Synthèse Vocale avec Plusieurs Voix — Guide Complet du Multi-locuteur (Fish Audio)

La synthèse vocale (TTS) à voix unique manque de relief pour les dialogues, les livres audio et les podcasts. Ce guide vous montre comment trouver et organiser des voix sur Fish Audio, puis utiliser le mode multi-locuteur dans TTS et Story Studio pour produire des fichiers audio naturels à plusieurs personnages — sans les flux de travail traditionnels d'enregistrement vocal.
Mars 2026 | Le TTS multi-locuteur de Fish Audio est désormais disponible sur S2 Pro
Table des matières
- Qu'est-ce que la synthèse vocale multi-locuteur ?
- Étape 1 — Trouver les bonnes voix avec Discovery
- Étape 2 — Le multi-locuteur dans Text to Speech
- Étape 3 — Le multi-locuteur dans Story Studio
- TTS vs Story Studio — Lequel utiliser ?
- Cas d'utilisation — Que pouvez-vous créer avec le TTS multi-locuteur ?
- Du script à l'audio — En une seule session
- FAQ sur le TTS multi-locuteur
La plupart des outils de synthèse vocale ne vous proposent qu'une seule voix. Un narrateur. Un seul ton, du début à la fin. Pour une explication simple avec un seul locuteur, cela fonctionne bien. Mais dès que votre script implique deux personnages qui discutent, un hôte et un invité, ou une histoire avec des rôles distincts, une voix unique transforme le dialogue en une lecture plate et monotone. Les auditeurs se décrochent rapidement.
La synthèse vocale avec plusieurs voix résout ce problème. Attribuez une voix IA différente à chaque locuteur, contrôlez le rythme entre eux, et le résultat est une conversation qui sonne vraiment comme telle. Fish Audio fonctionne comme un générateur complet de dialogues par synthèse vocale — couvrant tout, de la découverte de voix aux exports multi-chapitres. Ce guide vous accompagne tout au long du flux de travail : comment découvrir et organiser les voix, comment utiliser le mode multi-locuteur dans l'outil Text to Speech pour les contenus courts, et comment passer à des productions complètes dans Story Studio.
Qu'est-ce que la synthèse vocale multi-locuteur ?
Le texte-parole multi-locuteur est un flux de travail TTS où différents segments d'un script sont attribués à différentes voix IA — chacune avec son propre ton, sexe, âge et style de parole — puis générés sous forme d'une sortie audio unique et continue.
Les outils TTS traditionnels sont conçus autour d'un modèle de narration unique : une voix, une entrée de texte, un fichier audio. Cette conception fonctionne pour la narration de livres audio avec un seul narrateur, des voix off ou des annonces. Elle échoue totalement pour tout ce qui implique un dialogue. Pour produire une conversation entre deux personnages avec des outils obsolètes, vous devriez générer chaque locuteur séparément, puis assembler manuellement l'audio dans un éditeur — en ajustant le rythme, en égalisant les niveaux sonores et en espérant que les transitions ne ressemblent pas à deux enregistrements différents.
Le problème n'est pas seulement les étapes supplémentaires. C'est que le timing entre les locuteurs est presque impossible à obtenir correctement sans commandes dédiées. Une vraie conversation a un rythme : un temps de silence avant une réponse, un léger chevauchement quand quelqu'un interrompt, une pause plus longue avant une réponse difficile. Sans un contrôle précis sur les écarts entre les locuteurs, même un dialogue bien choisi sonne robotique.
Les outils TTS multi-locuteurs répondent à ces deux problèmes. Chaque locuteur possède sa propre voix et son propre bloc de texte. Les écarts entre les locuteurs sont ajustables. La sortie finale est un fichier audio unique et cohérent — avec le timing déjà intégré.
