Fish Audio تطلق نموذج S2 مفتوح المصدر: تحكم دقيق يلبي متطلبات البث المباشر للإنتاج
9 مارس 2026
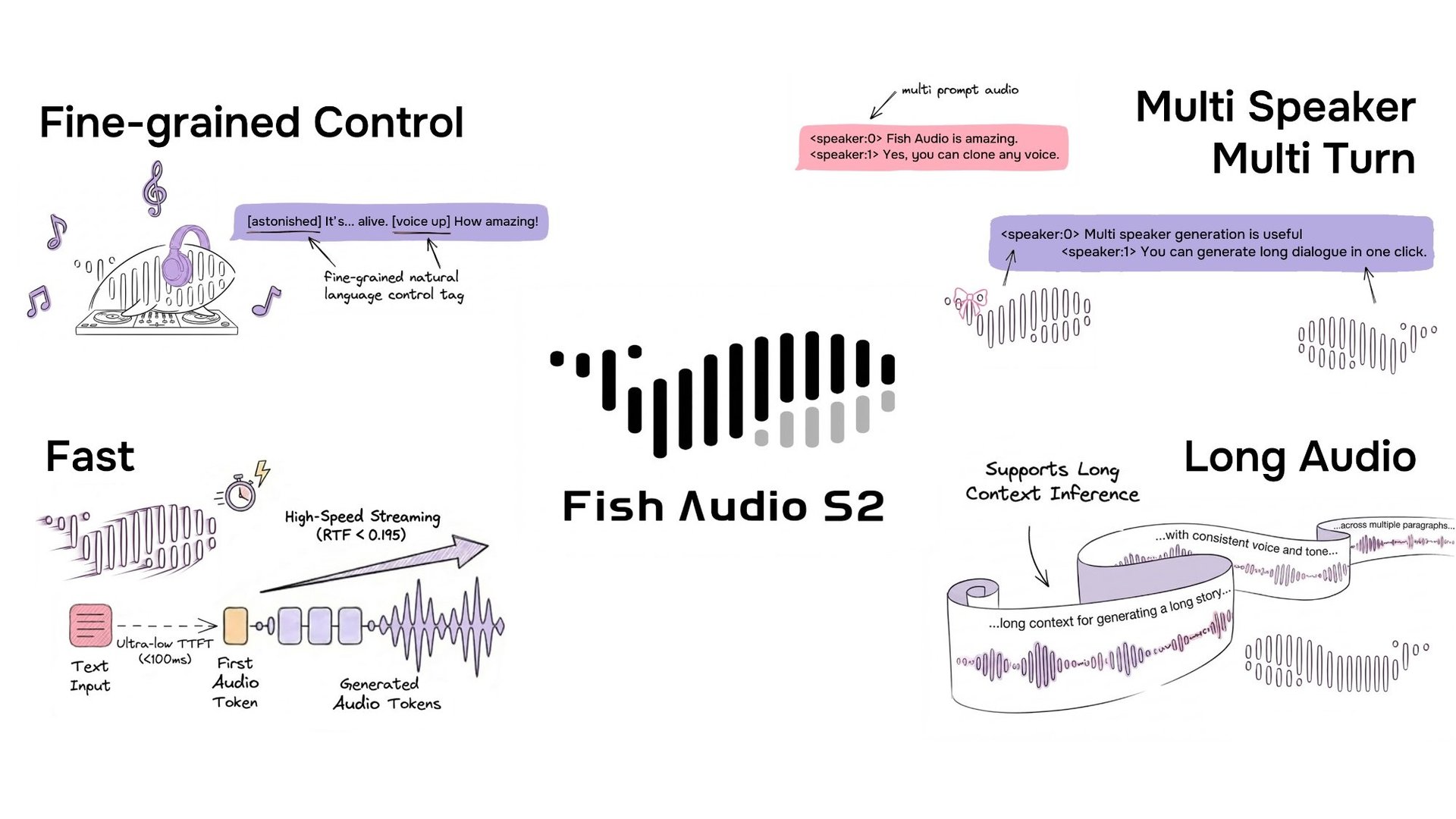
يتوفر S2 Pro على تطبيق Fish Audio وتتوفر نسخته مفتوحة المصدر عبر مستودع GitHub الخاص بالمشروع و HuggingFace.
