Sometimos nuestro TTS a una prueba a ciegas frente a todos los principales competidores. Aquí están los resultados.

Sometimos nuestro TTS a una prueba a ciegas frente a todos los principales competidores. Aquí están los resultados.
Fish Audio realizó una prueba A/B a ciegas de 10 días sobre el tráfico de producción real, enfrentando a Fish Audio S2 Pro y S1 contra ElevenLabs, Inworld y MiniMax. Se recopilaron más de 5,000 pares de preferencias de usuarios reales que no tenían idea de qué proveedor generaba cada audio.
Resumen ejecutivo (TLDR): Resultados
Fish Audio S2 Pro ocupó el puesto #1 general con una puntuación Bradley-Terry de 3.07, casi 1.7 veces superior al siguiente mejor modelo. Nuestro modelo anterior, Fish Audio S1 (BT 1.86), también superó a todos los proveedores externos en conjunto.
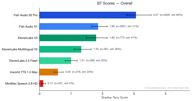
| Puesto | Modelo | Puntuación BT | Tasa de victoria | Muestras |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3.07 | 65.7% | 4,573 |
| 2 | Fish Audio S1 | 1.86 | 41.0% | 3,560 |
| 3 | ElevenLabs V3 | 1.80 | 40.6% | 766 |
| 4 | ElevenLabs Multilingual V2 | 1.35 | 36.2% | 359 |
| 5 | ElevenLabs 2.5 Flash | 1.00 | 29.8% | 364 |
| 6 | Inworld TTS 1.5 Max | 0.59 | 20.1% | 373 |
| 7 | MiniMax Speech 2.8 HD | 0.12 | 5.0% | 201 |
Enfrentamientos directos clave:
- Fish S2 Pro supera a ElevenLabs V3 60% a 40% (581 pares)
- Fish S2 Pro supera a Inworld 80% a 20% (261 pares)
- Fish S2 Pro supera a MiniMax 95% a 5% (142 pares)
- Fish S1 supera a ElevenLabs V3 64% a 36% (150 pares)
¿Por qué hicimos esto?
El problema de las métricas tradicionales
El MOS (Mean Opinion Score) sigue siendo el estándar de facto para la evaluación de TTS, pero tiene graves deficiencias. Las condiciones de las pruebas rara vez se revelan: la longitud de la muestra, la demografía de los oyentes, el entorno de reproducción y las instrucciones de calificación varían en cada estudio, lo que hace que las comparaciones entre artículos científicos no tengan sentido. Mientras tanto, el WER/CER (tasa de error de palabras/caracteres) puede ser contraproducente como objetivo de optimización: reducir demasiado el WER a menudo obliga al modelo a producir un habla hiperarticulada y robótica que sacrifica la naturalidad y la prosodia en favor de la inteligibilidad. Un modelo que ocasionalmente balbucea como un humano real puede sonar mejor que uno que enuncia cada sílaba a la perfección.
El problema de las tablas de clasificación actuales
Las tablas de clasificación públicas como TTS-Arena-V2 y Artificial Analysis evalúan los modelos con frases cortas y sencillas, normalmente una sola línea de diálogo o una breve narración. Esto no logra capturar la complejidad del uso del TTS en el mundo real: contenido de formato largo, diálogos con varios interlocutores, etiquetas de prosodia expresiva y texto multilingüe.
Más allá de la metodología, existen preocupaciones sobre la integridad. TTS-Arena-V2 ha tenido problemas conocidos de filtración de encabezados de audio, donde los metadatos en el archivo de audio podrían revelar la identidad del proveedor, rompiendo la premisa de la evaluación a ciegas. También somos conscientes de que la manipulación de las tablas de clasificación está muy extendida: los proveedores optimizan específicamente para las frases de referencia, envían puntos de control de modelos seleccionados meticulosamente o inflan las clasificaciones mediante votaciones coordinadas. Estas tablas de clasificación se han convertido en herramientas de marketing en lugar de señales de calidad fiables.
