複数の声で読み上げるテキスト読み上げ — マルチスピーカー完全ガイド (Fish Audio)

単一ボイスのTTSは、対話、オーディオブック、ポッドキャストにおいて単調に聞こえがちです。このガイドでは、Fish Audioでボイスを見つけて整理し、Text to SpeechやStory Studioのマルチスピーカー機能を使用して、従来の音声録音ワークフローなしで自然なマルチキャラクターオーディオを作成する方法を紹介します。
2026年3月 | Fish Audio マルチスピーカー TTS が S2 Pro で利用可能になりました
目次
- マルチスピーカーテキスト読み上げとは?
- ステップ 1 — Discoveryで適切なボイスを見つける
- ステップ 2 — Text to Speechでのマルチスピーカー機能
- ステップ 3 — Story Studioでのマルチスピーカー機能
- TTS vs Story Studio — どちらを使うべきか?
- ユースケース — マルチスピーカーTTSで何が作れる?
- スクリプトからオーディオへ — 1回のセッションで
- マルチスピーカーTTSに関するよくある質問
ほとんどのテキスト読み上げツールでは、1つの声、1人のナレーター、最初から最後まで1つのトーンしか提供されません。単一話者の解説動画ならそれで十分ですが、台本に2人の会話、ホストとゲスト、あるいは明確な役割分担がある物語が含まれる場合、単一のボイスでは対話が平坦で単調な読み上げになってしまいます。リスナーはすぐに飽きてしまうでしょう。
複数の声によるテキスト読み上げ(マルチスピーカーTTS)は、この問題を解決します。各話者に異なるAIボイスを割り当て、話者間のタイミングを制御することで、実際に会話しているように聞こえるオーディオを作成できます。Fish Audioは、ボイスの発見から複数チャプターのエクスポートまでをカバーする、完全なテキスト読み上げ対話ジェネレーターとして機能します。このガイドでは、ボイスの探し方と整理方法、短いコンテンツ向けのText to Speechツールでのマルチスピーカー利用法、そしてStory Studioで本格的な制作へとスケールアップさせる全ワークフローを解説します。
マルチスピーカーテキスト読み上げとは?
マルチスピーカーテキスト読み上げとは、台本の各セグメントに異なるAIボイス(それぞれ独自のトーン、性別、年齢、話し方を持つ)を割り当て、1つの連続したオーディオ出力として生成するTTSワークフローのことです。
従来のTTSツールは、単一のナレーションモデルを中心に構築されています。1つのボイス、1つのテキスト入力、1つのオーディオファイルという構成です。これは、単一のナレーターによるオーディオブックの朗読、ナレーション、またはアナウンスには適していますが、対話が含まれるものに関しては完全に機能しなくなります。従来のツールで2人のキャラクターの会話を作成するには、各話者を個別に生成し、その後編集ソフトで手動でオーディオを繋ぎ合わせる必要があります。タイミングを調整し、音量を合わせ、トランジションが2つの異なる録音のように聞こえないよう苦労することになります。
問題は手間が増えることだけではありません。専用のコントロールなしに、話者間のタイミングを正しく設定することはほぼ不可能です。実際の会話にはリズムがあります。返答の前のわずかな沈黙、誰かが割り込んだときのわずかな重なり、難しい答えの前の長いポーズなどです。話者間のギャップを正確にコントロールできなければ、どんなに良いボイスを選んでも会話はロボットのように聞こえてしまいます。
マルチスピーカーTTSツールは、これら両方の問題を解決します。各話者は独自のボイスと独自のテキストブロックを持ち、話者間のギャップを調整可能です。最終的な出力は、タイミングが最適化された1つの首尾一貫したオーディオファイルになります。
マルチスピーカーテキスト読み上げでできること:
- 台本の各話者に異なるAIボイスを割り当てる
- 各話者間のタイミングとポーズを制御する
- 対話全体を1つの連続したオーディオファイルとして生成する
- 2人のやり取りからフルキャストの作品まで、追加のエクスポートや手動編集なしでスケールアップできる
ステップ 1 — Discoveryで適切なボイスを見つける
マルチスピーカープロジェクトを構築する前に、ボイスが必要です。Fish AudioのDiscoveryページで見つけることができます。ライブラリには数千のボイスがあるため、フィルタリングツールを活用することが重要です。
fish.audio/app/discovery/ にアクセスしてください。
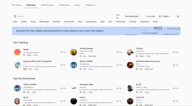
検索とフィルター
Discoveryページを開くと、検索バー、上部のクイックフィルタータグ、右側のソートと言語コントロールが表示されます。
名前で検索(探しているボイスが決まっている場合)、Recommended(おすすめ)またはTrending(トレンド)でソート(他のクリエイターに人気のボイスを表示)、Language(言語)(ターゲット言語でトレーニングされたボイスに絞り込み)が可能です。
