تحويل النص إلى كلام بأصوات متعددة — الدليل الشامل للمتحدثين المتعددين (Fish Audio)

إن تحويل النص إلى كلام (TTS) بصوت واحد يبدو رتيباً في الحوارات، والكتب الصوتية، والبودكاست. يوضح لك هذا الدليل كيفية العثور على الأصوات وتنظيمها في Fish Audio، ثم استخدام ميزة المتحدثين المتعددين في TTS و Story Studio لإنتاج صوت طبيعي متعدد الشخصيات — دون الحاجة إلى سير عمل تسجيل الصوت التقليدي.
مارس 2026 | ميزة تحويل النص إلى كلام لمتحدثين متعددين من Fish Audio متاحة الآن على S2 Pro
جدول المحتويات
- ما هو تحويل النص إلى كلام لمتحدثين متعددين؟
- الخطوة 1 — ابحث عن الأصوات المناسبة باستخدام Discovery
- الخطوة 2 — المتحدثون المتعددون في تحويل النص إلى كلام (TTS)
- الخطوة 3 — المتحدثون المتعددون في Story Studio
- TTS مقابل Story Studio — أيهما يجب أن تستخدم؟
- حالات الاستخدام — ماذا يمكنك أن تصنع باستخدام ميزة المتحدثين المتعددين؟
- من النص إلى الصوت — في جلسة واحدة
- الأسئلة الشائعة حول تحويل النص إلى كلام لمتحدثين متعددين
تمنحك معظم أدوات تحويل النص إلى كلام صوتاً واحداً. راوٍ واحد. نبرة واحدة، من البداية إلى النهاية. بالنسبة لشرح بصوت متحدث واحد، قد يكون ذلك جيداً. ولكن في اللحظة التي يتضمن فيها نصك شخصيتين تتحدثان، أو مضيفاً وضيفاً، أو قصة بأدوار متميزة — فإن الصوت الواحد يحول الحوار إلى قراءة مسطحة ورتيبة. وينصرف المستمعون بسرعة.
إن تحويل النص إلى كلام بأصوات متعددة يحل هذه المشكلة. حيث يمكنك تخصيص صوت ذكاء اصطناعي مختلف لكل متحدث، والتحكم في التوقيت بينهم، والنتيجة هي محادثة تبدو حقيقية. تعمل منصة Fish Audio كمولد حوار متكامل لتحويل النص إلى كلام — حيث تغطي كل شيء من اكتشاف الصوت إلى تصدير الفصول المتعددة. يرشدك هذا الدليل خلال سير العمل الكامل: كيفية اكتشاف الأصوات وتنظيمها، وكيفية استخدام ميزة المتحدثين المتعددين في أداة تحويل النص إلى كلام للمحتوى الأقصر، وكيفية التوسع إلى إنتاجات كاملة في Story Studio.
ما هو تحويل النص إلى كلام لمتحدثين متعددين؟
تحويل النص إلى كلام لمتحدثين متعددين هو سير عمل TTS حيث يتم تخصيص أجزاء مختلفة من النص لأصوات ذكاء اصطناعي مختلفة — لكل منها نبرتها وجنسها وعمرها وأسلوب حديثها الخاص — ثم يتم توليدها كمخرجات صوتية واحدة ومستمرة.
تعتمد أدوات TTS التقليدية على نموذج سرد واحد: صوت واحد، إدخال نص واحد، ملف صوتي واحد. هذا التصميم يعمل لسرد الكتب الصوتية براوٍ واحد، أو التعليقات الصوتية، أو الإعلانات. ولكنه يفشل تماماً في أي شيء يتضمن حواراً. لإنتاج محادثة بين شخصيتين باستخدام الأدوات القديمة، ستحتاج إلى توليد كل متحدث على حدة، ثم دمج الصوت يدوياً في محرر — مع ضبط التوقيت، ومطابقة مستويات الصوت، والأمل في ألا تبدو الانتقالات وكأنها تسجيلان مختلفان.