Lo que realmente queríamos
Necesitábamos una señal de recompensa interna fiable, una medida de referencia absoluta sobre "¿qué salida de TTS prefieren realmente los usuarios?" en la que pudiéramos confiar para tomar decisiones de desarrollo de modelos. No una cifra de un artículo científico, ni un puesto en una tabla de clasificación manipulable, sino un flujo continuo de datos de preferencia honestos de usuarios que toman decisiones reales.
Así que creamos un canal de evaluación a ciegas directamente en nuestra plataforma de producción.
Diseño del experimento
Comparación por pares a ciegas
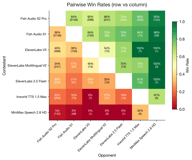
El estudio de Fish Audio presenta a los usuarios dos versiones de audio en paralelo para cada tarea de TTS. Cada versión tiene, de forma independiente, un 10% de probabilidades de ser dirigida silenciosamente a un proveedor de la competencia en lugar de al backend predeterminado de Fish Audio. Mismo texto, misma voz de referencia, misma interfaz de usuario: el usuario no tiene idea de qué proveedor generó cada audio.
El experimento duró 10 días (del 26 de marzo al 5 de abril de 2026) y se recopilaron más de 71,000 grupos emparejados, de los cuales 5,098 contenían comparaciones entre proveedores que cumplían nuestros criterios de calidad.
Qué se considera una "victoria"
Utilizamos una señal conductual estricta, no una calificación subjetiva:
- El usuario debe reproducir ambas versiones al menos 2 veces cada una, confirmando que realmente comparó ambas.
- Exactamente una versión se descarga: ese es el ganador.
Esta señal de "escuchar y luego descargar" es mucho más fiable que las calificaciones con estrellas o las encuestas de elección forzada. Los usuarios están tomando decisiones reales sobre audios que realmente van a utilizar.
Composición de los usuarios
El experimento tomó muestras de aproximadamente un 70% de usuarios nuevos y un 30% de usuarios recurrentes. Esta composición puede introducir un ligero sesgo hacia Fish Audio (los usuarios recurrentes ya están familiarizados con nuestra plataforma), pero también garantiza que capturemos las preferencias genuinas de primera impresión de la mayoría de los participantes.
Selección de voces
Utilizamos las 500 voces públicas principales de la plataforma para el experimento. Cada voz se clonó previamente en el sistema del proveedor externo, lo que garantizó que la misma identidad de voz de referencia estuviera disponible en ambos lados. Los mapeos de ID de voz se mantienen en archivos JSON específicos que sirven como única fuente de verdad para la elegibilidad de enrutamiento.
Proveedores y modelos probados
| Proveedor | Modelo | Objetivo de ruta |
|---|---|---|
| Fish Audio | S2 Pro (más reciente) | fish:s2-pro |
| Fish Audio | S1 (generación anterior) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
Cobertura de evaluación y soporte de etiquetas
No todos los proveedores admiten el mismo conjunto de funciones. Fish Audio S2 Pro admite etiquetas de prosodia enriquecidas (p. ej., [laughs], [sighs]) y etiquetas de locutor (<|speaker:N|>) para contenido con varios interlocutores. Esto es importante porque nuestro tráfico de producción incluye de forma natural texto etiquetado.
- ElevenLabs V3 recibió la evaluación más completa: admite etiquetas arbitrarias tras la normalización a formato entre paréntesis, por lo que fue apto para prácticamente todas las solicitudes independientemente del contenido.
- ElevenLabs 2.5 Flash y Multilingual V2: solo enviamos solicitudes de texto sin formato a estos modelos (sin etiquetas).
- Inworld: solo texto sin formato y restringido al formato de salida
mp3, lo que limitó aún más su tráfico elegible. - MiniMax: aceptó etiquetas de interjección (
(laughs),(sighs), etc.) pero rechazó otros tipos de etiquetas. Debido a los resultados de preferencia de usuario consistentemente bajos, el experimento se detuvo prematuramente para evitar degradar más la experiencia del usuario.
El sistema de enrutamiento evalúa cada proveedor alternativo frente a las características de la solicitud actual (idioma, etiquetas, formato, voces de referencia múltiples). Solo las alternativas compatibles se convierten en candidatas elegibles, y se selecciona una mediante una elección aleatoria ponderada. Si la única alternativa elegible es una comparación de Fish contra Fish (S1 frente a S2 Pro), la probabilidad de muestreo efectiva se reduce a 1/10 de la tasa base para priorizar la recopilación de datos entre proveedores.