上部のクイックフィルタータグは、最も一般的な属性(男性、女性、若者、中年、ナレーション、ソーシャルメディア、ディープ、ソフト、プロフェッショナル、ドラマチック、ミステリアス、アニメなど)をカバーしており、これらを組み合わせることもできます。「Female + Young + Narration」を選択すると、そのプロフィールに一致するボイスに即座に絞り込まれます。

より細かく制御するには、フィルターパネル(右上のスライダーアイコン)を開きます。以下の項目が設定可能です:
- Languages(言語) — 特定の言語に絞り込み(複数言語一致を含む)
- Tags(タグ) — ボイス作成者によって追加された自由形式のタグ
- Gender(性別) — 男性、女性、ニュートラル
- Age(年齢) — 若者、中年、高齢者
- Use Case(ユースケース) — 会話、ナレーション、キャラクターボイス、ソーシャルメディア、教育、広告など
- Voice Qualities(ボイスの質) — ディープ、低い、中間、高い、ソフト、明るい、その他48以上の記述子
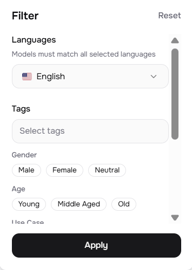
マルチスピーカープロジェクトでは、「Use Case」と「Voice Qualities」のフィルターが特に役立ちます。ポッドキャスト風の対話を作成する場合、「Conversational + Soft」なボイスと「Narration + Deep」なボイスを1つずつ選ぶことで、リスナーが台本を見なくても話者の違いをはっきりと認識できるようになります。
お気に入り、ブックマーク、コレクションへの保存
気に入ったボイスを見つけたら、いくつかの方法で保存できます。 検索結果の各ボイスカードにあるハートアイコンは、クイックな「お気に入り(Like)」です。後で参照できるように、Likesタブにボイスが追加されます。
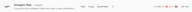
より確実に保存するには、ボイスの詳細ページを開いて「Bookmark」をクリックします。**ブックマーク(Bookmarked)**されたボイスは、お気に入りとは別のBookmarksタブに表示され、TTSとStory Studioの両方のボイスセレクターから直接アクセスできるようになります。
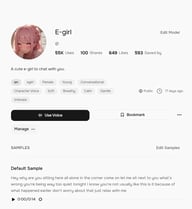
プロジェクト単位で整理するには、**コレクション(Collections)**が最も強力なオプションです。トップナビゲーションの「Collections」をクリックし、「Create Collection」を選択して、「ポッドキャスト用」や「オーディオブック プロジェクトA」などの名前を付けてグループを作成します。タイトルと説明を入力して「Create」をクリックします。

ボイスをコレクションに追加するには、ボイスの詳細ページを開き、ブックマークボタンの隣にある三点メニュー (⋯) をクリックして、「Add to Collection」を選択します。作成済みのコレクションがドロップダウンに表示され、ワンクリックで追加できます。
これを行っておくと、TTSやStory Studio内で非常に便利です。**ボイス選択(Select Voice)**パネルを開くと、コレクションが上部のタブとして表示されます(Recently Used、Explore、Default Voices、My Voices、Bookmarkedの隣)。毎回ゼロから検索する代わりに、プロジェクト用のボイスがすでにグループ化され、準備が整った状態になります。
ステップ 2 — Text to Speechでのマルチスピーカー機能
Fish AudioのText to Speechツールは、1回の生成で複数の話者をサポートしています。対話のスニペット、広告、短いポッドキャストのイントロ、デモスクリプトなど、チャプター管理を必要とせず、素早く洗練された出力を得たい短〜中規模のコンテンツに最適なツールです。まだボイスを決めていない場合は、まずDiscoveryライブラリをブラウズすることをお勧めします。
fish.audio/app/text-to-speech/ にアクセスしてください。
最初の人(スピーカー)を設定する
TTSを開くと、上部にボイスセレクターがある単一のテキストブロックが表示されます。ボイス名をクリックしてSelect Voiceパネルを開き、1人目のスピーカーを選択します。テキストブロックに1人目のセリフを入力または貼り付けます。
また、インライン感情タグ([sad], [emphasis], [excited] など)を、強調したい単語の直前に配置することで、話し方を調整できます。
スピーカーを追加する
最初のテキストブロックの下にある + Add Speaker をクリックします。新しいブロックが表示され、それぞれに独立したボイスセレクターが付いています。このスピーカーに別のボイスを選択してセリフを入力すると、2つのブロックが画面に表示されている順序で、1つの連続したオーディオファイルとして生成されます。