أطلقت Fish Audio نموذج S2، وهو نموذج لتحويل النص إلى كلام يدعم التحكم الدقيق والمضمن في التنغيم والعاطفة باستخدام وسوم اللغة الطبيعية مثل [laugh] و [whispers] و [super happy]. تم تدريب النظام على أكثر من 10 ملايين ساعة من الصوت عبر ما يقرب من 50 لغة، ويجمع النظام بين مواءمة التعلم المعزز وبنية الانحدار الذاتي المزدوجة (dual-autoregressive). يتضمن الإصدار أوزان النموذج، وأكواد الضبط الدقيق (fine-tuning)، ومحرك استدلال للبث المباشر يعتمد على SGLang.
التحكم الدقيق المضمن عبر اللغة الطبيعية
يتيح S2 التحكم المضمن في توليد الكلام من خلال تضمين تعليمات اللغة الطبيعية مباشرة في مواضع كلمات أو عبارات محددة داخل النص. وبدلاً من الاعتماد على مجموعة ثابتة من الوسوم المحددة مسبقاً، يقبل S2 أوصافاً نصية حرة — مثل [whisper in small voice] أو [professional broadcast tone] أو [pitch up] — مما يسمح بالتحكم المفتوح في التعبير على مستوى الكلمة.
في اختبار Audio Turing Test، حقق S2 متوسطاً لاحقاً قدره 0.515 مع إعادة كتابة التعليمات، مقارنة بـ 0.417 لنموذج Seed-TTS و 0.387 لنموذج MiniMax-Speech. وفي معيار EmergentTTS-Eval، وصل إلى معدل فوز إجمالي قدره 81.88% مقابل خط الأساس gpt-4o-mini-tts — وهو الأعلى بين جميع النماذج التي تم تقييمها، بما في ذلك الأنظمة مغلقة المصدر من Google و OpenAI.
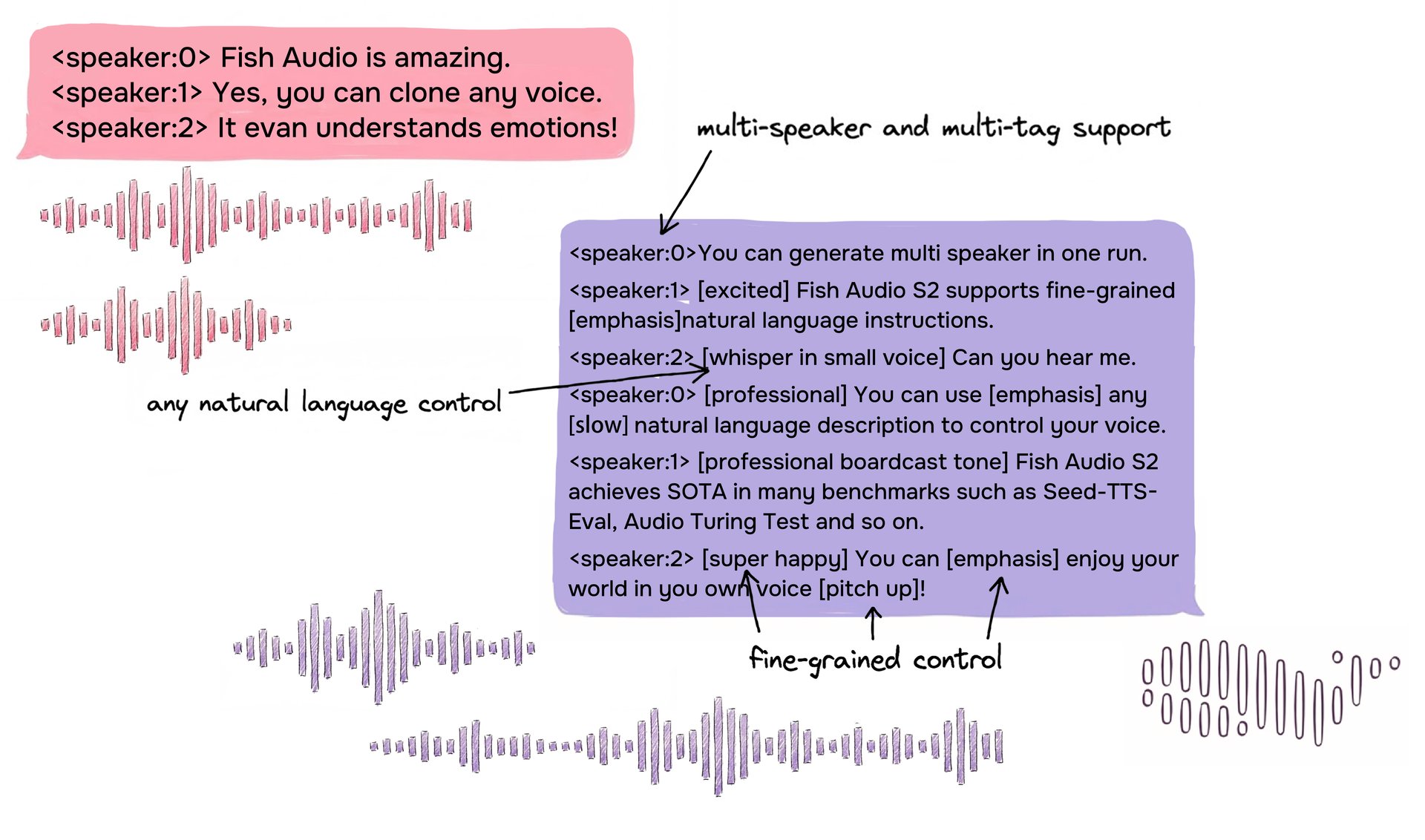 مثال على تنسيق إدخال S2 يوضح حواراً متعدد المتحدثين مع وسوم مضمنة بلغة طبيعية حرة للتحكم الدقيق.
مثال على تنسيق إدخال S2 يوضح حواراً متعدد المتحدثين مع وسوم مضمنة بلغة طبيعية حرة للتحكم الدقيق.
وصفة موحدة: تنقية البيانات ومكافآت التعلم المعزز من نفس النماذج
