Fish Audio S2! تحكم دقيق في صوت الذكاء الاصطناعي على مستوى الكلمة

يوفر Fish Audio S2 وسومًا مضمنة مفتوحة المجال، وتحكمًا في صوت الذكاء الاصطناعي على مستوى الكلمة، ودعمًا لـ 80 لغة لتحويل النص إلى كلام (TTS) تعبيري. تعرّف على كيفية عمله من خلال أمثلة واقعية.
مارس 2026 | Fish Audio S2 متاح الآن
جدول المحتويات
-
ما هو Fish Audio S2؟
-
ما يمكن لـ S2 فعله — في 30 ثانية
-
الوسوم المضمنة في Fish Audio S2
-
أمثلة واقعية
-
أداء S2 — نتائج الاختبارات المعيارية
-
80 لغة
-
المصدر المفتوح
-
كيفية البدء
-
الأسئلة الشائعة
تمنحك معظم أدوات الصوت التي تعمل بالذكاء الاصطناعي صوتًا وتسمح لك بضبط الحالة المزاجية على المستوى العام — أكثر هدوءًا، أو أكثر نشاطًا، أو أكثر دفئًا قليلاً. يتخذ Fish Audio S2 نهجًا مختلفًا لتحويل النص إلى كلام التعبيري. أنت توجه الصوت على مستوى الكلمة، بلغة بسيطة، مباشرة داخل النص الخاص بك. إذا كنت معتادًا على وسوم العاطفة في Fish Audio S1، فإن S2 يوسع هذه الفكرة بشكل كبير من خلال التحكم المضمن مفتوح المجال.
إليك كيف يبدو ذلك من الناحية العملية:
I thought I was ready. [voice breaking] I wasn't.
[soft voice] Take your time. There's no rush.
That was the third time this week. [sigh] I really need to fix that.
لا توجد لوحات إعدادات. لا يوجد SSML. لا توجد عمليات إنتاج فني بعد التسجيل. أنت تكتب التوجيه داخل النص، ويقوم S2 بتنفيذه.
ملخص سريع
يقدم Fish Audio S2 وسومًا مضمنة للتحكم في تحويل النص إلى كلام (TTS) التعبيري على مستوى الكلمة.
-
وسوم مفتوحة المجال مكتوبة بلغة طبيعية — لا توجد قائمة كلمات ثابتة
-
وضع الوسوم في منتصف الجملة لتوقيت دقيق وتغييرات في الأداء
-
دعم لحوالي 80 لغة
-
أوزان نماذج مفتوحة المصدر، كود الضبط الدقيق، ومجموعة أدوات الاستدلال
بدلاً من ضبط إعدادات الصوت العامة، يتيح لك S2 توجيه الأداء مباشرة داخل النص الخاص بك.
ما هو Fish Audio S2؟
https://www.youtube.com/watch?v=NIcXTOSdOXc
Fish Audio S2 هو الجيل الثاني من نموذج TTS من Fish Audio. تم تدريبه على أكثر من 10 ملايين ساعة من الصوت عبر حوالي 80 لغة، ويقدم التحكم في الوسوم المضمنة: تعليمات باللغة الطبيعية مدمجة مباشرة في النص الخاص بك في أي موضع، مما يمنحك توجيهًا دقيقًا حول كيفية أداء الكلام على مستوى الكلمة أو العبارة.
النموذج مفتوح المصدر على GitHub و HuggingFace، وهو متاح عبر واجهة برمجة تطبيقات (API) Fish Audio والتطبيق (APP).
ما يمكن لـ S2 فعله — في 30 ثانية
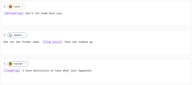
الوسوم المضمنة في S2 هي تعليمات بين قوسين مربعين توضع في أي مكان في نصك:
[whispering] Don't let them hear you.
She set the folder down. [long pause] Then she looked up.
[laughing] I have absolutely no idea what just happened.
تؤثر الوسوم على ما يأتي بعدها. ضع الوسم في النقطة الدقيقة التي يجب أن يحدث فيها التحول — وليس في بداية الجملة إلا إذا كان هذا هو المكان الذي تريده فيه.