La synthèse vocale multi-locuteur vous permet de :
- Attribuer une voix IA différente à chaque locuteur dans un script
- Contrôler le timing et les pauses entre chaque locuteur
- Générer un dialogue entier sous la forme d'un fichier audio unique et continu
- Passer d'un échange entre deux personnages à une distribution complète — sans exports supplémentaires ni montage manuel
Étape 1 — Trouver les bonnes voix avec Discovery
Avant de pouvoir construire un projet multi-locuteur, vous avez besoin de voix. La page Discovery de Fish Audio est l'endroit où vous les trouverez — et avec des milliers de voix dans la bibliothèque, les outils de filtrage sont essentiels.
Allez sur fish.audio/app/discovery/.
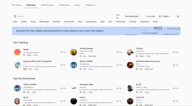
Rechercher et filtrer
La page Discovery s'ouvre avec une barre de recherche, des étiquettes de filtre rapide sur la rangée supérieure, et des commandes de tri et de langue sur la droite.
Recherchez par nom si vous savez déjà ce que vous cherchez. Triez par Recommandé ou Tendances pour faire remonter ce qui fonctionne pour les autres créateurs. Langue filtre l'ensemble de la bibliothèque pour n'afficher que les voix formées dans votre langue cible.
Les étiquettes de filtre rapide couvrent les attributs les plus courants — Homme, Femme, Jeune, Moyen âge, Narration, Réseaux sociaux, Grave, Doux, Professionnel, Dramatique, Mystérieux, Anime — et vous pouvez les combiner. Sélectionner Femme + Jeune + Narration limitera immédiatement les résultats aux voix qui correspondent à ce profil.

Pour plus de contrôle, ouvrez le panneau de filtrage (l'icône des curseurs en haut à droite). Cela vous donne :
- Langues — restreindre à une langue spécifique, avec correspondance multilingue
- Étiquettes — étiquettes libres ajoutées par les créateurs de voix
- Sexe — Homme, Femme, Neutre
- Âge — Jeune, Moyen âge, Vieux
- Cas d'utilisation — Conversationnel, Narration, Voix de personnage, Réseaux sociaux, Éducatif, Publicité, et plus encore
- Qualités de la voix — Profonde, Basse, Moyenne, Haute, Douce, Brillante, et plus de 48 descripteurs supplémentaires
Pour un projet multi-locuteur, les filtres Cas d'utilisation et Qualités de la voix sont particulièrement utiles. Si vous construisez un dialogue de type podcast, vous pourriez vouloir une voix Conversationnelle + Douce et une voix Narration + Profonde — suffisamment distinctes pour que les auditeurs puissent les différencier sans avoir besoin de voir la transcription.
Aimer, mettre en favori et enregistrer dans une collection
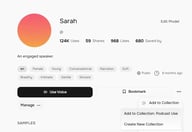
Quand vous trouvez une voix que vous souhaitez réutiliser, vous avez plusieurs façons de l'enregistrer. L'icône de cœur sur chaque fiche de voix est un "J'aime" rapide — cela ajoute la voix à votre onglet Likes pour référence ultérieure.
Pour un enregistrement plus durable, ouvrez la page de détail de la voix et cliquez sur Bookmark (Favori). Les voix Bookmarked apparaissent dans l'onglet Bookmarks, séparées de vos likes, et sont accessibles directement depuis le sélecteur de voix dans TTS et Story Studio.
Pour une organisation au niveau du projet, les Collections sont l'option la plus puissante. Cliquez sur Collections dans la navigation supérieure, puis sur Create Collection pour configurer un groupe nommé — par exemple, "Utilisation Podcast" ou "Projet Livre Audio A". Donnez-lui un titre et une description, puis cliquez sur Create.

Pour ajouter une voix à une collection, ouvrez la page de détail de la voix, cliquez sur le menu à trois points (⋯) à côté du bouton Bookmark, et sélectionnez Add to Collection. Si vous avez déjà créé une collection, elle apparaîtra dans le menu déroulant — un clic suffit pour ajouter la voix.