المشكلة ليست فقط في الخطوات الإضافية. بل في أن التوقيت بين المتحدثين يكاد يكون من المستحيل ضبطه بشكل صحيح بدون عناصر تحكم مخصصة. للمحادثة الحقيقية إيقاع: لحظة صمت قبل الرد، تداخل طفيف عند المقاطعة، وقفة أطول قبل إجابة صعبة. وبدون التحكم الدقيق في الفجوات بين المتحدثين، حتى الحوار المختار جيداً سيبدو آلياً.
تعالج أدوات TTS للمتحدثين المتعددين كلتا المشكلتين. يحصل كل متحدث على صوته الخاص وكتلة النص الخاصة به. الفجوات بين المتحدثين قابلة للتعديل. والمخرج النهائي هو ملف صوتي واحد متماسك — مع ضبط التوقيت مسبقاً.
يتيح لك تحويل النص إلى كلام لمتحدثين متعددين:
- تخصيص صوت ذكاء اصطناعي مختلف لكل متحدث في النص
- التحكم في التوقيت والوقفة بين كل متحدث
- توليد حوار كامل كملف صوتي واحد ومستمر
- التوسع من تبادل حوار بين شخصيتين إلى طاقم تمثيل كامل — دون الحاجة إلى عمليات تصدير إضافية أو تحرير يدوي
الخطوة 1 — ابحث عن الأصوات المناسبة باستخدام Discovery
قبل أن تتمكن من بناء مشروع لمتحدثين متعددين، فأنت بحاجة إلى أصوات. صفحة Discovery في Fish Audio هي المكان الذي تجدها فيه — ومع وجود آلاف الأصوات في المكتبة، تصبح أدوات التصفية مهمة جداً.
انتقل إلى fish.audio/app/discovery/.
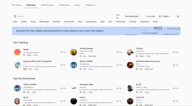
البحث والتصفية
تفتح صفحة Discovery مع شريط بحث، وعلامات تصفية سريعة على طول الصف العلوي، وعناصر تحكم في الترتيب واللغة على اليمين.
ابحث بالاسم إذا كنت تعرف بالفعل ما تبحث عنه. رتب حسب الموصى به (Recommended) أو الرائج (Trending) لإظهار ما يفضله المبدعون الآخرون. تقوم ميزة اللغة (Language) بتصفية المكتبة بأكملها للأصوات المدربة على لغتك المستهدفة.
تغطي علامات التصفية السريعة في الصف العلوي السمات الأكثر شيوعاً — ذكر (Male)، أنثى (Female)، شاب (Young)، منتصف العمر (Middle Aged)، سرد (Narration)، وسائل التواصل الاجتماعي (Social Media)، عميق (Deep)، ناعم (Soft)، احترافي (Professional)، درامي (Dramatic)، غامض (Mysterious)، أنمي (Anime) — ويمكنك الجمع بينها. سيؤدي اختيار أنثى + شاب + سرد على الفور إلى تضييق النتائج للأصوات التي تناسب هذا الملف الشخصي.

لمزيد من التحكم، افتح لوحة التصفية (Filter panel) (أيقونة المنزلقات في الجزء العلوي الأيمن). يمنحك هذا خيارات:
- اللغات — التضييق إلى لغة معينة، مع مطابقة اللغات المتعددة
- العلامات (Tags) — علامات نصية حرة أضافها منشئو الأصوات
- الجنس — ذكر، أنثى، محايد
- العمر — شاب، منتصف العمر، كبير في السن
- حالة الاستخدام — محادثة، سرد، صوت شخصية، وسائل تواصل اجتماعي، تعليمي، إعلان، والمزيد
- جودة الصوت — عميق، منخفض، متوسط، مرتفع، ناعم، ساطع، وأكثر من 48 وصفاً إضافياً
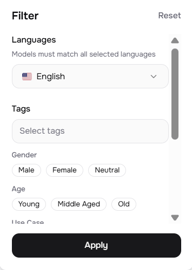
لمشروع متحدثين متعددين، تعتبر فلاتر حالة الاستخدام وجودة الصوت مفيدة بشكل خاص. إذا كنت تبني حواراً بأسلوب البودكاست، فقد ترغب في صوت واحد محادثة + ناعم وصوت آخر سرد + عميق — ليكونا متميزين بما يكفي ليتمكن المستمعون من التفريق بينهما دون الحاجة إلى رؤية النص.
