Fish Audio libera el código de S2: el control detallado se une al streaming de producción
9 mar 2026
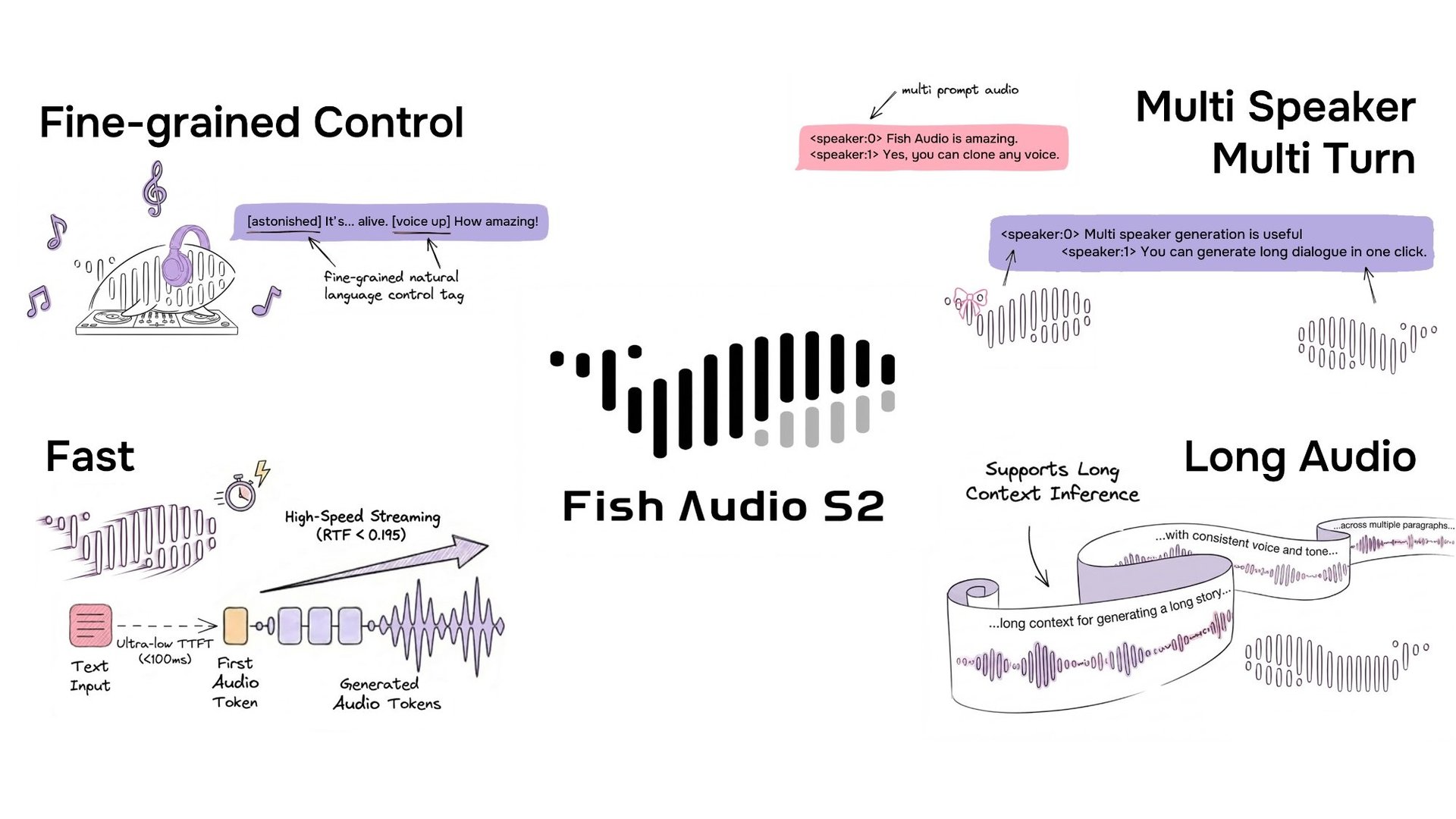
El código abierto de S2 está disponible a través del repositorio de GitHub del proyecto y de HuggingFace.
Fish Audio ha liberado el código de S2, un modelo de texto a voz que admite un control detallado en línea de la prosodia y la emoción mediante etiquetas de lenguaje natural como [laugh], [whispers] y [super happy]. Entrenado con más de 10 millones de horas de audio en aproximadamente 50 idiomas, el sistema combina la alineación de aprendizaje por refuerzo con una arquitectura autorregresiva dual. El lanzamiento incluye los pesos del modelo, el código de ajuste fino y un motor de inferencia de streaming basado en SGLang.
Control detallado en línea mediante lenguaje natural
S2 permite el control en línea sobre la generación de voz al integrar instrucciones de lenguaje natural directamente en posiciones específicas de palabras o frases dentro del texto. En lugar de depender de un conjunto fijo de etiquetas predefinidas, S2 acepta descripciones textuales de formato libre —como [whisper in small voice], [professional broadcast tone] o [pitch up]— permitiendo un control de la expresión abierto a nivel de palabra.
