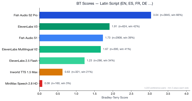
يتصدر Fish S2 Pro بنتيجة 3.05. والجدير بالذكر أن ElevenLabs V3 (1.90) يتفوق قليلاً على Fish S1 (1.72) في هذه الفئة — وهي المجموعة اللغوية الوحيدة التي يتفوق فيها أي منافس على نموذجنا القديم.
الصينية
تضم اللغة الصينية 329 زوج تفضيل وتظهر الهيمنة الأكثر دراماتيكية لـ Fish Audio.
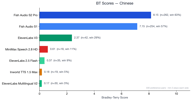
كلا نموذجي Fish Audio (S2 Pro بنتيجة 8.11، و S1 بنتيجة 7.11) يتفوقان بشكل هائل على جميع المنافسين.
اليابانية
تضم اللغة اليابانية 354 زوج تفضيل.
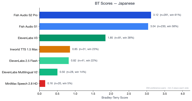
يتقارب Fish S2 Pro (3.12) و Fish S1 (3.02) للغاية، وكلاهما يتقدم بفارق كبير على ElevenLabs V3 (1.88).
محددات التجربة
استبعاد مستخدمي API
لضمان استقرار المنصة، لم يتم تضمين مستخدمي API في التجربة. ينطبق معدل أخذ العينات بنسبة 10% فقط على مستخدمي منصة الويب.
دعم الوسوم يخلق تغطية غير متكافئة
نظراً لأن المزودين الخارجيين لديهم مستويات دعم مختلفة للوسوم، فقد تلقوا مجموعات فرعية مختلفة من حركة المرور. وهذا يعني أن ساحة المنافسة ليست متكافئة تماماً.
قد تكون نتائج MiniMax غير موثوقة
سجل MiniMax Speech 2.8 HD نتيجة منخفضة للغاية. نحن نشك في أن تكامل MiniMax API الخاص بنا قد لا يكون مثالياً. إذا كانت MiniMax تعتقد أن هذه النتائج لا تعكس القدرة الحقيقية لنموذجها، فنحن نرحب بمراجعة تعاونية لتكاملنا.
الخاتمة
نعتقد أن هذا هو أحد أكثر التقييمات العامة صرامة لجودة TTS التي أجريت على الإطلاق:
- مستخدمون حقيقيون، وليسوا مقيمين مدفوعي الأجر.
- مقارنة عمياء — لا يعرف المستخدمون أبداً المزود الذي أنتج الصوت.
- إشارة سلوكية (التحميل) بدلاً من التقييمات الذاتية.
- أكثر من 5,000 زوج تفضيل عبر لغات متعددة.
النتائج واضحة: Fish Audio S2 Pro هو نموذج TTS المفضل في جميع اللغات المختبرة، مع مزايا قوية بشكل خاص في الصينية واليابانية. حتى نموذج S1 من الجيل السابق يتفوق على كل منافس في المجموع الكلي.
تؤكد هذه النتائج صحة خارطة طريقنا نحو النمذجة من طرف إلى طرف (end-to-end) و التعلم التعزيزي من ردود فعل البشر (RLHF).
أجرى فريق Fish Audio هذا التقييم في الفترة من 26 مارس إلى 5 أبريل 2026. للاستفسارات أو لمناقشة المنهجية، تواصل معنا عبر fish.audio.