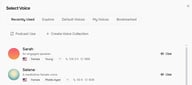
L'avantage se concrétise lorsque vous êtes dans TTS ou Story Studio. Lorsque vous ouvrez le panneau Select Voice, vos collections apparaissent sous forme d'onglets en haut — juste à côté de Recently Used, Explore, Default Voices, My Voices et Bookmarked. Au lieu de chercher à partir de zéro à chaque session, les voix de votre projet sont déjà regroupées et prêtes.
Étape 2 — Le multi-locuteur dans Text to Speech
L'outil Text to Speech de Fish Audio prend en charge plusieurs locuteurs dans une seule génération. C'est l'outil idéal pour les contenus courts à moyens — extraits de dialogue, publicités, courtes intros de podcast, scripts de démonstration et tout ce qui nécessite un résultat rapide et soigné sans gestion de chapitres. Si vous n'avez pas encore trouvé vos voix, commencez par parcourir la bibliothèque Discovery.
Allez sur fish.audio/app/text-to-speech/.
Configurer votre premier locuteur
Lorsque vous ouvrez TTS, vous verrez un bloc de texte unique avec un sélecteur de voix en haut. Cliquez sur le nom de la voix pour ouvrir le panneau Select Voice et choisissez votre premier locuteur. Tapez ou collez les lignes du premier locuteur dans le bloc de texte.
Vous pouvez également utiliser des balises d'émotion en ligne pour façonner l'interprétation — [sad], [emphasis], [excited] — placées directement dans le texte avant les mots qu'elles doivent affecter.
Ajouter d'autres locuteurs
Cliquez sur + Add Speaker sous le premier bloc de texte. Un nouveau bloc apparaît, avec son propre sélecteur de voix indépendant. Choisissez une voix différente pour ce locuteur, entrez ses répliques, et les deux blocs seront générés comme un seul fichier audio continu — dans l'ordre où ils apparaissent à l'écran.
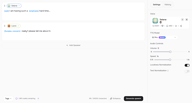
Il n'y a pas de limite supérieure au nombre de locuteurs que vous pouvez ajouter. Chaque bloc est indépendant : voix différente, texte différent, balises d'émotion différentes si nécessaire. En pratique, la plupart des projets de dialogue fonctionnent bien avec 2 à 4 voix distinctes — assez de variété pour être clair, sans devenir difficile à suivre. Sur le panneau de droite, vous pouvez affiner le Volume, la Vitesse (Speed), la Normalisation du volume (Loudness Normalization) et la Normalisation du texte (Text Normalization) (qui améliore la précision de lecture pour les nombres, les devises et les textes formatés similaires) avant de générer.
Limite de caractères et quand passer à Story Studio
Surveillez le compteur de caractères en bas de l'écran. La limite dépend de votre forfait — consultez les limites de tarification et de forfait Fish Audio pour l'allocation spécifique de votre niveau. Pour les contenus courts et de longueur moyenne, le TTS est le flux de travail le plus rapide et le plus simple. Mais si vous travaillez sur quelque chose de plus long — un chapitre entier de livre audio, un podcast à plusieurs segments, un script de dialogue de jeu — c'est là que Story Studio vous offre les outils dont vous avez réellement besoin.
Étape 3 — Le multi-locuteur dans Story Studio
Story Studio est conçu pour la production audio de longue durée. Là où le TTS est optimisé pour une génération rapide, Story Studio vous offre un environnement structuré pour séquencer plusieurs voix bloc par bloc — avec un contrôle précis sur le timing entre les locuteurs et une organisation par chapitres pour les projets complexes. Chaque bloc est généré indépendamment avec sa propre voix attribuée, et l'exportation finale les assemble en un seul fichier continu. Allez sur fish.audio/app/story-studio/.
