自社TTSを主要な全競合他社とブラインドテストしました。その結果を公開します。

自社TTSを主要な全競合他社とブラインドテストしました。その結果を公開します。
Fish Audioは、実際のプロダクショントラフィックにおいて10日間のブラインドA/Bテストを実施し、Fish Audio S2 ProおよびS1をElevenLabs、Inworld、MiniMaxと比較しました。プロバイダーが特定できない状態で生成された音声に対し、実際のユーザーから5,000組以上の好みのデータが収集されました。
要約:結果
Fish Audio S2 Proはブラッドリー・テリー・スコアで3.07を記録し、次位のモデルに約1.7倍の差をつけて総合1位となりました。旧モデルであるFish Audio S1(BT 1.86)も、集計においてすべてのサードパーティプロバイダーを上回るパフォーマンスを示しました。
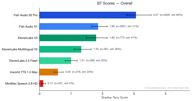
| 順位 | モデル | BTスコア | 勝率 | サンプル数 |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3.07 | 65.7% | 4,573 |
| 2 | Fish Audio S1 | 1.86 | 41.0% | 3,560 |
| 3 | ElevenLabs V3 | 1.80 | 40.6% | 766 |
| 4 | ElevenLabs Multilingual V2 | 1.35 | 36.2% | 359 |
| 5 | ElevenLabs 2.5 Flash | 1.00 | 29.8% | 364 |
| 6 | Inworld TTS 1.5 Max | 0.59 | 20.1% | 373 |
| 7 | MiniMax Speech 2.8 HD | 0.12 | 5.0% | 201 |
主な直接対決の結果:
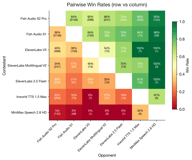
- Fish S2 ProはElevenLabs V3に**60%対40%**で勝利(581ペア)
- Fish S2 ProはInworldに**80%対20%**で勝利(261ペア)
- Fish S2 ProはMiniMaxに**95%対5%**で勝利(142ペア)
- Fish S1はElevenLabs V3に**64%対36%**で勝利(150ペア)
実施の理由
従来の指標における問題点
**MOS(Mean Opinion Score:平均オピニオン評点)**は依然としてTTS評価のデファクトスタンダードですが、大きな欠陥があります。サンプルの長さ、リスナーの属性、再生環境、評価基準などのテスト条件が公開されることは稀であり、論文間での比較は無意味です。一方、WER/CER(単語/文字誤り率)を最適化ターゲットにすることは、逆効果になる場合があります。WERを下げすぎようとすると、モデルが過度に明瞭でロボットのような話し方になり、自然さや韻律(プロソディ)が犠牲になることが多いためです。実際の人間のように時折不明瞭に話すモデルの方が、すべての音節を完璧に発音するモデルよりも優れた音質に聞こえることがあります。
既存のリーダーボードにおける問題点
TTS-Arena-V2やArtificial Analysisのような公開リーダーボードは、短く単純な文章(通常は1行のセリフや短いナレーション)でモデルを評価しています。これは、長文コンテンツ、複数話者による対話、表現力豊かなプロソディタグ、多言語テキストなど、実世界でのTTS利用の複雑さを捉えきれていません。
手法以外にも、完全性に関する懸念があります。TTS-Arena-V2では、音声ファイルのメタデータからプロバイダーが特定できてしまうオーディオヘッダーのリークという既知の問題が発生し、ブラインド評価の前提が崩れました。また、特定のベンチマーク文章に最適化したり、厳選したチェックポイントを提出したり、組織的な投票によってランキングを水増ししたりする**リーダーボードの不正操作(ゲーミング)**が蔓延していることも認識しています。これらのリーダーボードは、信頼できる品質指標ではなく、マーケティングツールになりつつあります。
私たちが真に求めていたもの