أنت لا تختار من قائمة ثابتة. أنت تكتب الوصف، ويقوم S2 بتفسيره:
[the calm, measured tone of someone who has done this a thousand times]
Please place your hands where I can see them.
[overly cheerful, clearly forcing it]
Everything is completely fine. Totally fine.
إذا كان بإمكانك وصفه لمؤدٍ صوتي، فيمكن لـ S2 محاولة القيام به.
الوسوم المضمنة في Fish Audio S2
الوسوم المضمنة هي آلية التحكم الأساسية في Fish Audio S2. إنها تعليمات باللغة الطبيعية داخل [أقواس مربعة] تدمجها مباشرة في النص لتوجيه كيفية أداء الكلام — عند أي كلمة، وفي أي نقطة.
بنية الجملة
ضع وسمًا داخل [أقواس مربعة] مباشرة قبل الكلمة أو العبارة التي يجب أن يؤثر عليها. يمكن للوسوم أن توضع في أي مكان — في البداية، المنتصف، أو نهاية الجملة.
[whispering] I didn't want to go inside.
I didn't want to go [whispering] inside.
كلاهما يعمل. الأول يهمس السطر بالكامل. والثاني يهمس من كلمة "inside" وما يليها. الموضع هو المعنى.
اكتب الوسوم بلغتك
لا يشترط أن تكون الوسوم باللغة الإنجليزية. يفهم S2 تعليمات اللغة الطبيعية عبر 80 لغة — لذا يمكنك كتابة الوسوم بنفس لغة النص الخاص بك.
日本語 (اليابانية)
[囁き声で] 誰にも聞かせないで。
[ため息をついて] もう一度やり直そう。
中文 (الصينية)
[低声说] 不要让他们听见。
[叹气] 我真的不知道该怎么办了。
español (الإسبانية)
[susurrando] No dejes que te escuchen.
[enojado] ¿Cómo pudiste hacer eso?
한국어 (الكورية)
[속삭이며] 아무도 모르게 해줘.
[화나서] 어떻게 그럴 수가 있어.
تنطبق نفس القاعدة: ضع الوسم مباشرة قبل الكلمة أو العبارة التي يجب أن يؤثر عليها، وبأي لغة تبدو طبيعية لنصك.
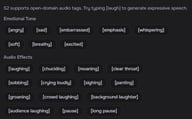
وسوم تم اختبارها جيدًا
يقبل S2 أي وصف باللغة الطبيعية، ولكن هذه الوسوم تعطي نتائج قوية باستمرار بشكل مباشر. تُطبق الوسوم من النقطة التي تظهر فيها حتى الوسم التالي أو نهاية الجملة.
التنفس وردود الفعل
الأصوات الصوتية
سرعة الإيقاع
نمط الصوت
العاطفة
أخرى
أوصاف حرة
بالإضافة إلى قائمة الوسوم أعلاه، يقبل S2 أوصافًا مفتوحة. اكتب ما قد تقوله لمؤدٍ صوتي:
[speaking slowly, almost hesitant]
[professional broadcast tone]
[dead tired, end of a very long shift]
[pitch up]
[voice rough from crying, trying to sound normal]
نظرًا لأن S2 مدرب على أوصاف مفتوحة، فإن الوسوم الجديدة يتم تعميمها جيدًا — فأنت لست مقيدًا بالأمثلة التي شوهدت أثناء التدريب.
دمج الوسوم
اربط الوسوم عبر مقطع ما لإنشاء تحولات في الأداء:
[soft voice] I wasn't sure what to say. [long pause] [loud voice] But then it hit me.
استخدم وسوم رد الفعل بين الجمل لإنشاء انتقالات طبيعية:
That was the third time this week. [sigh] I really need to fix that.
يؤدي دمج رد فعل مع وسم عاطفة إلى ترسيخ الشعور جسديًا:
[sigh] [sad] I just don't know anymore.
أمثلة واقعية
سرد الكتب الصوتية
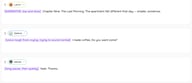
[NARRATOR, low and slow] Chapter Nine. The Last Morning. The apartment felt different that day — smaller, somehow.
SARAH: [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
DANIEL: [long pause, then quietly] Yeah. Thanks.
بودكاست

Today we're looking at something I've spent three months trying to understand.
[chuckling] I kept getting it wrong. My producer will confirm this.