الإعجاب، والإشارة المرجعية، والحفظ في مجموعة
عندما تجد صوتاً تريد العودة إليه، لديك عدة طرق لحفظه. أيقونة القلب في كل بطاقة صوت في نتائج البحث هي إعجاب سريع — حيث تضيف الصوت إلى علامة تبويب الإعجابات للرجوع إليها لاحقاً.
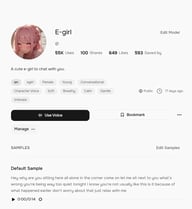
لحفظ أقوى، افتح صفحة تفاصيل الصوت وانقر على إشارة مرجعية (Bookmark). تظهر الأصوات التي تم وضع إشارة مرجعية عليها في علامة تبويب الإشارات المرجعية، منفصلة عن إعجاباتك، ويمكن الوصول إليها مباشرة من محدد الصوت في كل من TTS و Story Studio.
للتنظيم على مستوى المشروع، تعتبر المجموعات (Collections) الخيار الأقوى. انقر فوق Collections في التنقل العلوي، ثم Create Collection لإعداد مجموعة مسماة — على سبيل المثال، "استخدام البودكاست" أو "مشروع كتاب صوتي أ". أعطها عنواناً ووصفاً، ثم انقر فوق Create.

لإضافة صوت إلى مجموعة، افتح صفحة تفاصيل الصوت، وانقر فوق قائمة النقاط الثلاث (⋯) بجوار زر الإشارة المرجعية، وحدد Add to Collection. إذا كنت قد أنشأت مجموعة بالفعل، فستظهر في القائمة المنسدلة — نقرة واحدة تضيف الصوت.
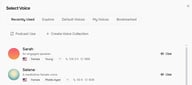
تأتي الفائدة الحقيقية عندما تكون داخل TTS أو Story Studio. عند فتح لوحة Select Voice، تظهر مجموعاتك كعلامات تبويب في الأعلى — بجوار المستعمل مؤخراً (Recently Used)، والاستكشاف (Explore)، والأصوات الافتراضية (Default Voices)، وأصواتي (My Voices)، والإشارات المرجعية (Bookmarked). بدلاً من البحث من الصفر في كل جلسة، تكون أصوات مشروعك مجمعة بالفعل وجاهزة.
الخطوة 2 — المتحدثون المتعددون في تحويل النص إلى كلام (TTS)
تدعم أداة تحويل النص إلى كلام من Fish Audio متحدثين متعددين في عملية توليد واحدة. إنها الأداة المناسبة للمحتوى القصير إلى المتوسط — مقتطفات الحوار، الإعلانات، مقدمات البودكاست القصيرة، نصوص العروض التوضيحية، وأي شيء تحتاج فيه إلى مخرجات سريعة ومصقولة دون إدارة الفصول. إذا لم تجد أصواتك بعد، فابدأ بتصفح مكتبة Discovery أولاً.
انتقل إلى fish.audio/app/text-to-speech/.
إعداد المتحدث الأول
عند فتح TTS، سترى كتلة نص واحدة مع محدد صوت في الأعلى. انقر فوق اسم الصوت لفتح لوحة Select Voice واختر متحدثك الأول. اكتب أو الصق أسطر المتحدث الأول في كتلة النص.
يمكنك أيضاً استخدام علامات المشاعر المضمنة لتشكيل أسلوب الإلقاء — [sad]، [emphasis]، [excited] — توضع مباشرة في النص قبل الكلمات التي يجب أن تؤثر عليها.