モデル開発の意思決定において信頼できる**「実際のユーザーはどのTTS出力を好むのか?」という正解データ(グランドトゥルース)**、すなわち「信頼できる内部報酬信号」が必要でした。論文の数値でも、操作可能なリーダーボードの順位でもなく、ユーザーが実際の選択を行う中で得られる継続的で正直な嗜好データです。
そこで、私たちはプロダクションプラットフォームにブラインド評価パイプラインを直接組み込みました。
実験設計
ブラインドペア比較
Fish Audioのスタジオでは、すべてのTTSタスクにおいて2つの音声バージョンを並べて表示します。各バージョンは、デフォルトのFish Audioバックエンドではなく、競合プロバイダーに10%の確率でサイレントルーティングされます。テキスト、参照ボイス、UIはすべて同じであり、ユーザーはどちらのプロバイダーが音声を生成したかを知ることはできません。
実験は10日間(2026年3月26日〜4月5日)実施され、71,000件以上のペアグループを収集しました。そのうち、当社の品質基準を満たし、プロバイダー間の比較が含まれる5,098件を分析対象としました。
何をもって「勝利」とするか
主観的な評価ではなく、厳格な行動信号を使用しています:
- ユーザーは両方のバージョンを少なくとも2回ずつ再生していること(実際に両方を比較したことを確認)
- 正確に片方のバージョンのみがダウンロードされていること(それが勝者となる)
この「聴いてからダウンロードする」という信号は、星による評価や強制選択式のアンケートよりもはるかに信頼性が高いものです。ユーザーは、実際に使用する音声について真剣に判断を下しています。
ユーザー構成
実験のサンプルは、約70%の新規ユーザーと30%のリピーターで構成されています。この構成は、Fish Audioに馴染みのあるリピーターによってわずかにFish Audio側に有利なバイアスを生む可能性がありますが、同時に、参加者の過半数から得られる純粋な第一印象の嗜好を確実に捉えることができます。
ボイスの選択
実験には、プラットフォーム上の上位500の人気公開ボイスを使用しました。各ボイスは事前にサードパーティプロバイダーのシステムにクローンされ、両方のシステムで同じ参照ボイスのアイデンティティが利用可能であることを確認しました。ボイスIDのマッピングは専用のJSONマップファイルで管理され、ルーティングの適格性に関する唯一の信頼できる情報源(Single Source of Truth)として機能しています。
テストされたプロバイダーとモデル
| プロバイダー | モデル | ルーティングターゲット |
|---|---|---|
| Fish Audio | S2 Pro (最新) | fish:s2-pro |
| Fish Audio | S1 (前世代) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
評価の範囲とタグのサポート
すべてのプロバイダーが同じ機能セットをサポートしているわけではありません。Fish Audio S2 Proは、豊かな韻律タグ(例:[laughs]、[sighs])や、複数話者コンテンツ向けのスピーカータグ(<|speaker:N|>)をサポートしています。プロダクションのトラフィックには当然タグ付きテキストが含まれるため、これは重要です。
- ElevenLabs V3 は、最も完全な評価を受けました。括弧形式への正規化後に任意のタグをサポートするため、内容に関わらずほぼすべてのリクエストが対象となりました。
- ElevenLabs 2.5 Flash および Multilingual V2 には、プレーンテキストのリクエストのみを送信しました(タグなし)。
- Inworld は、プレーンテキストのみで、出力形式も
mp3に限定されていたため、対象となるトラフィックがさらに制限されました。 - MiniMax は、感嘆タグ(
(laughs)、(sighs)など)は受け入れましたが、他のタグタイプは拒否されました。一貫してユーザーの嗜好結果が悪かったため、ユーザーエクスペリエンスのさらなる低下を避けるために実験を早期終了しました。
