Texto a voz con múltiples voces — Guía completa de multispeaker (Fish Audio)

El TTS de una sola voz suena plano para diálogos, audiolibros y podcasts. Esta guía le muestra cómo encontrar y organizar voces en Fish Audio, y luego usar la función multispeaker en TTS y Story Studio para producir audio natural con múltiples personajes — sin los flujos de trabajo tradicionales de grabación de voz.
Marzo 2026 | El TTS multispeaker de Fish Audio ya está disponible en S2 Pro
Tabla de contenidos
- ¿Qué es el texto a voz multispeaker?
- Paso 1 — Encuentra las voces adecuadas con Discovery
- Paso 2 — Multispeaker en Texto a voz
- Paso 3 — Multispeaker en Story Studio
- TTS vs Story Studio — ¿Cuál deberías usar?
- Casos de uso — ¿Qué puedes crear con el TTS multispeaker?
- Del guion al audio — En una sola sesión
- Preguntas frecuentes sobre el TTS multispeaker
La mayoría de las herramientas de texto a voz te ofrecen una sola voz. Un narrador. Un tono, de principio a fin. Para un video explicativo de un solo locutor, eso funciona bien. Pero en el momento en que tu guion involucra a dos personajes hablando, un anfitrión y un invitado, o una historia con roles distintos, una sola voz convierte el diálogo en una lectura plana y monótona. Los oyentes pierden el interés rápidamente.
El texto a voz con múltiples voces soluciona esto. Asigna una voz de IA diferente a cada hablante, controla el tiempo entre ellos y el resultado es una conversación que realmente suena como tal. Fish Audio funciona como un generador completo de diálogos de texto a voz, cubriendo todo, desde el descubrimiento de voces hasta la exportación de múltiples capítulos. Esta guía te llevará a través de todo el flujo de trabajo: cómo descubrir y organizar voces, cómo usar la función multispeaker en la herramienta de Texto a voz para contenido corto y cómo escalar a producciones completas en Story Studio.
¿Qué es el texto a voz multispeaker?
El texto a voz multispeaker es un flujo de trabajo de TTS donde se asignan diferentes segmentos de un guion a diferentes voces de IA — cada una con su propio tono, género, edad y estilo de habla — y luego se generan como una única salida de audio continua.
Las herramientas tradicionales de TTS están construidas alrededor de un modelo de narración única: una voz, una entrada de texto, un archivo de audio. Ese diseño funciona para la narración de audiolibros con un solo narrador, locuciones o anuncios. Pero falla por completo en cualquier cosa que involucre diálogos. Para producir una conversación de dos personajes con herramientas antiguas, tendrías que generar cada hablante por separado y luego unir manualmente el audio en un editor — ajustando el tiempo, nivelando el volumen y esperando que las transiciones no parezcan dos grabaciones diferentes.
El problema no son solo los pasos adicionales. Es que el tiempo entre los hablantes es casi imposible de lograr correctamente sin controles dedicados. Una conversación real tiene ritmo: un segundo de silencio antes de una respuesta, un ligero solapamiento cuando alguien interrumpe, una pausa más larga ante una respuesta difícil. Sin un control preciso sobre los espacios entre hablantes, incluso un diálogo bien interpretado suena robótico.
Las herramientas de TTS multispeaker abordan ambos problemas. Cada hablante tiene su propia voz y su propio bloque de texto. Los espacios entre hablantes son ajustables. El resultado final es un archivo de audio único y coherente, con el tiempo ya integrado.
El texto a voz multispeaker te permite:
- Asignar una voz de IA diferente a cada hablante en un guion
- Controlar el tiempo y la pausa entre cada hablante
- Generar un diálogo completo como un archivo de audio único y continuo
- Escalar de un intercambio de dos personajes a un elenco completo, sin exportaciones adicionales ni edición manual
Paso 1 — Encuentra las voces adecuadas con Discovery
Antes de construir un proyecto multispeaker, necesitas voces. La página Discovery de Fish Audio es donde las encuentras, y con miles de voces en la biblioteca, las herramientas de filtrado son fundamentales.
Ve a fish.audio/app/discovery/.
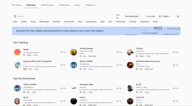
Búsqueda y filtros
La página Discovery se abre con una barra de búsqueda, etiquetas de filtro rápido en la fila superior y controles de orden e idioma a la derecha.
Busca por nombre si ya sabes lo que buscas. Ordena por Recomendados o Tendencias para ver qué está funcionando para otros creadores. El filtro de Idioma filtra toda la biblioteca a voces entrenadas en tu idioma objetivo.