إضافة المزيد من المتحدثين
انقر فوق + Add Speaker أسفل كتلة النص الأولى. ستظهر كتلة جديدة، مع محدد صوت مستقل خاص بها. اختر صوتاً مختلفاً لهذا المتحدث، وأدخل أسطره، وسيتم توليد الكتلتين كملف صوتي واحد ومستمر — بالترتيب الذي تظهر به على الشاشة.
لا يوجد حد أقصى لعدد المتحدثين الذين يمكنك إضافتهم. كل كتلة مستقلة: صوت مختلف، نص مختلف، وعلامات مشاعر مختلفة إذا لزم الأمر. عملياً، تعمل معظم مشاريع الحوار بشكل جيد مع 2-4 أصوات متميزة — تنوع كافٍ ليكون واضحاً، دون أن يصبح من الصعب متابعته. في اللوحة اليمنى، يمكنك ضبط مستوى الصوت (Volume)، والسرعة (Speed)، وتطبيع الجهارة (Loudness Normalization)، و تطبيع النص (Text Normalization) (الذي يحسن دقة قراءة الأرقام والعملات والنصوص المنسقة المماثلة) قبل التوليد.
حد الحروف ومتى تنتقل إلى Story Studio
راقب عداد الحروف في أسفل الشاشة. يعتمد الحد على خطتك — تحقق من أسعار وخطط Fish Audio لمعرفة الحدود الخاصة بفئتك. بالنسبة للمحتوى القصير والمتوسط الطول، تعتبر أداة TTS سير العمل الأسرع والأبسط. ولكن إذا كنت تعمل على شيء أطول — فصل كامل من كتاب صوتي، بودكاست متعدد الأجزاء، نص حوار لعبة — فهذا هو المكان الذي يمنحك فيه Story Studio الأدوات التي تحتاجها حقاً.
الخطوة 3 — المتحدثون المتعددون في Story Studio
تم بناء Story Studio لإنتاج الصوت الطويل. في حين أن TTS مُحسَّن للتوليد السريع، فإن Story Studio يمنحك بيئة منظمة لتسلسل أصوات متعددة كتلة بكتلة — مع تحكم دقيق في التوقيت بين المتحدثين وتنظيم الفصول للمشاريع المعقدة. يتم توليد كل كتلة بشكل مستقل مع الصوت المخصص لها، ويقوم التصدير النهائي بدمجها في ملف واحد مستمر. انتقل إلى fish.audio/app/story-studio/.
إنشاء مشروع جديد
انقر فوق + Project في شاشة Story Studio الرئيسية. يفتح مربع حوار Create project مع هذه الإعدادات:
- Project Name — اسم مشروعك
- Default Voice — الصوت المخصص للكتل الجديدة افتراضياً (يمكنك تغييره لكل كتلة)
- Speech Model — حالياً S2 Pro (الأحدث)
- Text Normalization — عند تمكينه، يحسن دقة القراءة للأرقام والعملات والتواريخ والنصوص المماثلة
- Loudness Normalization — يقوم بتطبيع مستويات الصوت عبر الكتل للحصول على مخرجات متسقة
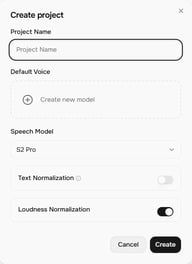
انقر فوق Create لفتح محرر المشروع.
إضافة الكتل وتبديل الأصوات
يفتح مشروعك مع فصل افتراضي وكتلة نص أولى موجودة بالفعل. يظهر صوت المتحدث الأول كأفاتار ملون على يسار كل كتلة.
لإضافة سطر لمتحدث جديد، انقر فوق زر + أسفل أي كتلة موجودة. ستظهر كتلة جديدة. انقر فوق أفاتار الصوت الملون على الجانب الأيسر من الكتلة الجديدة لفتح لوحة Select Voice وتخصيص صوت مختلف. اكتب سطر المتحدث الثاني في الكتلة.
