Nous avons testé notre TTS à l'aveugle contre tous les concurrents majeurs. Voici les résultats.

Nous avons testé notre TTS à l'aveugle contre tous les concurrents majeurs. Voici les résultats.
Fish Audio a mené un test A/B à l'aveugle de 10 jours sur du trafic de production réel, opposant Fish Audio S2 Pro et S1 à ElevenLabs, Inworld et MiniMax. Plus de 5 000 paires de préférences ont été collectées auprès d'utilisateurs réels qui n'avaient aucune idée de quel fournisseur générait quel audio.
Résumé : Les résultats
Fish Audio S2 Pro se classe n°1 au classement général avec un score Bradley-Terry de 3,07, soit près de 1,7x le score du modèle suivant. Notre ancien modèle, Fish Audio S1 (BT 1,86), a également surpassé tous les fournisseurs tiers au global.
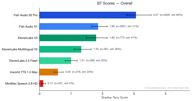
| Rang | Modèle | Score BT | Taux de victoire | Échantillons |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3,07 | 65,7% | 4 573 |
| 2 | Fish Audio S1 | 1,86 | 41,0% | 3 560 |
| 3 | ElevenLabs V3 | 1,80 | 40,6% | 766 |
| 4 | ElevenLabs Multilingual V2 | 1,35 | 36,2% | 359 |
| 5 | ElevenLabs 2.5 Flash | 1,00 | 29,8% | 364 |
| 6 | Inworld TTS 1.5 Max | 0,59 | 20,1% | 373 |
| 7 | MiniMax Speech 2.8 HD | 0,12 | 5,0% | 201 |
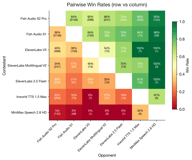
Confrontations directes clés :
- Fish S2 Pro bat ElevenLabs V3 à 60% contre 40% (581 paires)
- Fish S2 Pro bat Inworld à 80% contre 20% (261 paires)
- Fish S2 Pro bat MiniMax à 95% contre 5% (142 paires)
- Fish S1 bat ElevenLabs V3 à 64% contre 36% (150 paires)
Pourquoi nous avons fait cela
Le problème des métriques traditionnelles
Le MOS (Mean Opinion Score) reste la norme de fait pour l'évaluation des TTS, mais il présente de graves lacunes. Les conditions de test sont rarement divulguées — la longueur des échantillons, la démographie des auditeurs, l'environnement de lecture et les instructions de notation varient d'une étude à l'autre, ce qui rend les comparaisons entre publications dénuées de sens. Parallèlement, le WER/CER (taux d'erreur de mots/caractères) peut être contre-productif en tant qu'objectif d'optimisation : pousser le WER trop bas force souvent le modèle vers une parole hyper-articulée et robotique qui sacrifie le naturel et la prosodie au profit de l'intelligibilité. Un modèle qui marmonne occasionnellement comme un véritable humain peut en réalité sembler meilleur qu'un modèle qui énonce parfaitement chaque syllabe.
Le problème des classements existants
Les classements publics comme TTS-Arena-V2 et Artificial Analysis évaluent les modèles sur des phrases courtes et simples — généralement une seule ligne de dialogue ou une brève narration. Cela ne parvient pas à capturer la complexité de l'utilisation réelle du TTS : contenu de longue durée, dialogues multi-locuteurs, balises de prosodie expressives et texte multilingue.
Au-delà de la méthodologie, il existe des préoccupations d'intégrité. TTS-Arena-V2 a connu des problèmes connus de fuite d'en-tête audio, où les métadonnées du fichier audio pouvaient révéler l'identité du fournisseur — brisant ainsi le principe de l'évaluation à l'aveugle. Nous savons également que la manipulation des classements (leaderboard gaming) est répandue : les fournisseurs optimisent spécifiquement pour les phrases de référence, soumettent des versions de modèles triées sur le volet ou gonflent les classements par des votes coordonnés. Ces classements sont devenus des outils marketing plutôt que des signaux de qualité fiables.
