Fish AudioがS2をオープンソース化:きめ細かな制御とプロダクションレベルのストリーミングを両立
2026年3月9日
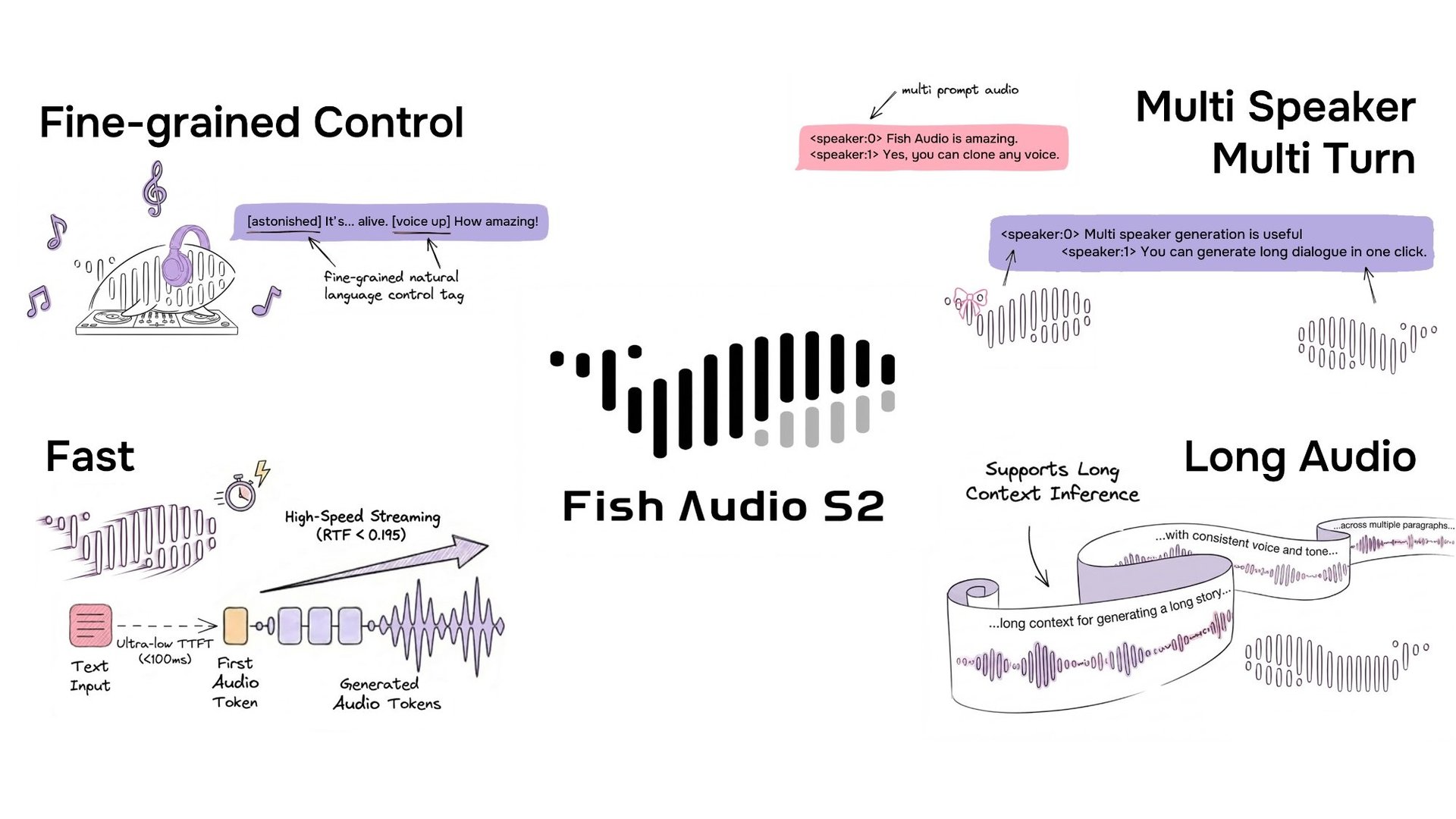
S2のオープンソース版は、プロジェクトのGitHubリポジトリおよびHuggingFaceで公開されています。
Fish Audioは、[laugh]、[whispers]、[super happy]といった自然言語タグを使用して、韻律や感情をきめ細かくインライン制御できるテキスト読み上げ(TTS)モデル「S2」をオープンソース化しました。約50言語、1,000万時間以上のオーディオデータで学習されたこのシステムは、強化学習によるアラインメントとデュアル自己回帰(Dual-AR)アーキテクチャを組み合わせています。今回のリリースには、モデルの重み、ファインチューニング用コード、およびSGLangベースのストリーミング推論エンジンが含まれています。
自然言語によるきめ細かなインライン制御
S2は、テキスト内の特定の単語やフレーズの位置に自然言語の指示を直接埋め込むことで、音声生成のインライン制御を可能にします。あらかじめ定義された固定のタグセットに依存するのではなく、S2は[whisper in small voice](小さな声で囁く)、[professional broadcast tone](プロの放送トーン)、[pitch up](ピッチを上げる)といった自由形式のテキスト記述を受け付け、単語レベルでのオープンエンドな表現制御を実現します。
オーディオ・チューリング・テスト(Audio Turing Test)において、S2は命令の書き換え(instruction rewriting)を行うことで、Seed-TTSの0.417やMiniMax-Speechの0.387を上回る0.515という事後平均を達成しました。EmergentTTS-Evalでは、gpt-4o-mini-ttsのベースラインに対して81.88%という総合勝率を記録しました。これは、GoogleやOpenAIのクローズドソースシステムを含む、評価された全モデルの中で最高値です。
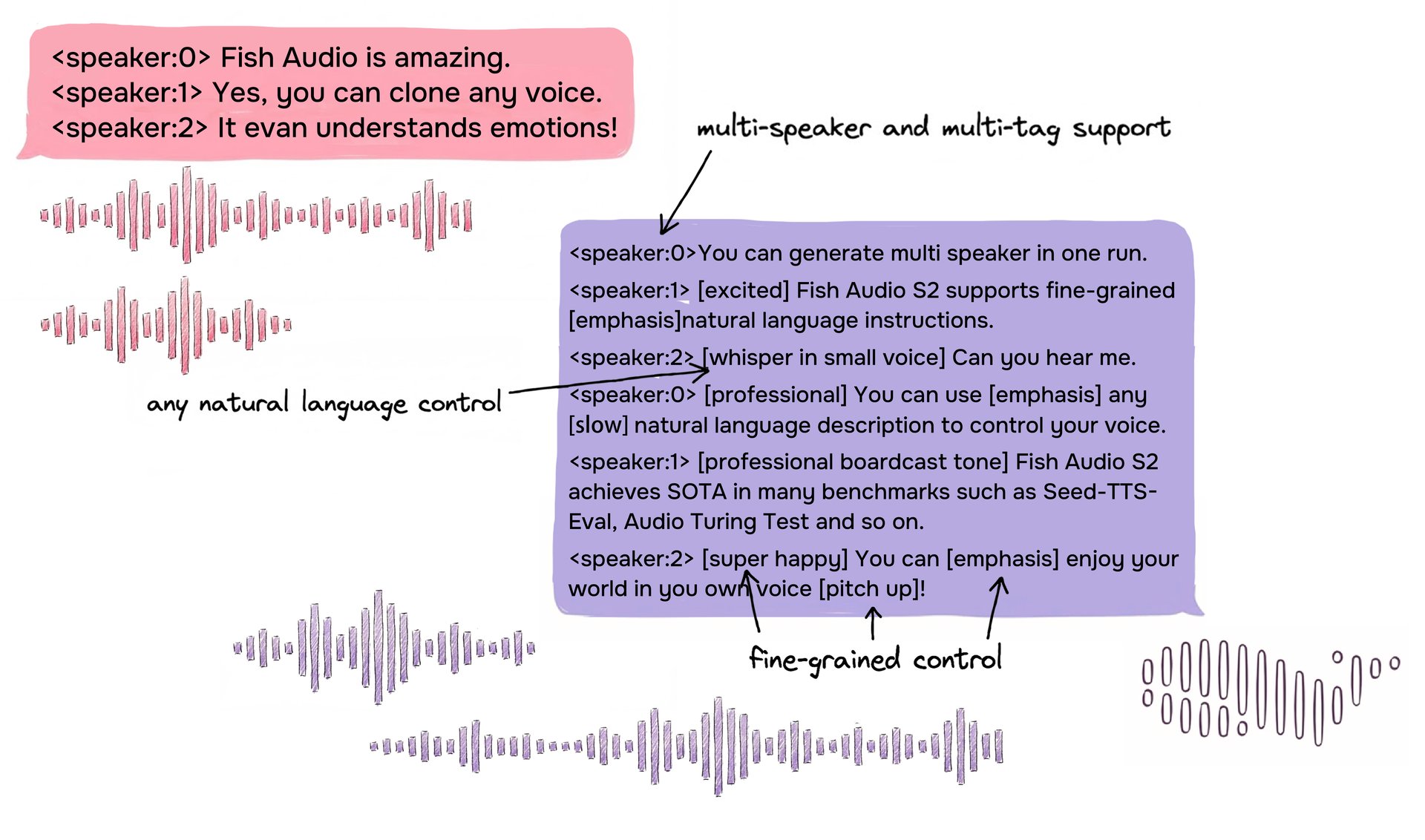 自由形式の自然言語インラインタグを使用して、きめ細かな制御を行う複数人の対話のS2入力形式の例。
自由形式の自然言語インラインタグを使用して、きめ細かな制御を行う複数人の対話のS2入力形式の例。
統一されたレシピ:同一モデルからのデータキュレーションとRL報酬
S2の中核的なアーキテクチャ上の決定は、学習データのフィルタリングとアノテーションに使用されるモデルを、強化学習時の報酬モデル(reward models)として直接再利用している点にあります。
- 音声品質モデル:データフィルタリング時にSNR(信号対雑音比)、話者の一貫性、明瞭度などの次元でオーディオをスコアリングし、強化学習時には音響的嗜好の報酬として機能します。