Créer un nouveau projet
Cliquez sur + Project sur l'écran d'accueil de Story Studio. La boîte de dialogue Create project s'ouvre avec ces paramètres :
- Project Name — nommez votre projet
- Default Voice — la voix attribuée par défaut aux nouveaux blocs (vous pouvez la changer par bloc)
- Speech Model — actuellement S2 Pro (le plus récent)
- Text Normalization — lorsqu'elle est activée, améliore la précision de lecture pour les chiffres, les devises, les dates et les textes similaires
- Loudness Normalization — normalise les niveaux de volume entre les blocs pour une sortie cohérente
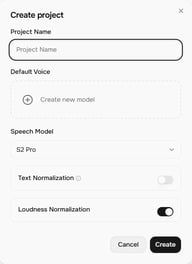
Cliquez sur Create pour ouvrir l'éditeur de projet.
Ajouter des blocs et changer de voix
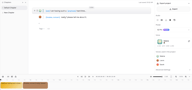
Votre projet s'ouvre avec un chapitre par défaut et un premier bloc de texte déjà en place. La voix du premier locuteur est affichée sous forme d'un avatar coloré à gauche de chaque bloc.
Pour ajouter la réplique d'un nouveau locuteur, cliquez sur le bouton + sous n'importe quel bloc existant. Un nouveau bloc apparaît. Cliquez sur l'avatar de voix coloré sur le côté gauche du nouveau bloc pour ouvrir le panneau Select Voice et attribuer une voix différente. Saisissez la réplique du deuxième locuteur dans le bloc.
Répétez l'opération pour chaque échange de votre script. Chaque bloc correspond au tour de parole d'un locuteur. Le panneau de droite affiche Voices used in the project — une liste en temps réel de chaque voix actuellement attribuée à travers tous les blocs, vous permettant de suivre votre distribution d'un coup d'œil.
Ajuster la pause entre les locuteurs
Entre chaque paire de blocs, vous verrez une petite bulle de timing indiquant l'écart actuel — par exemple, 0.35s. Cliquez dessus pour ajuster la durée de la pause entre cette paire spécifique de locuteurs.
C'est l'une des fonctionnalités les plus importantes de Story Studio pour le réalisme des dialogues. Une conversation humaine n'est pas une série d'énoncés parfaitement enchaînés. Un temps de silence avant une réponse signale un temps de réflexion. Une pause plus longue avant une réponse émotionnelle ajoute du poids. Régler correctement ces écarts fait la différence entre un audio qui semble produit et un audio qui semble réel. Même un ajustement de 0,2 à 0,5 s peut modifier sensiblement le naturel d'une conversation — il vaut la peine d'ajuster chaque échange individuellement plutôt que de laisser tous les écarts par défaut. Ajustez chaque pause entre les blocs individuellement pour correspondre au rythme de la scène.
Ajouter des chapitres pour les projets longs
Sur le côté gauche de l'éditeur, vous verrez le panneau Chapters. Par défaut, chaque projet commence par un seul "Default Chapter". Cliquez sur + pour ajouter un nouveau chapitre.
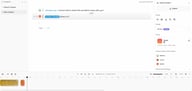
Les chapitres vous permettent de diviser les longs projets en sections navigables — un chapitre par section de livre audio, un par segment de podcast ou un par scène dans un script de jeu. Chaque chapitre a sa propre séquence de blocs et peut être travaillé indépendamment. L'exportation finale combine tous les chapitres en une seule sortie, dans l'ordre.
Pour tout ce qui dépasse quelques centaines de mots de dialogue, les chapitres sont le moyen de garder un projet Story Studio organisé et éditable.