Las etiquetas de filtro rápido en la fila superior cubren los atributos más comunes — Masculino, Femenino, Joven, Edad Media, Narración, Redes Sociales, Profunda, Suave, Profesional, Dramática, Misteriosa, Anime — y puedes combinarlas. Seleccionar Femenino + Joven + Narración limitará inmediatamente los resultados a voces que se ajusten a ese perfil.

Para más control, abre el panel de Filtros (el icono de controles en la parte superior derecha). Esto te ofrece:
- Idiomas — limitar a un idioma específico, con coincidencia multilingüe
- Etiquetas — etiquetas de formato libre añadidas por los creadores de voces
- Género — Masculino, Femenino, Neutral
- Edad — Joven, Edad Media, Anciano
- Caso de uso — Conversacional, Narración, Voz de personaje, Redes sociales, Educativo, Publicidad y más
- Cualidades de la voz — Profunda, Baja, Media, Alta, Suave, Brillante y más de 48 descriptores adicionales
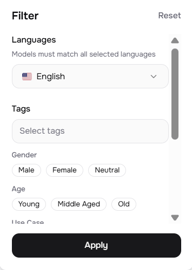
Para un proyecto multispeaker, los filtros de Caso de uso y Cualidades de voz son especialmente útiles. Si estás construyendo un diálogo estilo podcast, podrías querer una voz Conversacional + Suave y una voz de Narración + Profunda; lo suficientemente distintas para que los oyentes puedan diferenciarlas sin necesidad de ver la transcripción.
Me gusta, marcadores y guardar en una colección
Cuando encuentres una voz a la que quieras volver, tienes varias formas de guardarla. El icono de corazón en cada tarjeta de voz en los resultados de búsqueda es un Me gusta rápido: añade la voz a tu pestaña de Me gusta para referencia futura.
Para un guardado más permanente, abre la página de detalles de la voz y haz clic en Marcador. Las voces Marcadas aparecen en la pestaña de Marcadores, separadas de tus me gusta, y son accesibles directamente desde el selector de voz tanto en TTS como en Story Studio.
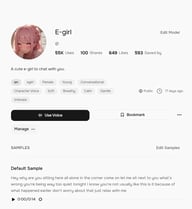
Para la organización a nivel de proyecto, las Colecciones son la opción más potente. Haz clic en Colecciones en la navegación superior, luego en Crear colección para configurar un grupo con nombre — por ejemplo, "Uso para Podcast" o "Proyecto de Audiolibro A". Ponle un título y descripción, luego haz clic en Crear.

Para añadir una voz a una colección, abre la página de detalles de la voz, haz clic en el menú de tres puntos (⋯) junto al botón de Marcador y selecciona Añadir a la colección. Si ya has creado una colección, aparecerá en el menú desplegable; un solo clic añade la voz.
La recompensa llega cuando estás dentro de TTS o Story Studio. Cuando abras el panel de Seleccionar voz, tus colecciones aparecerán como pestañas en la parte superior, justo al lado de Usadas recientemente, Explorar, Voces predeterminadas, Mis voces y Marcadores. En lugar de buscar desde cero en cada sesión, las voces de tu proyecto ya están agrupadas y listas.
Paso 2 — Multispeaker en Texto a voz
La herramienta de Texto a voz de Fish Audio admite múltiples hablantes en una sola generación. Es la herramienta adecuada para contenido corto o medio: fragmentos de diálogo, anuncios, introducciones cortas de podcasts, guiones de demostración y cualquier cosa donde necesites una salida rápida y pulida sin gestión de capítulos. Si aún no has encontrado tus voces, empieza explorando la biblioteca Discovery primero.
Ve a fish.audio/app/text-to-speech/.
Configura tu primer hablante
Cuando abras TTS, verás un único bloque de texto con un selector de voz en la parte superior. Haz clic en el nombre de la voz para abrir el panel de Seleccionar voz y elige a tu primer hablante. Escribe o pega las líneas del primer hablante en el bloque de texto.
También puedes usar etiquetas de emoción integradas para dar forma a la interpretación — [sad], [emphasis], [excited] — colocadas directamente en el texto antes de las palabras que deben afectar.
Añade más hablantes
Haz clic en + Añadir hablante debajo del primer bloque de texto. Aparecerá un nuevo bloque, con su propio selector de voz independiente. Elige una voz diferente para este hablante, introduce sus líneas, y los dos bloques se generarán como un único archivo de audio continuo, en el orden en que aparecen en pantalla.