حوار الألعاب
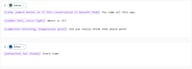
VILLAIN: [calm, almost bored, as if this conversation is beneath them] You came all this way.
VILLAIN: [sudden fury, voice tight] Where is it?
VILLAIN: [composure returning, dangerously quiet] Did you really think that would work?
HERO: [exhausted, but steady] Every time.
وكيل صوتي

[friendly, warm] Hi — thanks for calling. How can I help you today?
[empathetic, unhurried] I'm sorry to hear that. Let me pull this up.
[confident] Good news — I can see exactly what happened, and I'm going to get this sorted for you right now.
نصائح للحصول على أفضل النتائج
الوسوم المضمنة في S2 تعبيرية، لكن مدى ظهورها يعتمد على كيفية استخدامك لها — ومع أي صوت تعمل. هذه النصائح مبنية على اختبارات عملية.

اجمع بين الوسوم الجسدية ووسم العاطفة. وسوم مثل [panting] (لهث)، و [whispering] (همس)، و [shouting] (صراخ) ستظهر من تلقاء نفسها، لكن التأثير قد يبدو باهتًا بدون سياق عاطفي. دمجها مع وسم عاطفة ينتج نتائج أكثر اتساقًا وطبيعية:
[panting] [tired] I've been running for twenty minutes.
[whispering] [scared] Don't move. Don't make a sound.
[shouting] [angry] I told you this would happen!

اتبع دائمًا الوسم الوصفي بنص. الوسم الوصفي مثل [voice rough from crying, trying to sound normal] يحتاج إلى سطر ليتم نطقه — لا تتركه بمفرده. يوجه الوسم أداء ما يليه؛ بدون نص بعده، قد تكون المخرجات غير متوقعة.
✅ [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
❌ [voice rough from crying, trying to sound normal]
اختبر صوتك قبل كتابة النص. تستجيب الأصوات المختلفة لنفس الوسم بكثافة مختلفة. الصوت ذو السجل الهادئ بطبيعته سيظهر تغييرات أدق من الصوت التعبيري. إذا لم يحقق الوسم النتيجة المتوقعة، فجرب صوتًا مختلفًا قبل تعديل الوسم نفسه — فالمشكلة غالبًا ما تكون في الصوت، وليس في التعليمات.
ابدأ بالبساطة، ثم أضف الطبقات. يمكن لوسم واحد موضوع بعناية مثل [sigh] أو [long pause] أن يغير السطر تمامًا. أضف المزيد من الوسوم فقط عندما لا تكون النسخة الأبسط كافية. كثرة الوسوم قد تتعارض مع بعضها البعض.
قريبًا: اختر المفضل لديك من عدة أجيال. سيدعم S2 إنشاء عدة نسخ من نفس السطر في وقت واحد، حتى تتمكن من المقارنة واختيار الأداء الذي يناسبك أكثر — بشكل مشابه لكيفية اختيارك من مجموعة في أدوات توليد الصور. سيجعل هذا من السهل جدًا الوصول للأداء الصحيح دون تعديل الوسوم يدويًا في كل مرة.
أداء S2 — نتائج الاختبارات المعيارية
التحكم المضمن في S2 ليس مجرد ميزة في تجربة المستخدم — بل يرتبط أيضًا بأداء قوي في اختبارات الكلام المعيارية العامة. تقيس هذه الاختبارات طبيعية الكلام، ودقة النطق، والقدرة على اتباع التعليمات عبر أنظمة TTS الحديثة.
في اختبار Audio Turing Test، سجل S2 درجة 0.515 — متفوقًا على Seed-TTS بنسبة 24% و MiniMax-Speech بنسبة 33%. في EmergentTTS-Eval، حقق نتائج قوية بشكل خاص في لغويات التوازي (معدل فوز 91.61%)، وهو ما يعكس بشكل مباشر جودة تنفيذ الوسوم المضمنة.
في Seed-TTS Eval، حقق S2 أقل معدل لخطأ الكلمات بين جميع النماذج التي تم تقييمها بما في ذلك الأنظمة مغلقة المصدر: Qwen3-TTS (0.77% / 1.24%)، و MiniMax Speech-02 (0.99% / 1.90%)، و Seed-TTS (1.12% / 2.25%).