ルーティングシステムは、現在のリクエストの機能(言語、タグ、フォーマット、マルチ参照ボイス)に対して各代替プロバイダーを評価します。サポートされている代替案のみが候補となり、重み付けされたランダム選択によって1つが選ばれます。唯一の適格な代替案がFish対Fishの比較(S1対S2 Pro)である場合、クロスプロバイダーのデータ収集を優先するために、サンプリング確率は基本レートの10分の1に下げられます。
コストについて
これらの実験は無料ではありません。サードパーティのTTS APIを大規模に利用するとコストがかさみます。
- ElevenLabs: API呼び出しに1,500ドル以上を支出
- MiniMax: 330ドルを支出(低パフォーマンスのため早期終了)
- Inworld: 170ドルを支出

統計的手法
ブラッドリー・テリー・モデル
異なるモデルが異なる頻度で異なる対戦相手と当たる場合、単純な勝率は誤解を招く可能性があります。ブラッドリー・テリー・モデルは、ペア比較データからグローバルな強さのスコアを計算することでこの問題を解決します。任意の2つのモデル間の予測勝率が観測データと一致するように、各モデルの潜在的な「強さ」パラメータを反復的に推定します。
BTスコア と を持つ2つのモデル と について:
当社の実装では、収束公差 で最大500回の反復を実行し、各ステップで幾何平均を使用してスコアを正規化しています。
信頼区間
嗜好ペアデータの200回の再サンプリングから計算された95%ブートストラップ信頼区間を報告しています。各再サンプリングでは、元の ペアから重複を許して ペアを抽出し、BT計算を再実行します。ブートストラップされたスコアの2.5パーセンタイルと97.5パーセンタイルが信頼区間の境界となります。
各バックエンドの勝率については、極端な勝率において正規近似区間よりも優れたカバレッジを提供するウィルソン・スコア区間を使用しています。
言語別の結果
ラテン文字言語(英語、スペイン語、フランス語、ドイツ語など)
ラテン文字言語は、4,173件の嗜好ペアを含む最大のセグメントです。
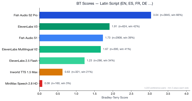
Fish S2 Proは3.05で首位です。注目すべきは、このカテゴリにおいてのみElevenLabs V3(1.90)がFish S1(1.72)をわずかに上回ったことです。これは、競合他社が当社の旧モデルを追い抜いた唯一の言語グループです。ElevenLabs Multilingual V2も1.70と、S1に肉薄する良好なパフォーマンスを示しました。
これは理にかなっています。ElevenLabsは歴史的に英語とヨーロッパ言語に注力しており、彼らのV3モデルはこの領域で強力です。それでもなお、Fish S2 ProはElevenLabs V3に対して1.6倍の優位性を維持しています。
中国語
中国語は329件の嗜好ペアがあり、Fish Audioの圧倒的な優位性が示されました。
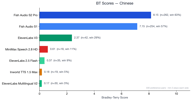
Fish Audioの両モデル(S2 Proが8.11、S1が7.11)は、すべての競合他社を圧倒しています。ElevenLabs V3は2.36と健闘していますが、遠く及びません。他のすべての競合は1.0を下回りました。
日本語
日本語は354件の嗜好ペアがあります。
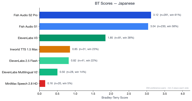
Fish S2 Pro (3.12) と Fish S1 (3.02) は非常に近く、どちらもElevenLabs V3 (1.88) を大きく引き離しています。Fishモデルと競合他社の差は、CJK(中日韓)言語において最大となります。
言語横断的なまとめ
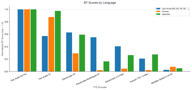
Fish Audio S2 Proは、すべての言語カテゴリで1位にランクされました。競合との差は以下の通りです:
- ラテン文字言語: 競合が最も近く、ElevenLabs V3は真に競争力がある(相対スコア 0.62)
- 中国語: Fish Audioが圧倒的で、競合他社はほとんど太刀打ちできていない
- 日本語: 中国語と同様に、Fishモデルが大きくリードしている
制限事項
APIユーザーの除外
