Fish Audio lance S2 en open-source : quand le contrôle granulaire rencontre le streaming de production
9 mars 2026
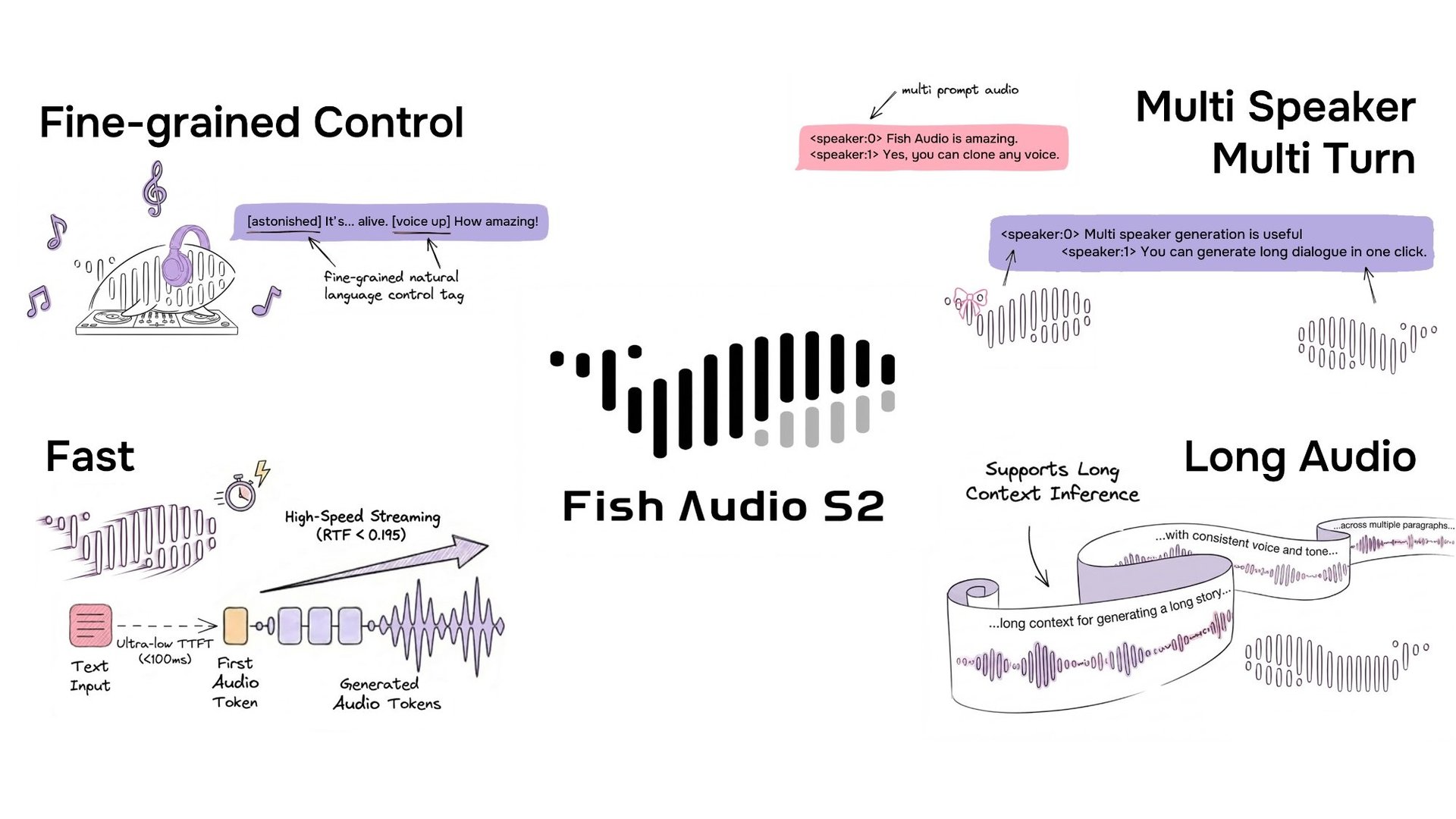
S2 est disponible en open-source via le dépôt GitHub du projet et sur HuggingFace.