المصدر: منشور إطلاق Fish Audio S2 بقلم شيجيا لياو، كبير العلماء
80 لغة
تم تدريب S2 على أكثر من 10 ملايين ساعة من الصوت تغطي حوالي 80 لغة. في مجموعة اختبار MiniMax متعددة اللغات التي تغطي 24 لغة، حقق S2 أفضل معدل خطأ في الكلمات في 11 لغة وأفضل تشابه للمتحدث في 17 لغة — متفوقًا على كل من MiniMax و ElevenLabs في غالبية الاختبارات المعيارية.
تشمل اللغات ذات الأداء القوي المؤكد: العربية، والكانتونية، والصينية، والتشيكية، والهولندية، والإنجليزية، والفنلندية، والفرنسية، والألمانية، واليونانية، والهندية، والإندونيسية، والإيطالية، واليابانية، والكورية، والبولندية، والبرتغالية، والرومانية، والروسية، والإسبانية، والتايلاندية، والتركية، والأوكرانية، والفيتنامية.
المصدر المفتوح
على عكس معظم أنظمة TTS التجارية، فإن Fish Audio S2 مفتوح المصدر بالكامل — أوزان النماذج، وكود الضبط الدقيق، ومحرك استدلال جاهز للإنتاج يعتمد على SGLang — مما يسمح للمطورين بالاستضافة الذاتية والضبط الدقيق والنشر على نطاق واسع.
-
GitHub: github.com/fishaudio/fish-speech
-
HuggingFace: huggingface.co/fishaudio/s2-pro
-
استدلال SGLang: SGLang-Omni
أداء الإنتاج على وحدة معالجة رسومات H200 واحدة:
-
عامل الوقت الفعلي (Real-Time Factor): 0.195
-
الوقت المستغرق لأول صوت: ~100 مللي ثانية
-
الإنتاجية: أكثر من 3000 رمز صوتي في الثانية
لاستنساخ الصوت على نطاق واسع، يضع S2 رموز الصوت المرجعية في موجه النظام (system prompt). يحقق التخزين المؤقت لـ KV في SGLang متوسط معدل نجاح لذاكرة التخزين المؤقت البادئة يبلغ 86.4% عند إعادة استخدام نفس الصوت عبر الطلبات — مما يجعل العبء المتكرر لاستنساخ الصوت ضئيلاً للغاية.
كيفية البدء
-
جربه في ساحة تجربة التطبيق — يدعم fish.audio وسوم S2 المضمنة مباشرة. ضع
[أقواس مربعة]في أي مكان في نصك وقم بالتوليد. -
الدمج عبر واجهة برمجة التطبيقات (API) — متاح عبر Fish Audio API. راجع مرجع API لمعرفة النقاط الطرفية والتحقق من الهوية.
-
استضف النموذج بنفسك — الأوزان ومجموعة الاستدلال مفتوحة المصدر على GitHub و HuggingFace.
-
قريبًا: توليد حوار متعدد المتحدثين في تطبيق وواجهة برمجة تطبيقات Fish Audio.
-
للحصول على دليل كامل حول بنية الوسوم المضمنة، وقواعد وضعها، والنصائح: ← كيفية استخدام وسوم Fish Audio S2 المضمنة
-
القادمون من S1 ويريدون فهم كيفية ارتباط النظامين: ← وسوم العاطفة في Fish Audio S1 — الدليل الكامل
الأسئلة الشائعة
ما هي الوسوم المضمنة في TTS؟
الوسوم المضمنة هي تعليمات قصيرة مدمجة مباشرة في نص تحويل النص إلى كلام للتحكم في كيفية نطق كلمة أو عبارة معينة — الأداء، أو العاطفة، أو الإيقاع، أو جودة الصوت في تلك النقطة بالضبط. على عكس إعدادات الصوت العامة التي تنطبق على الجيل بأكمله، تتيح لك الوسوم المضمنة توجيه لحظات فردية داخل السطر. يستخدم Fish Audio S2 [أقواس مربعة] للوسوم المضمنة ويقبل أوصافًا حرة باللغة الطبيعية.