Ce que nous voulions réellement
Nous avions besoin d'un signal de récompense interne fiable — une mesure de "vérité de terrain" sur "quel résultat TTS les utilisateurs réels préfèrent-ils réellement ?" sur laquelle nous pourrions compter pour les décisions de développement du modèle. Pas un chiffre tiré d'un article, ni un rang sur un classement manipulable, mais un flux continu de données de préférence honnêtes provenant d'utilisateurs faisant des choix réels.
Nous avons donc intégré un pipeline d'évaluation à l'aveugle directement dans notre plateforme de production.
Conception de l'expérience
Comparaison par paires à l'aveugle
Le studio de Fish Audio présente aux utilisateurs deux versions audio côte à côte pour chaque tâche TTS. Chaque version a indépendamment 10 % de chances d'être silencieusement routée vers un fournisseur concurrent au lieu du backend Fish Audio par défaut. Même texte, même voix de référence, même interface — l'utilisateur n'a aucune idée de quel fournisseur a généré quel audio.
L'expérience s'est déroulée pendant 10 jours (du 26 mars au 5 avril 2026) et a permis de collecter plus de 71 000 groupes de paires, dont 5 098 contenaient des comparaisons entre fournisseurs répondant à nos critères de qualité.
Ce qui compte comme une "victoire"
Nous utilisons un signal comportemental strict, et non une note subjective :
- L'utilisateur doit lire les deux versions au moins 2 fois chacune — confirmant qu'il a réellement comparé les deux.
- Exactement une version est téléchargée — c'est le gagnant.
Ce signal "écouter-puis-télécharger" est bien plus fiable que des notes étoilées ou des enquêtes à choix forcés. Les utilisateurs prennent de réelles décisions concernant l'audio qu'ils utiliseront concrètement.
Composition des utilisateurs
L'expérience a échantillonné environ 70 % de nouveaux utilisateurs et 30 % d'utilisateurs récurrents. Cette composition peut introduire un léger biais en faveur de Fish Audio (les utilisateurs récurrents connaissent déjà notre plateforme), mais elle garantit également que nous capturons les préférences de première impression authentiques de la majorité des participants.
Sélection des voix
Nous avons utilisé les 500 voix publiques les plus populaires de la plateforme pour l'expérience. Chaque voix a été clonée au préalable sur le système du fournisseur tiers, garantissant que la même identité de voix de référence était disponible des deux côtés. Les mappages d'identifiants de voix sont conservés dans des fichiers JSON dédiés qui servent de source unique de vérité pour l'éligibilité du routage.
Fournisseurs et modèles testés
| Fournisseur | Modèle | Cible de routage |
|---|---|---|
| Fish Audio | S2 Pro (dernière version) | fish:s2-pro |
| Fish Audio | S1 (génération précédente) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
Couverture de l'évaluation et support des balises
Tous les fournisseurs ne supportent pas le même ensemble de fonctionnalités. Fish Audio S2 Pro supporte des balises de prosodie riches (ex: [laughs], [sighs]) et des balises de locuteurs (<|speaker:N|>) pour le contenu multi-locuteurs. C'est important car notre trafic de production inclut naturellement du texte avec balises.
- ElevenLabs V3 a reçu l'évaluation la plus complète — il supporte les balises arbitraires après normalisation sous forme de parenthèses, il était donc éligible pour pratiquement toutes les requêtes quel que soit le contenu.
- ElevenLabs 2.5 Flash et Multilingual V2 — nous n'avons envoyé que des requêtes en texte brut à ces modèles (pas de balises).
- Inworld — texte brut uniquement, et limité au format de sortie
mp3, ce qui a encore limité son trafic éligible. - MiniMax — acceptait les balises d'interjection (
(laughs),(sighs), etc.) mais rejetait les autres types de balises. En raison de résultats de préférence utilisateur systématiquement médiocres, l'expérience a été arrêtée prématurément pour éviter de dégrader davantage l'expérience utilisateur.
Le système de routage évalue chaque fournisseur alternatif par rapport aux caractéristiques de la requête actuelle (langue, balises, format, voix multi-références). Seules les alternatives supportées deviennent des candidats éligibles, et l'une d'elles est sélectionnée par choix aléatoire pondéré. Si la seule alternative éligible est une comparaison Fish contre Fish (S1 vs S2 Pro), la probabilité d'échantillonnage effective est réduite à 1/10e du taux de base pour prioriser la collecte de données entre fournisseurs.