Fish Audio a mis en open-source S2, un modèle de synthèse vocale qui prend en charge un contrôle en ligne granulaire de la prosodie et des émotions à l'aide de balises en langage naturel telles que [laugh], [whispers] et [super happy]. Entraîné sur plus de 10 millions d'heures d'audio dans environ 50 langues, le système combine l'alignement par apprentissage par renforcement avec une architecture doublement autorégressive. La version comprend les poids du modèle, le code de réglage fin (fine-tuning) et un moteur d'inférence de streaming basé sur SGLang.
Contrôle en ligne granulaire via le langage naturel
S2 permet un contrôle en ligne de la génération de la parole en intégrant des instructions en langage naturel directement à des positions spécifiques de mots ou de phrases dans le texte. Plutôt que de s'appuyer sur un ensemble fixe de balises prédéfinies, S2 accepte des descriptions textuelles libres — telles que [whisper in small voice], [professional broadcast tone] ou [pitch up] — permettant un contrôle de l'expression illimité au niveau du mot.
Sur le Test de Turing Audio, S2 atteint une moyenne a posteriori de 0,515 avec la réécriture d'instructions, contre 0,417 pour Seed-TTS et 0,387 pour MiniMax-Speech. Sur EmergentTTS-Eval, il atteint un taux de victoire global de 81,88 % par rapport à une base de référence gpt-4o-mini-tts — le plus élevé parmi tous les modèles évalués, y compris les systèmes propriétaires de Google et OpenAI.
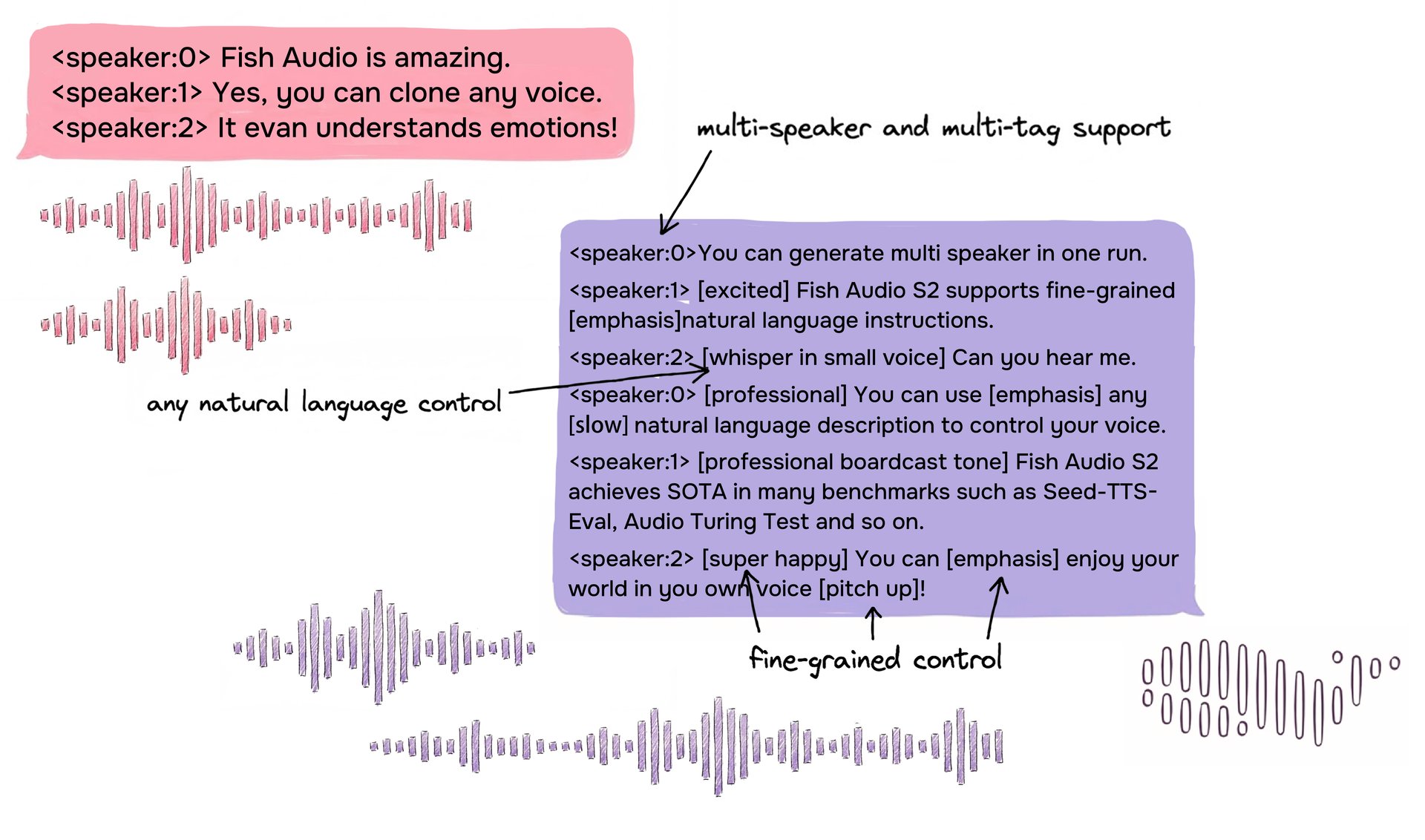 Exemple de format d'entrée S2 montrant un dialogue multi-locuteurs avec des balises en ligne en langage naturel libre pour un contrôle granulaire.
Exemple de format d'entrée S2 montrant un dialogue multi-locuteurs avec des balises en ligne en langage naturel libre pour un contrôle granulaire.