En el Audio Turing Test, S2 logra una media posterior de 0.515 con reescritura de instrucciones, en comparación con el 0.417 de Seed-TTS y el 0.387 de MiniMax-Speech. En EmergentTTS-Eval, alcanza una tasa de victoria global del 81.88% frente a una línea de base de gpt-4o-mini-tts, la más alta entre todos los modelos evaluados, incluidos los sistemas de código cerrado de Google y OpenAI.
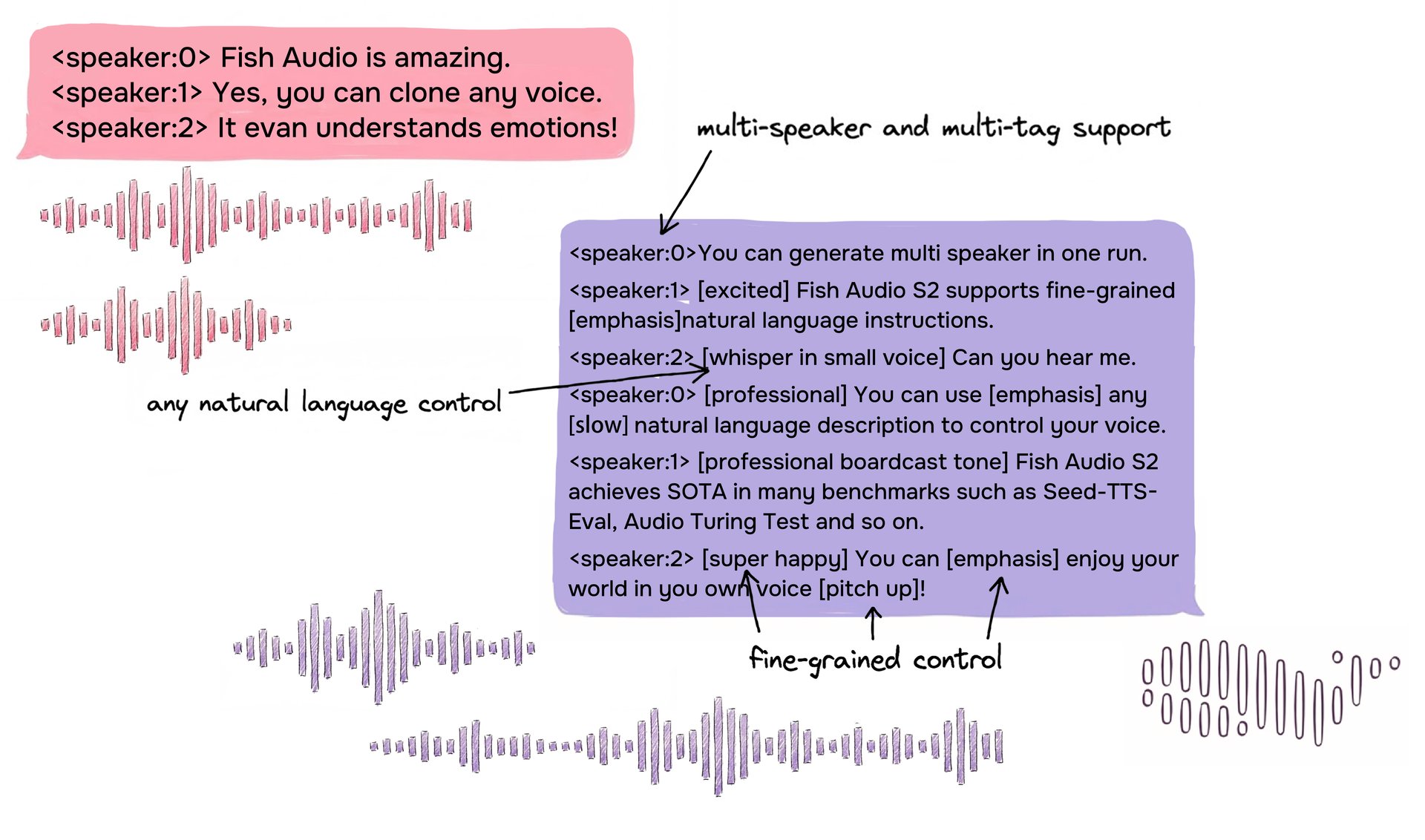 Ejemplo del formato de entrada de S2 que muestra un diálogo multi-hablante con etiquetas en línea de lenguaje natural de formato libre para un control detallado.
Ejemplo del formato de entrada de S2 que muestra un diálogo multi-hablante con etiquetas en línea de lenguaje natural de formato libre para un control detallado.
Una receta unificada: Curación de datos y recompensas de RL a partir de los mismos modelos
Una decisión arquitectónica fundamental en S2 es que los mismos modelos utilizados para filtrar y anotar los datos de entrenamiento se reutilizan directamente como modelos de recompensa durante el aprendizaje por refuerzo (RL):
- El modelo de calidad de voz califica el audio en dimensiones como SNR, consistencia del hablante e inteligibilidad durante el filtrado de datos; luego sirve como la recompensa de preferencia acústica durante el RL.