- リッチ・トランスクリプションASRモデル(Qwen3-Omni-30B-A3Bから継続的な事前学習を実施):データキュレーション中にインラインの副言語アノテーションを含むキャプション付きの書き起こしを生成し、強化学習時には生成されたオーディオを再書き起こしして元のプロンプトと比較することで、明瞭度と指示追従の報酬を提供します。
この二役のデザインにより、事前学習データと事後学習目標の間の分布の不一致を構造的に解消しています。これは、データパイプラインとは別に報酬モデルを学習させる他のTTSシステムでは未解決の課題です。
モデルの内部構造:Dual-ARアーキテクチャ
S2は、RVQベースのオーディオコーデック(10個のコードブック、約21Hzのフレームレート)と組み合わせたデコーダーのみのTransformerをベースに構築されています。すべてのコードブックを時間軸に沿ってフラット化すると、シーケンス長が10倍に膨れ上がってしまいます。S2は、これを**デュアル自己回帰(Dual-AR)**アーキテクチャで解決しています。
- Slow AR:時間軸に沿って動作し、主要なセマンティックコードブックを予測します。
- Fast AR:各タイムステップで残りの9つの残留コードブックを生成し、きめ細かな音響ディテールを再構成します。
この非対称な設計(時間軸方向に4Bパラメータ、深さ方向に400Mパラメータ)により、推論の効率を維持しながら高い音響忠実度を保っています。
音声のための強化学習アラインメント
事後学習には、長いオーディオコンテキストにおいてPPOスタイルの価値モデル(value models)によるメモリオーバーヘッドを避けるため、Group Relative Policy Optimization (GRPO)を採用しています。報酬信号は、以下を含む複数の次元を組み合わせています。
- セマンティックな正確さと指示への忠実度
- 音響的嗜好のスコアリング
- 音色の類似性
ベンチマーク結果
S2は、複数の公開ベンチマークにおいて主要な結果を達成しています。
| ベンチマーク | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (中国語) | 0.54% (全体で最高) |
| Seed-TTS Eval — WER (英語) | 0.99% (全体で最高) |
| オーディオ・チューリング・テスト (指示あり) | 0.515 事後平均 |
| EmergentTTS-Eval — 勝率 | 81.88% (全体で最高) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — 品質 | 4.51 / 5.0 |
| 多言語 (MiniMax テストセット) — 最良 WER | 24言語中11言語 |