Une recette unifiée : curation des données et récompenses RL issus des mêmes modèles
Une décision architecturale centrale dans S2 est que les mêmes modèles utilisés pour filtrer et annoter les données d'entraînement sont directement réutilisés comme modèles de récompense pendant l'apprentissage par renforcement (RL) :
- Modèle de qualité de la parole : évalue l'audio selon des dimensions telles que le SNR, la cohérence du locuteur et l'intelligibilité pendant le filtrage des données — puis sert de récompense de préférence acoustique pendant le RL.
- Modèle ASR à transcription enrichie (pré-entraînement continu à partir de Qwen3-Omni-30B-A3B) : génère des transcriptions augmentées de légendes avec des annotations paralinguistiques en ligne pendant la curation des données — puis fournit la récompense d'intelligibilité et de suivi d'instructions en re-transcrivant l'audio généré et en le comparant au prompt original.
Cette conception à double usage élimine par construction le décalage de distribution entre les données de pré-entraînement et les objectifs de post-entraînement — un problème qui reste non résolu dans d'autres systèmes TTS qui entraînent des modèles de récompense séparément de leurs pipelines de données.
Au cœur du modèle : l'architecture Dual-AR
S2 s'appuie sur un transformateur de type décodeur uniquement combiné à un codec audio basé sur RVQ (10 livres de codes, fréquence de trame ~21 Hz). L'aplatissement de tous les livres de codes sur l'axe temporel provoquerait une explosion de la longueur de séquence par 10. S2 résout ce problème avec une architecture doublement autorégressive (Dual-AR) :
- Slow AR : opère le long de l'axe temporel et prédit le livre de codes sémantique principal.
- Fast AR : génère les 9 livres de codes résiduels restants à chaque étape temporelle, reconstruisant les détails acoustiques fins.