- El modelo ASR de transcripción enriquecida (pre-entrenamiento continuado de Qwen3-Omni-30B-A3B) genera transcripciones aumentadas con subtítulos y anotaciones paralingüísticas en línea durante la curación de datos; luego proporciona la recompensa de inteligibilidad y seguimiento de instrucciones al volver a transcribir el audio generado y compararlo con el prompt original.
Este diseño de doble propósito elimina por construcción el desajuste de distribución entre los datos de pre-entrenamiento y los objetivos de post-entrenamiento, un problema que sigue sin resolverse en otros sistemas TTS que entrenan modelos de recompensa por separado de sus flujos de datos.
Dentro del modelo: Arquitectura Dual-AR
S2 se basa en un transformador de solo decodificador combinado con un códec de audio basado en RVQ (10 libros de códigos, frecuencia de cuadro de ~21 Hz). Aplanar todos los libros de códigos a lo largo del tiempo causaría una explosión de la longitud de la secuencia de 10 veces. S2 aborda esto con una arquitectura Autorregresiva Dual (Dual-AR):
- AR Lento (Slow AR) opera a lo largo del eje del tiempo y predice el libro de códigos semántico principal.
- AR Rápido (Fast AR) genera los 9 libros de códigos residuales restantes en cada paso de tiempo, reconstruyendo el detalle acústico detallado.
Este diseño asimétrico —4 mil millones de parámetros a lo largo del eje del tiempo, 400 millones a lo largo del eje de profundidad— mantiene la inferencia eficiente mientras preserva la fidelidad del audio.
Alineación por aprendizaje por refuerzo para el habla
Para el post-entrenamiento, S2 utiliza la Optimización de Política Relativa de Grupo (GRPO), elegida para evitar la sobrecarga de memoria de los modelos de valor estilo PPO en contextos de audio largos. La señal de recompensa combina múltiples dimensiones, incluyendo:
- Precisión semántica y cumplimiento de instrucciones
- Puntuación de preferencia acústica
- Similitud de timbre
Resultados de Benchmark
S2 logra resultados líderes en múltiples puntos de referencia públicos:
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chino) | 0.54% (mejor global) |
| Seed-TTS Eval — WER (Inglés) | 0.99% (mejor global) |
| Audio Turing Test (con instrucción) | 0.515 media posterior |
| EmergentTTS-Eval — Tasa de victoria | 81.88% (más alta global) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — Calidad | 4.51 / 5.0 |
| Multilingüe (MiniMax Testset) — Mejor WER | 11 de 24 idiomas |
| Multilingüe (MiniMax Testset) — Mejor SIM | 17 de 24 idiomas |
En Seed-TTS Eval, S2 logra el WER más bajo entre todos los modelos evaluados, incluidos los sistemas de código cerrado: Qwen3-TTS (0.77/1.24), MiniMax Speech-02 (0.99/1.90), Seed-TTS (1.12/2.25). En el Audio Turing Test, 0.515 supera a Seed-TTS (0.417) en un 24% y a MiniMax-Speech (0.387) en un 33%. En EmergentTTS-Eval, S2 logra resultados particularmente sólidos en paralingüística (91.61% de tasa de victoria), preguntas (84.41%) y complejidad sintáctica (83.39%).
Streaming de producción a través de SGLang
Debido a que la arquitectura Dual-AR de S2 es estructuralmente isomórfica a los LLM autorregresivos estándar, puede heredar directamente todas las optimizaciones de servicio nativas de LLM de SGLang con modificaciones mínimas, incluyendo el procesamiento por lotes continuo, caché KV paginada, reajuste de gráficos CUDA y almacenamiento en caché de prefijos basado en RadixAttention.
Para la clonación de voz, S2 coloca tokens de audio de referencia en el prompt del sistema. RadixAttention de SGLang almacena automáticamente estos estados KV, logrando una tasa media de aciertos de caché de prefijos del 86.4% (más del 90% en picos) cuando se reutiliza la misma voz en varias solicitudes, lo que hace que la sobrecarga de pre-llenado del audio de referencia sea casi insignificante.
En una sola GPU NVIDIA H200:
- Factor de tiempo real (RTF): 0.195
- Tiempo para el primer audio: aproximadamente 100 ms
- Rendimiento: más de 3,000 tokens acústicos/s manteniendo el RTF por debajo de 0.5
Por qué es importante este lanzamiento
S2 no se publica solo como un punto de control del modelo, sino como un sistema completo: pesos del modelo, código de ajuste fino y un conjunto de inferencia listo para producción.
Destacan dos opciones de diseño. Primero, el flujo unificado de datos y recompensa elimina un problema estructural —el desajuste de distribución entre el pre-entrenamiento y el RL— que otros sistemas TTS no han abordado a nivel arquitectónico. Segundo, el isomorfismo estructural entre la arquitectura Dual-AR y los LLM estándar significa que S2 puede aprovechar todo el ecosistema de optimizaciones de servicio de LLM, en lugar de requerir una infraestructura de inferencia personalizada.
S2 está disponible a través del repositorio de GitHub del proyecto, SGLang-Omni, HuggingFace y una demostración interactiva en fish.audio.