| 多言語 (MiniMax テストセット) — 最良 SIM | 24言語中17言語 |
Seed-TTS Evalにおいて、S2はQwen3-TTS (0.77/1.24)、MiniMax Speech-02 (0.99/1.90)、Seed-TTS (1.12/2.25)といったクローズドソースシステムを含む全モデルの中で最低のWERを達成しました。オーディオ・チューリング・テストの0.515は、Seed-TTS (0.417)を24%、MiniMax-Speech (0.387)を33%上回っています。EmergentTTS-Evalでは、特に副言語表現(勝率91.61%)、質問(84.41%)、構文の複雑さ(83.39%)において極めて強力な結果を残しています。
SGLangによるプロダクションレベルのストリーミング
S2のDual-ARアーキテクチャは構造的に標準的な自己回帰型LLMと同型であるため、最小限の修正でSGLangから、継続的バッチ処理、Paged KV Cache、CUDAグラフのリプレイ、RadixAttentionベースのプレフィックス・キャッシングなど、LLMネイティブなサービングの最適化をすべて直接継承できます。
ボイスクローニングでは、S2はシステムプロンプト内にリファレンスオーディオのトークンを配置します。SGLangのRadixAttentionはこれらのKV状態を自動的にキャッシュし、同じ音声がリクエスト間で再利用される場合に、平均86.4%(ピーク時は90%以上)のプレフィックスキャッシュ・ヒット率を達成します。これにより、リファレンスオーディオのプリフィル(事前充填)のオーバーヘッドはほぼ無視できるレベルになります。
単一のNVIDIA H200 GPUにおける性能:
- リアルタイム係数 (RTF): 0.195
- 最初の音声までの時間 (TTFA): 約100ms
- スループット: RTFを0.5未満に維持しながら、毎秒3,000以上の音響トークンを処理
このリリースの重要性
S2は単なるモデルのチェックポイントではなく、モデルの重み、ファインチューニング用コード、そしてプロダクション対応の推論スタックを備えた完全なシステムとしてリリースされています。
特筆すべき設計上の選択肢が2つあります。第一に、データと報酬のパイプラインを統合したことで、他のTTSシステムがアーキテクチャレベルで対処してこなかった、事前学習と強化学習(RL)の間の分布の不一致という構造的問題を解消しています。第二に、Dual-ARアーキテクチャと標準的なLLMとの構造的な同型性により、S2はカスタム推論インフラを必要とせず、LLMサービングの最適化エコシステムをフルに活用できる点です。
S2は、プロジェクトのGitHubリポジトリ、SGLang-Omni、HuggingFace、およびfish.audioのインタラクティブ・デモで利用可能です。