Ce que cela nous a coûté
Ces expériences ne sont pas gratuites. Les API de TTS tierces sont coûteuses à grande échelle :
- ElevenLabs : plus de 1 500 $ dépensés en appels API
- MiniMax : 330 $ dépensés (arrêté prématurément en raison de mauvaises performances)
- Inworld : 170 $ dépensés

Méthodologie statistique
Modèle Bradley-Terry
Les taux de victoire bruts peuvent être trompeurs lorsque différents modèles affrontent différents adversaires à des fréquences différentes. Le modèle Bradley-Terry résout ce problème en calculant un score de force global à partir des données de comparaison par paires. Il estime de manière itérative le paramètre de "force" latent de chaque modèle de sorte que la probabilité de victoire prédite entre deux modèles corresponde aux données observées.
Pour deux modèles et avec des scores BT et :
Notre implémentation effectue jusqu'à 500 itérations avec une tolérance de convergence de , en normalisant les scores à l'aide de la moyenne géométrique à chaque étape.
Intervalles de confiance
Nous rapportons des intervalles de confiance bootstrap à 95 % calculés à partir de 200 rééchantillonnages des données de paires de préférences. Chaque rééchantillonnage tire paires avec remplacement à partir des paires originales et relance le calcul complet de BT. Les 2,5e et 97,5e centiles des scores bootstrappés forment les bornes de l'intervalle de confiance.
Pour les taux de victoire par backend, nous utilisons les intervalles de score de Wilson qui offrent une meilleure couverture que les intervalles d'approximation normale pour les taux de victoire extrêmes.
Résultats par langue
Langues à alphabet latin (Anglais, Espagnol, Français, Allemand, ...)
Les langues à alphabet latin représentent le segment le plus important avec 4 173 paires de préférences.
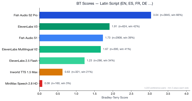
Fish S2 Pro est en tête à 3,05. Notamment, ElevenLabs V3 (1,90) surpasse légèrement Fish S1 (1,72) dans cette catégorie — le seul groupe linguistique où un concurrent dépasse notre ancien modèle. ElevenLabs Multilingual V2 affiche également de bonnes performances à 1,70, juste derrière S1.
C'est logique : ElevenLabs s'est historiquement concentré sur l'anglais et les langues européennes, et leur modèle V3 est performant dans ce domaine. Pourtant, Fish S2 Pro maintient un avantage de 1,6x sur ElevenLabs V3.
Chinois
Le chinois compte 329 paires de préférences et montre la dominance la plus spectaculaire de Fish Audio.
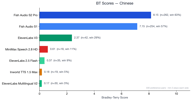
Les deux modèles Fish Audio (S2 Pro à 8,11, S1 à 7,11) surpassent massivement tous les concurrents. ElevenLabs V3 obtient 2,36 — un score respectable mais loin derrière. Tous les autres concurrents sont en dessous de 1,0.
Japonais
Le japonais compte 354 paires de préférences.
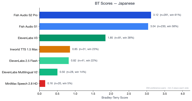
Fish S2 Pro (3,12) et Fish S1 (3,02) sont très proches, tous deux loin devant ElevenLabs V3 (1,88). L'écart entre les modèles Fish et les concurrents est le plus important dans les langues CJK (Chinois, Japonais, Coréen).
Résumé inter-langues
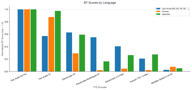
Fish Audio S2 Pro se classe n°1 dans chaque catégorie de langue. L'écart concurrentiel varie :
- Alphabet latin : Les concurrents sont les plus proches, ElevenLabs V3 est réellement compétitif (score relatif 0,62).
- Chinois : La domination de Fish Audio est écrasante, les concurrents existent à peine.
- Japonais : Similaire au chinois — les modèles Fish sont loin devant.
Limites
Utilisateurs API exclus
Pour garantir la stabilité de la plateforme, les utilisateurs de l'API n'ont pas été inclus dans l'expérience. Le taux d'échantillonnage de 10 % s'applique uniquement aux utilisateurs de la plateforme web. Cela signifie que nos résultats reflètent les modèles d'utilisation de la plateforme web, qui peuvent différer des charges de travail de production axées sur l'API.