追加できるスピーカーの数に上限はありません。各ブロックは独立しており、必要に応じて異なるボイス、テキスト、感情タグを設定できます。実際には、ほとんどの対話プロジェクトでは2〜4つの異なるボイスを使うのが、明快さと聞き取りやすさのバランスが良く、効果的です。 右側のパネルでは、生成前に音量(Volume)、速度(Speed)、ラウドネス正規化(Loudness Normalization)、およびテキスト正規化(Text Normalization)(数値、通貨、その他の書式付きテキストの読み上げ精度を向上)を微調整できます。
文字数制限とStory Studioへの移行タイミング
画面下部の文字数カウンターに注意してください。制限はプランによって異なります。自分のプランの制限については、Fish Audio の料金とプランを確認してください。短編から中編のコンテンツにはTTSがより高速でシンプルなワークフローですが、オーディオブックの丸一章、複数セグメントのポッドキャスト、ゲームの対話スクリプトなど、より長い制作物に取り組む場合は、Story Studioが必要なツールを提供してくれます。
ステップ 3 — Story Studioでのマルチスピーカー機能
Story Studioは、長編オーディオ制作のために構築されています。TTSが素早い生成に最適化されているのに対し、Story Studioは複数のボイスをブロックごとにシーケンス化し、話者間のタイミングを正確に制御し、複雑なプロジェクトをチャプターごとに整理できる構造化された環境を提供します。各ブロックは割り当てられたボイスで独立して生成され、最終的なエクスポートでそれらが1つの連続したファイルに結合されます。 fish.audio/app/story-studio/ にアクセスしてください。
新しいプロジェクトを作成する
Story Studioのホーム画面で + Project をクリックします。Create project ダイアログが開き、以下の設定が表示されます:
- Project Name(プロジェクト名) — プロジェクトに名前を付けます
- Default Voice(デフォルトボイス) — 新しいブロックにデフォルトで割り当てられるボイス(ブロックごとに変更可能)
- Speech Model(音声モデル) — 現在は S2 Pro (最新)
- Text Normalization(テキスト正規化) — 有効にすると、数値、通貨、日付などの読み上げ精度が向上します
- Loudness Normalization(ラウドネス正規化) — ブロック間の音量レベルを均一にし、一貫した出力を提供します
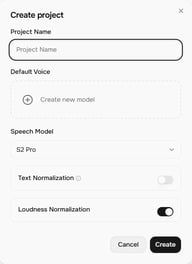
「Create」をクリックしてプロジェクトエディタを開きます。
ブロックの追加とボイスの切り替え
プロジェクトを開くと、デフォルトのチャプターと最初のテキストブロックがすでに配置されています。1人目のスピーカーのボイスは、各ブロックの左側に色付きのアバターとして表示されます。
新しいスピーカーのセリフを追加するには、既存のブロックの下にある + ボタン をクリックします。新しいブロックが表示されます。新しいブロックの左側にある色付きのボイスアバターをクリックしてボイス選択パネルを開き、別のボイスを割り当てます。ブロックに2人目のセリフを入力します。
台本のすべてのやり取りに対してこれを繰り返します。各ブロックが1人の話者の番(ターン)になります。右側のパネルには、**プロジェクトで使用されているボイス(Voices used in the project)**が一覧表示され、現在すべてのブロックに割り当てられているすべてのボイスをひと目で把握できます。
スピーカー間のポーズを微調整する
各ブロックのペアの間には、現在の間隔を示す小さなタイミングバブル(例:0.35s)が表示されます。これをクリックして、その特定のスピーカーペア間のポーズ時間を調整できます。
これは、対話のリアリズムを高めるための Story Studio の最も重要な機能の1つです。人間の会話は、完全に隙間なく続く発話の連続ではありません。返答の前のわずかな沈黙は思考時間を意味し、感情的な反応の前の長いポーズは重みを加えます。これらのギャップを正しく設定することが、「作られた音声」と「リアルな音声」の分かれ目になります。0.2〜0.5秒の調整だけでも、会話の自然さが劇的に変わります。すべてのギャップをデフォルトのままにするのではなく、各やり取りを個別に調整する価値があります。 シーンのリズムに合わせて、ブロック間の各ポーズを個別に調整しましょう。
長尺プロジェクト向けのチャプター追加
エディタの左側にチャプターパネルがあります。デフォルトでは、すべてのプロジェクトは「Default Chapter」から始まります。「+」をクリックして新しいチャプターを追加します。
チャプターを使用すると、長尺のプロジェクトをナビゲート可能なセクションに分割できます。オーディオブックの各章、ポッドキャストの各セグメント、ゲームスクリプトの各シーンなどに分けられます。各チャプターは独自のブロックシーケンスを持ち、独立して作業できます。最終的なエクスポートでは、すべてのチャプターが順番通りに1つの出力に統合されます。
数百語を超える対話の場合、チャプター機能を使うことで Story Studio プロジェクトを整理し、編集しやすい状態に保つことができます。
TTS vs Story Studio — どちらを使うべきか?