يتمثل أحد القرارات المعمارية الأساسية في S2 في إعادة استخدام نفس النماذج المستخدمة لتصفية وتصنيف بيانات التدريب مباشرة كنماذج مكافأة (reward models) أثناء التعلم المعزز:
- نموذج جودة الكلام: يقوم بتقييم الصوت عبر أبعاد مثل نسبة الإشارة إلى الضوضاء (SNR)، واتساق المتحدث، والوضوح أثناء تصفية البيانات — ثم يعمل كمكافأة للتفضيل الصوتي أثناء التعلم المعزز.
- نموذج ASR للنسخ الغني: (الذي تمت مواصلة تدريبه مسبقاً من Qwen3-Omni-30B-A3B) يولد نصوصاً معززة بالأوصاف مع تعليقات لغوية مضمنة أثناء معالجة البيانات — ثم يوفر مكافأة الوضوح واتباع التعليمات عن طريق إعادة نسخ الصوت المولد ومقارنته بالمطالبة الأصلية.
يقضي هذا التصميم مزدوج الغرض على عدم التطابق في التوزيع بين بيانات ما قبل التدريب وأهداف ما بعد التدريب — وهي مشكلة لا تزال غير معالجة في أنظمة TTS الأخرى التي تدرب نماذج المكافأة بشكل منفصل عن خطوط أنابيب البيانات الخاصة بها.
نظرة داخل النموذج: بنية Dual-AR
يعتمد S2 على محول (transformer) مخصص لفك التشفير فقط مدمج مع ترميز صوتي يعتمد على RVQ (10 كتب رموز، معدل إطارات ~21 هرتز). إن تسوية جميع كتب الرموز عبر الزمن قد يؤدي إلى انفجار في طول التسلسل بمقدار 10 أضعاف. يعالج S2 ذلك ببنية الانحدار الذاتي المزدوج (Dual-AR):
- Slow AR: يعمل على طول المحور الزمني ويتنبأ بكتاب الرموز الدلالي الأساسي.
- Fast AR: يولد كتب الرموز التسعة المتبقية في كل خطوة زمنية، مما يعيد بناء التفاصيل الصوتية الدقيقة.
يحافظ هذا التصميم غير المتماثل — 4 مليارات معلمة على طول المحور الزمني، و 400 مليون معلمة على طول محور العمق — على كفاءة الاستدلال مع الحفاظ على دقة الصوت.