Le support des balises crée une couverture inégale
Étant donné que les fournisseurs tiers ont des supports de balises variés, ils ont reçu différents sous-ensembles de trafic :
- ElevenLabs V3 était éligible pour presque toutes les requêtes (supporte les balises).
- ElevenLabs Flash/Multilingual n'ont reçu que des requêtes sans balises.
- Inworld n'a reçu que des requêtes sans balises au format mp3.
Cela signifie que le terrain de compétition n'est pas parfaitement équitable. Les résultats d'ElevenLabs V3 sont les plus directement comparables à ceux de Fish Audio car il a reçu l'échantillon de trafic le plus représentatif. D'autres modèles ont été évalués sur un sous-ensemble qui tend vers des requêtes plus simples en texte brut — ce qui, en théorie, devrait les favoriser.
Les résultats de MiniMax peuvent être peu fiables
MiniMax Speech 2.8 HD a obtenu des scores extraordinairement bas (BT 0,12, taux de victoire de 5 % — même contre Inworld). Nous soupçonnons que notre intégration de l'API MiniMax n'est peut-être pas optimale. Après avoir écouté plusieurs échantillons générés par MiniMax, nous n'avons pas pu identifier de problème technique spécifique — l'audio était intelligible mais présentait une prosodie et un naturel nettement moins bons que tous les autres fournisseurs. Nous avons élargi l'éligibilité du routage MiniMax en cours d'expérience pour augmenter la taille de l'échantillon, mais les performances ne se sont pas améliorées. L'expérience a été arrêtée prématurément après avoir accumulé 330 $ en frais d'API sans aucun signe de résultats compétitifs.
Si MiniMax estime que ces résultats ne reflètent pas la véritable capacité de leur modèle, nous accueillons volontiers un examen collaboratif de notre intégration.
Contraintes de mappage des voix
Seules les voix ayant réussi un clonage sur la plateforme tierce peuvent être routées. Si un clonage de voix a échoué, cette voix a été exclue du pool éligible de ce fournisseur. Cela signifie que chaque fournisseur a été testé sur un sous-ensemble légèrement différent (bien que largement superposé) des 500 voix les plus populaires.
Biais possible lié à la familiarité avec la plateforme
Bien que nous ayons échantillonné environ 70 % de nouveaux utilisateurs, les 30 % restants d'utilisateurs récurrents ont pu développer des préférences alignées sur les caractéristiques audio de Fish Audio. Nous pensons que cet effet est minime compte tenu de la composition majoritaire de nouveaux utilisateurs, mais il ne peut être totalement exclu.
Conclusion
Nous pensons qu'il s'agit de l'une des évaluations publiques les plus rigoureuses de la qualité TTS jamais réalisées :
- Utilisateurs réels, et non des annotateurs rémunérés.
- Comparaison à l'aveugle — les utilisateurs ne savent jamais quel fournisseur a généré quel audio.
- Signal comportemental (téléchargement) plutôt que notations subjectives.
- Trafic de production avec une complexité de texte réelle, incluant du contenu long, des balises de prosodie et du texte multilingue.
- Plus de 5 000 paires de préférences dans plusieurs langues, collectées sur 10 jours.
- Plus de 2 000 $ dépensés uniquement en appels API tiers.
Les résultats sont clairs : Fish Audio S2 Pro est le modèle TTS préféré dans toutes les langues testées, avec des avantages particulièrement marqués en chinois et en japonais. Même notre modèle S1 de génération précédente surpasse tous les concurrents au global.
Ces résultats valident davantage notre feuille de route pour la modélisation de bout en bout et le RLHF (Reinforcement Learning from Human Feedback). Nous nous engageons à la transparence. La méthodologie, la logique de routage et le code d'analyse font partie de l'infrastructure de notre plateforme. Nous invitons la communauté TTS à examiner notre approche et à suggérer des améliorations pour les futures évaluations.
Cette évaluation a été menée par l'équipe Fish Audio du 26 mars au 5 avril 2026. Pour toute question ou pour discuter de la méthodologie, contactez-nous sur fish.audio.