TTS vs Story Studio — Lequel utiliser ?
| Text to Speech | Story Studio | |
|---|---|---|
| Méthode multi-locuteur | Native (niveau modèle S2 Pro) | Génération séquentielle de blocs |
| Limite de caractères | Selon le forfait | Aucune limite (multi-chapitres) |
| Nombre de locuteurs | Jusqu'à 5 | Illimité |
| Contrôle des pauses | ❌ | ✅ Précis, par bloc |
| Gestion des chapitres | ❌ | ✅ |
| Vue chronologique | ❌ | ✅ |
| Idéal pour | Dialogues courts, pubs, démos | Livres audio, podcasts, scripts de jeux, productions longues |
La principale différence technique : TTS utilise la capacité native multi-locuteur de S2 Pro — plusieurs locuteurs sont gérés au niveau du modèle en une seule génération. Story Studio obtient un résultat multi-locuteur en séquençant des blocs générés séparément, chacun avec sa propre voix attribuée, en un seul fichier continu.
Si vous générez une publicité de 30 secondes avec deux locuteurs ou un court clip de dialogue, commencez dans TTS — c'est plus rapide et ne nécessite aucune configuration de projet. Si votre script est plus long, implique plus de quelques échanges ou nécessite un timing précis entre les locuteurs, ouvrez plutôt Story Studio.
Cas d'utilisation — Que pouvez-vous créer avec le TTS multi-locuteur ?
Livres audio avec plusieurs personnages
Les livres audio à narrateur unique fonctionnent bien pour la non-fiction. Pour la fiction avec dialogues, une voix unique lisant tous les personnages devient difficile à suivre. Avec le TTS multi-locuteur, chaque personnage d'une scène a sa propre voix — une voix plus grave et plus âgée pour un personnage, une voix plus jeune et plus énergique pour un autre. La structure en chapitres de Story Studio correspond directement aux chapitres d'un livre, ce qui permet de produire des titres complets sans les flux de travail traditionnels de casting et d'enregistrement.
Dialogues de type podcast
Les formats de podcast à deux hôtes sont l'une des structures audio les plus reconnaissables. Avec un générateur de voix IA multi-locuteur pour les dialogues, vous pouvez produire ce format à partir d'un script écrit — une voix pour chaque hôte, avec des pauses contrôlées qui simulent une prise de parole naturelle. Ceci est particulièrement utile pour les créateurs de contenu qui souhaitent produire régulièrement du contenu audio sans planifier de sessions d'enregistrement.
E-Learning et contenu de formation
Le contenu pédagogique devient nettement plus attrayant lorsqu'il est présenté comme une conversation plutôt que comme un monologue. Un échange enseignant-élève, un scénario guidé ou un format Q&R peuvent tous être scénarisés et produits avec deux voix ou plus — aidant les apprenants à traiter l'information via un dialogue plutôt que par une narration passive.
Dialogues de jeux et voix de personnages
Les scripts de jeux comportent souvent des centaines ou des milliers de lignes réparties sur plusieurs personnages. En utilisant Story Studio comme générateur de voix pour personnages multiples, les développeurs de jeux et les concepteurs narratifs peuvent produire des dialogues vocaux pour le prototypage, les démos ou la production complète — avec chaque PNJ recevant une voix cohérente sur chaque ligne prononcée, sans les flux de travail traditionnels d'enregistrement vocal.
Du script à l'audio — En une seule session
Produire un audio multi-personnages signifiait autrefois réserver des acteurs vocaux, coordonner des sessions d'enregistrement et passer des heures en post-production pour assembler les prises. Avec le TTS multi-locuteur, tout ce flux de travail se réduit à une seule session : trouvez vos voix dans Discovery, organisez-les dans une Collection, construisez votre script bloc par bloc et exportez.
Pour les contenus courts, Text to Speech vous y amène en quelques minutes. Pour les productions plus longues — livres audio, séries de podcasts, dialogues de jeux — Story Studio vous offre la structure et le contrôle du rythme pour produire quelque chose qui semble réellement avoir été interprété par des acteurs.
🎧 Créez votre premier dialogue à 2 locuteurs en moins de 2 minutes →
🎙 Transformez votre script en un livre audio avec une distribution complète grâce aux voix IA →

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