No hay un límite superior en el número de hablantes que puedes añadir. Cada bloque es independiente: voz diferente, texto diferente y etiquetas de emoción diferentes si es necesario. En la práctica, la mayoría de los proyectos de diálogo funcionan bien con 2–4 voces distintas — variedad suficiente para ser clara, sin volverse difícil de seguir. En el panel derecho, puedes ajustar con precisión el Volumen, Velocidad, Normalización de sonoridad y Normalización de texto (que mejora la precisión de lectura de números, monedas y textos con formato similar) antes de generar.
Límite de caracteres y cuándo pasar a Story Studio
Presta atención al contador de caracteres en la parte inferior de la pantalla. El límite depende de tu plan — consulta los límites de precios y planes de Fish Audio para ver la asignación específica de tu nivel. Para contenido corto y de longitud media, TTS es el flujo de trabajo más rápido y sencillo. Pero si estás trabajando en algo más largo — un capítulo completo de un audiolibro, un podcast de varios segmentos, el guion de diálogo de un juego — ahí es donde Story Studio te ofrece las herramientas que realmente necesitas.
Paso 3 — Multispeaker en Story Studio
Story Studio está diseñado para la producción de audio de formato largo. Mientras que el TTS está optimizado para una generación rápida, Story Studio te ofrece un entorno estructurado para secuenciar múltiples voces bloque por bloque, con un control preciso sobre el tiempo entre hablantes y la organización por capítulos para proyectos complejos. Cada bloque se genera de forma independiente con su voz asignada, y la exportación final los une en un solo archivo continuo. Ve a fish.audio/app/story-studio/.
Crea un nuevo proyecto
Haz clic en + Proyecto en la pantalla de inicio de Story Studio. Se abre el diálogo Crear proyecto con estos ajustes:
- Nombre del proyecto — ponle nombre a tu proyecto
- Voz predeterminada — la voz asignada a los nuevos bloques por defecto (puedes cambiarla por bloque)
- Modelo de voz — actualmente S2 Pro (el más reciente)
- Normalización de texto — cuando está habilitada, mejora la precisión de lectura para números, monedas, fechas y textos similares
- Normalización de sonoridad — normaliza los niveles de volumen entre bloques para una salida consistente
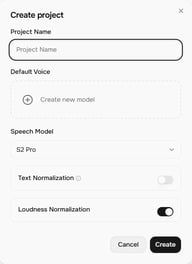
Haz clic en Crear para abrir el editor del proyecto.
Añade bloques y cambia de voz
Tu proyecto se abre con un capítulo predeterminado y un primer bloque de texto ya en su lugar. La voz del primer hablante se muestra como un avatar de color a la izquierda de cada bloque.
Para añadir la línea de un nuevo hablante, haz clic en el botón + debajo de cualquier bloque existente. Aparece un nuevo bloque. Haz clic en el avatar de voz de color en el lado izquierdo del nuevo bloque para abrir el panel de Seleccionar voz y asignar una voz diferente. Escribe la línea del segundo hablante en el bloque.
Repite esto para cada intercambio en tu guion. Cada bloque es el turno de un solo hablante. El panel del lado derecho muestra Voces usadas en el proyecto, una lista en vivo de cada voz asignada actualmente en todos los bloques, para que puedas seguir la pista de tu elenco de un vistazo.
Ajusta con precisión la pausa entre hablantes
Entre cada par de bloques, verás una pequeña burbuja de tiempo que muestra el espacio actual — por ejemplo, 0.35s. Haz clic en ella para ajustar la duración de la pausa entre ese par específico de hablantes.
Esta es una de las características más importantes de Story Studio para el realismo del diálogo. La conversación humana no es una serie de enunciados perfectamente seguidos. Un segundo de silencio antes de una respuesta señala tiempo de procesamiento. Una pausa más larga antes de una respuesta emocional añade peso. Lograr que estos espacios sean correctos es la diferencia entre un audio que suena producido y uno que suena real. Incluso un ajuste de 0.2–0.5s puede cambiar notablemente lo natural que se siente una conversación; vale la pena ajustar cada intercambio individualmente en lugar de dejar todos los espacios por defecto. Ajusta cada pausa entre bloques individualmente para que coincida con el ritmo de la escena.
Añade capítulos para proyectos largos
En el lado izquierdo del editor, verás el panel de Capítulos. Por defecto, cada proyecto comienza con un único "Capítulo predeterminado". Haz clic en + para añadir un nuevo capítulo.