Cette conception asymétrique — 4 milliards de paramètres le long de l'axe temporel, 400 millions de paramètres le long de l'axe de profondeur — permet de maintenir l'efficacité de l'inférence tout en préservant la fidélité audio.
Alignement par apprentissage par renforcement pour la parole
Pour le post-entraînement, S2 utilise l'optimisation de politique relative de groupe (GRPO), choisie pour éviter la surcharge mémoire des modèles de valeur de style PPO dans les contextes audio longs. Le signal de récompense combine plusieurs dimensions, notamment :
- Précision sémantique et respect des instructions
- Évaluation de la préférence acoustique
- Similarité du timbre
Résultats des benchmarks
S2 obtient des résultats de premier plan sur plusieurs benchmarks publics :
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chinois) | 0,54 % (meilleur score global) |
| Seed-TTS Eval — WER (Anglais) | 0,99 % (meilleur score global) |
| Test de Turing Audio (avec instruction) | 0,515 (moyenne a posteriori) |
| EmergentTTS-Eval — Taux de victoire | 81,88 % (plus élevé au total) |
| Fish Instruction Benchmark — TAR | 93,3 % |
| Fish Instruction Benchmark — Qualité | 4,51 / 5,0 |
| Multilingue (MiniMax Testset) — Meilleur WER | 11 des 24 langues |
| Multilingue (MiniMax Testset) — Meilleure SIM | 17 des 24 langues |
Sur Seed-TTS Eval, S2 affiche le WER le plus bas parmi tous les modèles évalués, y compris les systèmes propriétaires : Qwen3-TTS (0,77/1,24), MiniMax Speech-02 (0,99/1,90), Seed-TTS (1,12/2,25). Sur le Test de Turing Audio, le score de 0,515 surpasse Seed-TTS (0,417) de 24 % et MiniMax-Speech (0,387) de 33 %. Sur EmergentTTS-Eval, S2 obtient des résultats particulièrement solides en paralinguistique (taux de victoire de 91,61 %), pour les questions (84,41 %) et la complexité syntaxique (83,39 %).
Streaming de production via SGLang
Comme l'architecture Dual-AR de S2 est structurellement isomorphe aux LLM autorégressifs standards, elle peut directement hériter de toutes les optimisations de service natives des LLM de SGLang avec un minimum de modifications — y compris le traitement par lots continu (continuous batching), le cache KV paginé, le replay de graphe CUDA et la mise en cache des préfixes basée sur RadixAttention.
Pour le clonage de voix, S2 place les jetons audio de référence dans le prompt système. La fonction RadixAttention de SGLang met automatiquement en cache ces états KV, atteignant un taux de réussite moyen du cache de préfixes de 86,4 % (plus de 90 % en pic) lorsque la même voix est réutilisée entre les requêtes — rendant la surcharge de pré-remplissage de l'audio de référence presque négligeable.
Sur un seul GPU NVIDIA H200 :
- Facteur Temps Réel (RTF) : 0,195
- Temps avant le premier audio : environ 100 ms
- Débit : plus de 3 000 jetons acoustiques/s tout en maintenant un RTF inférieur à 0,5
Pourquoi cette sortie est importante
S2 n'est pas seulement publié comme un checkpoint de modèle, mais comme un système complet : poids du modèle, code de réglage fin et une pile d'inférence prête pour la production.
Deux choix de conception se démarquent. Premièrement, le pipeline unifié de données et de récompenses élimine un problème structurel — le décalage de distribution entre le pré-entraînement et le RL — que d'autres systèmes TTS n'ont pas abordé au niveau architectural. Deuxièmement, l'isomorphisme structurel entre l'architecture Dual-AR et les LLM standards signifie que S2 peut tirer parti de tout l'écosystème d'optimisations de service des LLM, plutôt que de nécessiter une infrastructure d'inférence personnalisée.
S2 est disponible via le répertoire GitHub du projet, SGLang-Omni, HuggingFace, et une démo interactive sur fish.audio.