مواءمة التعلم المعزز للكلام
بالنسبة لمرحلة ما بعد التدريب، يستخدم S2 تحسين السياسة النسبية للمجموعة (GRPO)، والذي تم اختياره لتجنب الأعباء الذاكرية لنماذج القيمة بأسلوب PPO في سياقات الصوت الطويلة. تجمع إشارة المكافأة بين أبعاد متعددة، تشمل:
- الدقة الدلالية والالتزام بالتعليمات
- تقييم التفضيل الصوتي
- تشابه جرس الصوت (Timbre)
نتائج الاختبارات المعيارية
حقق S2 نتائج رائدة عبر العديد من الاختبارات المعيارية العامة:
| الاختبار المعياري | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (الصينية) | 0.54% (الأفضل إجمالاً) |
| Seed-TTS Eval — WER (الإنجليزية) | 0.99% (الأفضل إجمالاً) |
| Audio Turing Test (مع التعليمات) | 0.515 (المتوسط اللاحق) |
| EmergentTTS-Eval — معدل الفوز | 81.88% (الأعلى إجمالاً) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — الجودة | 4.51 / 5.0 |
| Multilingual (MiniMax Testset) — أفضل WER | في 11 من أصل 24 لغة |
| Multilingual (MiniMax Testset) — أفضل SIM | في 17 من أصل 24 لغة |
في اختبار Seed-TTS Eval، حقق S2 أقل معدل لخطأ الكلمات (WER) بين جميع النماذج التي تم تقييمها بما في ذلك الأنظمة مغلقة المصدر: Qwen3-TTS (0.77/1.24)، MiniMax Speech-02 (0.99/1.90)، Seed-TTS (1.12/2.25). وفي اختبار Audio Turing Test، تفوق رقم 0.515 على Seed-TTS (0.417) بنسبة 24% وعلى MiniMax-Speech (0.387) بنسبة 33%. وفي معيار EmergentTTS-Eval، حقق S2 نتائج قوية بشكل خاص في اللغويات الموازية (معدل فوز 91.61%)، والأسئلة (84.41%)، والتعقيد النحوي (83.39%).
البث المباشر للإنتاج عبر SGLang
نظراً لأن بنية Dual-AR في S2 متماثلة هيكلياً مع نماذج اللغة الكبيرة (LLMs) القياسية ذات الانحدار الذاتي، يمكنها أن ترث مباشرة جميع تحسينات الخدمة الأصلية لنماذج اللغة من SGLang مع الحد الأدنى من التعديل — بما في ذلك الدفعات المستمرة (continuous batching)، وذاكرة التخزين المؤقت للـ KV المقسمة لصفحات (paged KV cache)، وإعادة تشغيل رسوم CUDA البيانية، والتخزين المؤقت للبادئة القائم على RadixAttention.
من أجل استنساخ الصوت، يضع S2 رموز الصوت المرجعية في مطالبة النظام. يقوم نظام RadixAttention في SGLang تلقائياً بتخزين حالات KV هذه، محققاً متوسط معدل إصابة لذاكرة التخزين المؤقت للبادئة بنسبة 86.4% (أكثر من 90% في الذروة) عند إعادة استخدام نفس الصوت عبر الطلبات — مما يجعل العبء الإضافي للملء المسبق للصوت المرجعي لا يكاد يذكر.
على وحدة معالجة رسومات NVIDIA H200 واحدة:
- معامل الوقت الحقيقي (RTF): 0.195
- الوقت حتى أول صوت: حوالي 100 مللي ثانية
- القدرة الإنتاجية: أكثر من 3000 رمز صوتي في الثانية مع الحفاظ على RTF أقل من 0.5
لماذا يعد هذا الإصدار مهماً؟
لم يتم إصدار S2 كنقطة فحص للنموذج فحسب، بل كنظام متكامل: أوزان النموذج، وأكواد الضبط الدقيق، ومجموعة أدوات استدلال جاهزة للإنتاج.
هناك خياران في التصميم يبرزان بشكل خاص. أولاً، يلغي خط أنابيب البيانات والمكافأة الموحد مشكلة هيكلية — وهي عدم التطابق في التوزيع بين مرحلة ما قبل التدريب والتعلم المعزز — والتي لم تعالجها أنظمة TTS الأخرى على المستوى المعماري. ثانياً، يعني التماثل الهيكلي بين بنية Dual-AR ونماذج اللغة الكبيرة القياسية أن S2 يمكنه الاستفادة من النظام البيئي الكامل لتحسينات خدمة نماذج اللغة الكبيرة، بدلاً من طلب بنية تحتية مخصصة للاستدلال.
يتوفر S2 عبر مستودع GitHub الخاص بالمشروع، و SGLang-Omni، و HuggingFace، وعبر تجربة تفاعلية على fish.audio.