Los capítulos te permiten dividir proyectos largos en secciones navegables: un capítulo por sección de audiolibro, uno por segmento de podcast o uno por escena en el guion de un juego. Cada capítulo tiene su propia secuencia de bloques y se puede trabajar de forma independiente. La exportación final combina todos los capítulos en una sola salida, en orden.
Para cualquier cosa que supere unas pocas cientos de palabras de diálogo, los capítulos son la forma de mantener un proyecto de Story Studio organizado y editable.
TTS vs Story Studio — ¿Cuál deberías usar?
| Texto a voz | Story Studio | |
|---|---|---|
| Método multispeaker | Nativo (nivel de modelo S2 Pro) | Generación secuencial de bloques |
| Límite de caracteres | Depende del plan | Sin límite (multi-capítulo) |
| Número de hablantes | Hasta 5 | Ilimitado |
| Control de pausa entre hablantes | ❌ | ✅ Preciso, por bloque |
| Gestión de capítulos | ❌ | ✅ |
| Vista de línea de tiempo | ❌ | ✅ |
| Ideal para | Diálogos cortos, anuncios, demos | Audiolibros, podcasts, guiones de juegos, producciones largas |
La diferencia técnica clave: TTS utiliza la capacidad nativa multispeaker de S2 Pro — los múltiples hablantes se manejan a nivel de modelo en una sola generación. Story Studio logra la salida multispeaker secuenciando bloques generados por separado, cada uno con su propia voz asignada, en un archivo continuo.
Si estás generando un anuncio de 30 segundos con dos hablantes o un clip de diálogo corto, empieza en TTS — es más rápido y no requiere configuración de proyecto. Si tu guion es más largo, involucra más de unos pocos intercambios o necesita un tiempo preciso entre hablantes, abre Story Studio en su lugar.
Casos de uso — ¿Qué puedes crear con el TTS multispeaker?
Audiolibros con múltiples personajes
Los audiolibros con un solo narrador funcionan bien para la no ficción. Para la ficción con diálogos, una sola voz leyendo todos los personajes se vuelve difícil de seguir. Con el TTS multispeaker, cada personaje de una escena tiene su propia voz: una voz más profunda y madura para un personaje, una voz más joven y enérgica para otro. La estructura de capítulos de Story Studio se adapta directamente a los capítulos de los libros, haciendo práctico producir títulos completos sin los flujos de trabajo tradicionales de casting y grabación.
Diálogo estilo podcast
Los formatos de podcast con dos anfitriones son una de las estructuras de audio más reconocibles que existen. Con un generador de voz de IA multispeaker para diálogos, puedes producir ese formato a partir de un guion escrito: una voz para cada anfitrión, con pausas controladas que simulan la toma de turnos natural. Esto es particularmente útil para los creadores de contenido que quieren producir audio regular sin programar sesiones de grabación.
Contenido de E-Learning y formación
El contenido educativo se vuelve significativamente más atractivo cuando se entrega como una conversación en lugar de un monólogo. Un intercambio profesor-alumno, un escenario guiado o un formato de preguntas y respuestas pueden guionizarse y producirse con dos o más voces, ayudando a los estudiantes a procesar la información a través del diálogo en lugar de una narración pasiva.
Diálogos de juegos y voces de personajes
Los guiones de juegos suelen tener cientos o miles de líneas repartidas entre varios personajes. Usando Story Studio como generador de voces de múltiples personajes, los desarrolladores de juegos y diseñadores narrativos pueden producir diálogos con voz para prototipos, demos o la producción completa, asignando a cada NPC una voz consistente en cada línea que hable, sin los flujos de trabajo tradicionales de grabación de voz.
Del guion al audio — En una sola sesión
Producir audio con múltiples personajes solía significar contratar actores de voz, coordinar sesiones de grabación y pasar horas en postproducción para unir las tomas. Con el TTS multispeaker, todo ese flujo de trabajo se reduce a una sola sesión: encuentra tus voces en Discovery, organízalas en una Colección, construye tu guion bloque por bloque y exporta.
Para contenido corto, el Texto a voz te permite lograrlo en minutos. Para producciones más largas — audiolibros, series de podcasts, diálogos de juegos — Story Studio te da la estructura y el control de tiempo para producir algo que realmente suene como si hubiera sido interpretado.
🎧 Crea tu primer diálogo de 2 hablantes en menos de 2 minutos →
🎙 Convierte tu guion en un audiolibro con elenco completo usando voces de IA →

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