Lo que nos costó
Estos experimentos no son gratuitos. Las API de TTS de terceros son costosas a gran escala:
- ElevenLabs: más de $1,500 gastados en llamadas a la API.
- MiniMax: $330 gastados (detenido prematuramente debido al bajo rendimiento).
- Inworld: $170 gastados.

Metodología estadística
Modelo Bradley-Terry
Las tasas de victoria brutas pueden ser engañosas cuando diferentes modelos se enfrentan a diferentes oponentes con diferentes frecuencias. El modelo Bradley-Terry resuelve esto calculando una puntuación de fuerza global a partir de los datos de comparación por pares. Estima de forma iterativa el parámetro de "fuerza" latente de cada modelo de modo que la probabilidad de victoria predicha entre dos modelos cualesquiera coincida con los datos observados.
Para dos modelos y con puntuaciones BT y :
Nuestra implementación realiza hasta 500 iteraciones con una tolerancia de convergencia de , normalizando las puntuaciones mediante la media geométrica en cada paso.
Intervalos de confianza
Informamos sobre intervalos de confianza bootstrap del 95% calculados a partir de 200 resamples de los datos de los pares de preferencias. Cada resample toma pares con reemplazo de los pares originales y vuelve a ejecutar el cálculo BT completo. Los percentiles 2.5 y 97.5 de las puntuaciones de bootstrap forman los límites del IC.
Para las tasas de victoria por backend, utilizamos intervalos de puntuación de Wilson, que proporcionan una mejor cobertura que los intervalos de aproximación normal en tasas de victoria extremas.
Resultados por idioma
Idiomas con alfabeto latino (inglés, español, francés, alemán, ...)
Los idiomas con alfabeto latino representan el segmento más grande con 4,173 pares de preferencias.
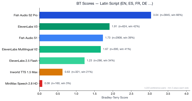
Fish S2 Pro lidera con 3.05. Cabe destacar que ElevenLabs V3 (1.90) supera ligeramente a Fish S1 (1.72) en esta categoría; el único grupo de idiomas donde un competidor aventaja a nuestro modelo anterior. ElevenLabs Multilingual V2 también tiene un buen desempeño con 1.70, cerca de S1.
Esto tiene sentido: ElevenLabs se ha centrado históricamente en el inglés y los idiomas europeos, y su modelo V3 es fuerte en este dominio. Aun así, Fish S2 Pro mantiene una ventaja de 1.6 veces sobre ElevenLabs V3.
Chino
El chino tiene 329 pares de preferencias y muestra el dominio más dramático de Fish Audio.
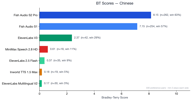
Ambos modelos de Fish Audio (S2 Pro con 8.11, S1 con 7.11) superan masivamente a todos los competidores. ElevenLabs V3 obtiene 2.36, una cifra respetable pero muy lejana. Todos los demás competidores puntúan por debajo de 1.0.
Japonés
El japonés tiene 354 pares de preferencias.
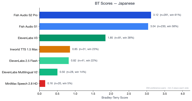
Fish S2 Pro (3.12) y Fish S1 (3.02) están muy cerca, ambos muy por delante de ElevenLabs V3 (1.88). La brecha entre los modelos de Fish Audio y los competidores es mayor en los idiomas CJK.
Resumen entre idiomas
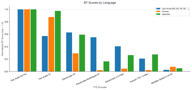
Fish Audio S2 Pro ocupa el puesto #1 en todas las categorías de idiomas. La brecha competitiva varía:
- Alfabeto latino: los competidores están más cerca, ElevenLabs V3 es realmente competitivo (puntuación relativa de 0.62).
- Chino: el dominio de Fish Audio es abrumador, los competidores apenas aparecen.
- Japonés: similar al chino, los modelos de Fish Audio están muy por delante.
Limitaciones
Usuarios de la API excluidos
Para garantizar la estabilidad de la plataforma, no se incluyó a los usuarios de la API en el experimento. La tasa de muestreo del 10% se aplica solo a los usuarios de la plataforma web. Esto significa que nuestros resultados reflejan los patrones de uso de la plataforma web, que pueden diferir de las cargas de trabajo de producción con uso intensivo de la API.