プラットフォームの安定性を確保するため、APIユーザーは実験に含まれませんでした。10%のサンプリングレートはウェブプラットフォームのユーザーにのみ適用されます。つまり、この結果はウェブプラットフォームの利用パターンを反映したものであり、API中心のプロダクションワークロードとは異なる可能性があります。
タグサポートによるカバレッジの不均一
サードパーティプロバイダーによってタグのサポート状況が異なるため、受け取ったトラフィックのサブセットも異なります:
- ElevenLabs V3は、ほぼすべてのリクエストが対象となりました(タグをサポートしているため)。
- ElevenLabs Flash/Multilingualは、タグなしのリクエストのみを受け取りました。
- Inworldは、タグなし・mp3形式のリクエストのみを受け取りました。
これは、競争条件が完全に平等ではないことを意味します。ElevenLabs V3の結果は、最も代表的なトラフィックサンプルを受け取ったため、Fish Audioと最も直接的な比較が可能です。他のモデルは、より単純なプレーンテキストのリクエストに偏ったサブセットで評価されており、これは本来、彼らに有利に働くはずの条件です。
MiniMaxの結果の信頼性について
MiniMax Speech 2.8 HDのスコアは異常に低くなりました(BT 0.12、勝率5% — Inworldに対しても)。私たちは、当社のMiniMax API統合が最適ではなかった可能性を疑っています。生成されたいくつかのサンプルを聴いた限りでは、特定の技術的な問題は特定できませんでしたが、音声は明瞭であるものの、他のすべてのプロバイダーと比較して韻律や自然さが顕著に劣っていました。サンプル数を増やすために実験途中でMiniMaxのルーティング対象を広げましたが、パフォーマンスは改善しませんでした。330ドルのAPIコストを積み上げた後、競争力のある結果が見込めないと判断し、実験を早期終了しました。
もしMiniMax社が、この結果が自社モデルの真の実力を反映していないと考えるのであれば、当社の統合方法に関する共同レビューを歓迎します。
ボイスマッピングの制約
サードパーティプラットフォームでのクローン作成に成功したボイスのみがルーティング可能です。ボイスクローンに失敗した場合、そのボイスはそのプロバイダーの対象外となります。つまり、各プロバイダーは上位500のボイスのうち、わずかに異なる(大部分は重複していますが)サブセットでテストされています。
プラットフォームへの習熟によるバイアスの可能性
新規ユーザーが約70%を占める一方で、残り30%のリピーターは、Fish Audioの音声特性に合わせた嗜好を持っている可能性があります。新規ユーザーが大半を占めるため、この影響は小さいと考えていますが、完全に排除することはできません。
結論
これは、これまでに行われたTTS品質の公開評価の中でも、最も厳格なものの1つであると自負しています:
- 報酬を与えられた評価者ではなく、実際のユーザーによる評価
- ユーザーはどちらのプロバイダーかを知らないブラインド比較
- 主観的な評価ではなく、**行動信号(ダウンロード)**に基づく評価
- 長文、韻律タグ、多言語など、実世界の複雑さを持つプロダクショントラフィック
- 10日間にわたって収集された、多言語にわたる5,000件以上の嗜好ペア
- サードパーティのAPI利用料だけで2,000ドル以上を支出
結果は明白です:Fish Audio S2 Proは、テストされたすべての言語において最も好まれるTTSモデルであり、特に中国語と日本語で強力な優位性を持っています。前世代のS1モデルでさえ、集計においてすべての競合他社を上回りました。
これらの結果は、エンドツーエンド・モデリングと**RLHF(人間のフィードバックによる強化学習)**に向けた当社のロードマップの正当性をさらに裏付けるものです。 私たちは透明性を重視しています。手法、ルーティングロジック、分析コードは、当社のプラットフォームインフラの一部です。TTSコミュニティが当社のアプローチを精査し、将来の評価に向けた改善案を提案してくれることを歓迎します。
この評価は、2026年3月26日から4月5日にかけてFish Audioチームによって実施されました。手法に関する質問や議論については、fish.audioまでお問い合わせください。