كرر ذلك لكل تبادل في نصك. كل كتلة هي دور متحدث واحد. تعرض اللوحة الجانبية اليمنى الأصوات المستخدمة في المشروع (Voices used in the project) — وهي قائمة مباشرة لكل صوت مخصص حالياً عبر جميع الكتل، حتى تتمكن من تتبع طاقمك بلمحة سريعة.
ضبط الوقفة بين المتحدثين بدقة
بين كل زوج من الكتل، سترى فقاعة توقيت صغيرة تعرض الفجوة الحالية — على سبيل المثال، 0.35s. انقر عليها لضبط مدة الوقفة بين هذا الزوج المحدد من المتحدثين.
هذه واحدة من أهم ميزات Story Studio لواقعية الحوار. المحادثة البشرية ليست سلسلة من الأقوال المتتالية تماماً. لحظة صمت قبل الرد تشير إلى وقت التفكير. وقفة أطول قبل رد فعل عاطفي تضيف وزناً. ضبط هذه الفجوات بشكل صحيح هو الفرق بين الصوت الذي يبدو مُنتجاً والصوت الذي يبدو حقيقياً. حتى تعديل بمقدار 0.2-0.5 ثانية يمكن أن يغير بشكل ملحوظ مدى طبيعية المحادثة — الأمر يستحق ضبط كل تبادل بشكل فردي بدلاً من ترك جميع الفجوات عند القيمة الافتراضية. اضبط كل وقفة بين الكتل بشكل فردي لتناسب إيقاع المشهد.
إضافة فصول للمشاريع الطويلة
على الجانب الأيسر من المحرر، سترى لوحة الفصول (Chapters panel). افتراضياً، يبدأ كل مشروع بـ "Default Chapter" واحد. انقر فوق + لإضافة فصل جديد.
تسمح لك الفصول بتقسيم المشاريع الطويلة إلى أقسام قابلة للتنقل — فصل واحد لكل قسم من كتاب صوتي، أو لكل جزء من بودكاست، أو لكل مشهد في نص لعبة. كل فصل له تسلسله الخاص من الكتل ويمكن العمل عليه بشكل مستقل. يجمع التصدير النهائي جميع الفصول في مخرج واحد، بالترتيب.
لأي شيء يتجاوز بضع مئات من كلمات الحوار، الفصول هي طريقتك للحفاظ على تنظيم مشروع Story Studio وقابليته للتحرير.
TTS مقابل Story Studio — أيهما يجب أن تستخدم؟
| تحويل النص إلى كلام (TTS) | Story Studio | |
|---|---|---|
| طريقة تعدد المتحدثين | أصلية (على مستوى نموذج S2 Pro) | توليد كتل متتالية |
| حد الحروف | يعتمد على الخطة | لا يوجد حد (فصول متعددة) |
| عدد المتحدثين | حتى 5 | غير محدود |
| التحكم في الوقفة بين المتحدثين | ❌ | ✅ دقيق، لكل كتلة |
| إدارة الفصول | ❌ | ✅ |
| عرض الجدول الزمني | ❌ | ✅ |
| الأفضل لـ | الحوارات القصيرة، الإعلانات، العروض التجريبية | الكتب الصوتية، البودكاست، سيناريوهات الألعاب، الإنتاجات الطويلة |
الفرق التقني الرئيسي: يستخدم TTS إمكانية تعدد المتحدثين الأصلية في S2 Pro — حيث يتم التعامل مع متحدثين متعددين على مستوى النموذج في عملية توليد واحدة. بينما يحقق Story Studio مخرجات لمتحدثين متعددين من خلال تسلسل كتل تم توليدها بشكل منفصل، كل منها بصوتها المخصص، في ملف واحد مستمر.
إذا كنت تولد إعلاناً مدته 30 ثانية مع متحدثين أو مقطع حوار قصير، فابدأ في TTS — فهو أسرع ولا يتطلب إعداد مشروع. إذا كان نصك أطول، أو يتضمن أكثر من بضع تبادلات، أو يحتاج إلى توقيت دقيق بين المتحدثين، فافتح Story Studio بدلاً من ذلك.