ما هو Fish Audio S2؟
Fish Audio S2 هو الجيل الثاني من نموذج TTS من Fish Audio. يدعم التحكم المضمن الدقيق عبر وسوم باللغة الطبيعية داخل [أقواس مربعة] توضع في أي مكان في النص، وهو مدرب على أكثر من 10 ملايين ساعة من الصوت عبر حوالي 80 لغة. إنه مفتوح المصدر على GitHub و HuggingFace، ومتاح عبر API وتطبيق Fish Audio.
كيف تعمل الوسوم المضمنة في S2؟
ضع وسمًا داخل [أقواس مربعة] مباشرة قبل الكلمة أو العبارة التي يجب أن يؤثر عليها. يمكنك استخدام وسوم تم اختبارها جيدًا مثل [whispering]، أو [sigh]، أو [long pause]، أو كتابة أي وصف حر باللغة الطبيعية. تُطبق الوسوم على كل ما يليها حتى الوسم التالي أو نهاية الجملة.
هل Fish Audio S2 مفتوح المصدر؟
نعم. أوزان النماذج، وكود الضبط الدقيق، ومحرك الاستدلال المستند إلى SGLang مفتوحة المصدر على github.com/fishaudio/fish-speech و huggingface.co/fishaudio/s2-pro
كم عدد اللغات التي يدعمها S2؟
تم تدريب S2 على حوالي 80 لغة. في اختبار معياري متعدد اللغات لـ 24 لغة، حقق S2 أفضل معدل خطأ في الكلمات في 11 لغة وأفضل تشابه للمتحدث في 17 لغة، متفوقًا على MiniMax و ElevenLabs.
هل يدعم S2 بنية الأقواس الهلالية () الخاصة بـ S1؟
لا. يستخدم S2 [الأقواس المربعة] بشكل أصلي. تقوم واجهة مستخدم ويب Fish Audio بترجمة () تلقائيًا إلى [] عند تحديد S2، ولكن إذا كنت تستخدم API مباشرة، فاستخدم الأقواس المربعة.
هل يدعم S2 حوارات المتحدثين المتعددين؟
توليد الحوار متعدد المتحدثين قادم قريبًا إلى تطبيق وواجهة برمجة تطبيقات Fish Audio. النموذج يدعم ذلك بشكل أصلي — ترقبوا الإطلاق.
ما الفرق بين Fish Audio S1 و S2؟
يستخدم S1 مفردات ثابتة من وسوم العاطفة المحددة مسبقًا داخل (أقواس هلالية)، توضع في بداية الجمل. يستخدم S2 وسوم لغة طبيعية مفتوحة المجال داخل [أقواس مربعة] يمكن أن تظهر في أي مكان في النص — في منتصف الجملة، بين الكلمات، أو في البداية. كما يقبل S2 أوصافًا حرة بدلاً من قائمة كلمات رئيسية مغلقة، لذا فأنت لست مقيدًا بعواطف محددة مسبقًا. للحصول على تفصيل كامل، راجع دليل وسوم العاطفة لـ Fish Audio S1.
هل يمكن لـ Fish Audio S2 أن يحل محل SSML؟
بالنسبة لمعظم حالات الاستخدام التعبيري، نعم. يمكن لـ Fish Audio S2 محاكاة العديد من عناصر التحكم بأسلوب SSML من خلال وسوم مضمنة باللغة الطبيعية — بدلاً من وسم XML مثل <prosody rate="slow"> ، تكتب [speaking slowly] مباشرة في النص. تغطي وسوم مثل [whispering] و [long pause] و [angry] أكثر الوظائف التعبيرية شيوعًا في SSML دون الحاجة إلى معرفة متخصصة بلغة الترميز.
هل وسوم Fish Audio S2 المضمنة متوافقة مع أنظمة TTS الأخرى؟
لا. بنية الوسوم المضمنة في Fish Audio S2 خاصة بهذا النموذج. تستخدم أنظمة TTS الأخرى SSML أو تنسيقاتها الخاصة. ومع ذلك، فإن المفاهيم التعبيرية الأساسية — التوقفات، وتغير النغمات، والإشارات الصوتية — تُترجم من حيث المفهوم عند الانتقال بين الأنظمة، حتى لو اختلفت طريقة الكتابة.
موارد ذات صلة:

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
اقرأ المزيد من Sabrina Shu