El soporte de etiquetas genera una cobertura desigual
Debido a que los proveedores externos tienen un soporte de etiquetas variable, recibieron diferentes subconjuntos de tráfico:
- ElevenLabs V3 fue apto para casi todas las solicitudes (admite etiquetas).
- ElevenLabs Flash/Multilingual solo recibió solicitudes sin etiquetas.
- Inworld solo recibió solicitudes sin etiquetas y en formato mp3.
Esto significa que el campo competitivo no está perfectamente nivelado. Los resultados de ElevenLabs V3 son los más directamente comparables con Fish Audio, ya que recibió la muestra de tráfico más representativa. Otros modelos fueron evaluados en un subconjunto que se inclina hacia solicitudes de texto sin formato más simples, lo que posiblemente debería favorecerlos.
Los resultados de MiniMax podrían no ser fiables
MiniMax Speech 2.8 HD obtuvo una puntuación extraordinariamente baja (BT 0.12, tasa de victoria del 5%, incluso contra Inworld). Sospechamos que nuestra integración de la API de MiniMax podría no ser óptima. Tras escuchar varias muestras generadas por MiniMax, no pudimos identificar un problema técnico específico: el audio era inteligible, pero mostraba una prosodia y naturalidad notablemente peores en comparación con todos los demás proveedores. Ampliamos la elegibilidad de enrutamiento de MiniMax a mitad del experimento para aumentar el tamaño de la muestra, pero el rendimiento no mejoró. El experimento se detuvo prematuramente tras acumular $330 en costes de API sin signos de resultados competitivos.
Si MiniMax considera que estos resultados no reflejan la capacidad real de su modelo, agradecemos una revisión colaborativa de nuestra integración.
Restricciones de mapeo de voces
Solo se pueden enrutar las voces que se clonaron correctamente en la plataforma de terceros. Si la clonación de una voz fallaba, esa voz quedaba excluida del grupo de elegibles de ese proveedor. Esto significa que cada proveedor fue probado en un subconjunto de las 500 voces principales ligeramente diferente (aunque coincidente en gran medida).
Posible sesgo por familiaridad con la plataforma
Aunque tomamos muestras de un ~70% de usuarios nuevos, el ~30% restante de usuarios recurrentes puede haber desarrollado preferencias alineadas con las características de audio de Fish Audio. Creemos que este efecto es pequeño dada la composición mayoritaria de usuarios nuevos, pero no se puede descartar por completo.
Conclusión
Creemos que esta es una de las evaluaciones públicas más rigurosas de la calidad de TTS jamás realizadas:
- Usuarios reales, no anotadores pagados.
- Comparación a ciegas: los usuarios nunca saben qué proveedor generó cada audio.
- Señal conductual (descarga) en lugar de calificaciones subjetivas.
- Tráfico de producción con la complejidad del texto del mundo real, incluyendo contenido de formato largo, etiquetas de prosodia y texto multilingüe.
- Más de 5,000 pares de preferencias en varios idiomas, recopilados durante 10 días.
- Más de $2,000 gastados solo en llamadas a API de terceros.
Los resultados son claros: Fish Audio S2 Pro es el modelo TTS preferido en todos los idiomas probados, con ventajas particularmente sólidas en chino y japonés. Incluso nuestro modelo S1 de la generación anterior supera a todos los competidores en conjunto.
Estos resultados validan aún más nuestra hoja de ruta hacia el modelado de extremo a extremo y el RLHF (Aprendizaje por refuerzo a partir de la retroalimentación humana). Estamos comprometidos con la transparencia. La metodología, la lógica de enrutamiento y el código de análisis forman parte de la infraestructura de nuestra plataforma. Invitamos a la comunidad de TTS a analizar nuestro enfoque y sugerir mejoras para futuras evaluaciones.
Esta evaluación fue realizada por el equipo de Fish Audio del 26 de marzo al 5 de abril de 2026. Para preguntas o para discutir la metodología, contáctenos en fish.audio.