حالات الاستخدام — ماذا يمكنك أن تصنع باستخدام ميزة المتحدثين المتعددين؟
الكتب الصوتية ذات الشخصيات المتعددة
تعمل الكتب الصوتية ذات الراوي الواحد بشكل جيد للكتب غير الخيالية. أما بالنسبة للقصص الخيالية التي تحتوي على حوارات، فإن صوتاً واحداً يقرأ جميع الشخصيات يصبح صعب المتابعة. مع ميزة المتحدثين المتعددين في TTS، تحصل كل شخصية في المشهد على صوتها الخاص — صوت أعمق وأكبر سناً لشخصية ما، وصوت أصغر وأكثر حيوية لشخصية أخرى. وتتوافق بنية الفصول في Story Studio مباشرة مع فصول الكتاب، مما يجعل من العملي إنتاج عناوين كاملة الطول دون الحاجة إلى سير عمل التمثيل والتسجيل التقليدي.
حوارات بأسلوب البودكاست
تنسيقات البودكاست ذات المضيفين هي واحدة من أكثر الهياكل الصوتية شهرة. باستخدام مولد أصوات ذكاء اصطناعي لمتحدثين متعددين للحوار، يمكنك إنتاج هذا التنسيق من نص مكتوب — صوت واحد لكل مضيف، مع وقفات محكومة تحاكي تبادل الأدوار الطبيعي. هذا مفيد بشكل خاص لمنشئي المحتوى الذين يرغبون في إنتاج محتوى صوتي منتظم دون جدولة جلسات تسجيل.
التعلم الإلكتروني والمحتوى التدريبي
يصبح المحتوى التعليمي أكثر جاذبية بشكل ملحوظ عندما يتم تقديمه كحوار بدلاً من مونولوج. يمكن كتابة وإنتاج تبادل بين معلم وطالب، أو سيناريو موجه، أو تنسيق سؤال وجواب بصوتين أو أكثر — مما يساعد المتعلمين على معالجة المعلومات من خلال الحوار بدلاً من السرد السلبي.
حوارات الألعاب وأصوات الشخصيات
غالبًا ما تتكون نصوص الألعاب من مئات أو آلاف الأسطر عبر شخصيات متعددة. باستخدام Story Studio كمولد صوت لشخصيات متعددة، يمكن لمطوري الألعاب ومصممي السرد إنتاج حوارات صوتية للنماذج الأولية أو العروض التجريبية أو الإنتاج الكامل — مع تخصيص صوت متسق لكل شخصية غير لاعبة (NPC) عبر كل سطر تتحدث به، دون الحاجة إلى سير عمل تسجيل الصوت التقليدي.
من النص إلى الصوت — في جلسة واحدة
كان إنتاج صوت متعدد الشخصيات يعني سابقاً حجز ممثلين صوتيين، وتنسيق جلسات تسجيل، وقضاء ساعات في مرحلة ما بعد الإنتاج لدمج اللقطات معاً. مع ميزة المتحدثين المتعددين في TTS، يتقلص سير العمل هذا بالكامل في جلسة واحدة: ابحث عن أصواتك في Discovery، ونظمها في مجموعة (Collection)، وابنِ نصك كتلة بكتلة، ثم قم بالتصدير.
للمحتوى القصير، يوصلك Text to Speech إلى هدفك في دقائق. وللإنتاجات الأطول — الكتب الصوتية، وسلاسل البودكاست، وحوارات الألعاب — يمنحك Story Studio البنية والتحكم في التوقيت لإنتاج شيء يبدو حقاً وكأنه تم تمثيله.
🎧 أنشئ أول حوار لك بين متحدثين في أقل من دقيقتين ←
🎙 حول نصك إلى كتاب صوتي بطاقم كامل باستخدام أصوات الذكاء الاصطناعي ←

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