| Text to Speech | Story Studio | |
|---|---|---|
| マルチスピーカー手法 | ネイティブ (S2 Pro モデルレベル) | 順次ブロック生成 |
| 文字数制限 | プランに依存 | 制限なし (マルチチャプター) |
| 話者数 | 最大5名まで | 無制限 |
| 話者間のポーズ制御 | ❌ | ✅ ブロックごとに精密設定可能 |
| チャプター管理 | ❌ | ✅ |
| タイムライン表示 | ❌ | ✅ |
| 最適な用途 | 短い対話、広告、デモ | オーディオブック、ポッドキャスト、ゲームスクリプト、長編制作 |
主な技術的違い: TTSは S2 Pro のネイティブなマルチスピーカー機能を使用しており、1回の生成においてモデルレベルで複数の話者を処理します。Story Studioは、個別に生成された各ブロック(それぞれに割り当てられたボイスを持つ)をシーケンス化することで、マルチスピーカー出力を実現し、1つの連続したファイルにします。
2人のスピーカーによる30秒の広告や短い対話クリップを生成する場合は、Text to Speech から始めてください。プロジェクトの設定が不要で高速です。台本がより長い場合や、数回以上のやり取りが含まれる場合、あるいは話者間の正確なタイミング調整が必要な場合は、Story Studio を開きましょう。
ユースケース — マルチスピーカーTTSで何が作れる?
複数のキャラクターが登場するオーディオブック
単一のナレーターによるオーディオブックは、ノンフィクションには適しています。しかし、対話のあるフィクションの場合、1人の声ですべてのキャラクターを演じ分けると聞き取りにくくなることがあります。マルチスピーカーTTSを使用すれば、シーン内の各キャラクターに独自のボイスを割り当てることができます。あるキャラクターには深く落ち着いた声を、別のキャラクターには若くてエネルギッシュな声を。Story Studioのチャプター構造は本の章と直接対応しているため、従来のキャスティングや録音ワークフローなしで、フルレングスの作品を実用的に制作できます。
ポッドキャスト風の対話
2人のホストによるポッドキャスト形式は、最も認知されているオーディオ構造の1つです。対話用のマルチスピーカーAI音声ジェネレーターを使用すれば、書かれた台本からその形式を再現できます。各ホストに1つのボイスを割り当て、自然な交代をシミュレートするポーズを制御できます。これは、録音セッションのスケジュールを調整することなく、定期的にオーディオコンテンツを制作したいクリエイターにとって特に便利です。
eラーニングとトレーニングコンテンツ
教育コンテンツは、モノローグよりも対話形式で提供される方がはるかに魅力的になります。教師と生徒のやり取り、ガイド付きシナリオ、Q&A形式などを複数のボイスで台本化し制作することで、学習者は受動的なナレーションではなく、対話を通じて情報を処理しやすくなります。
ゲームの対話とキャラクターボイス
ゲームの台本は、多くのキャラクターにわたる数百、数千行に及ぶことがよくあります。Story Studioをマルチキャラクター音声ジェネレーターとして使用することで、ゲーム開発者やナラティブデザイナーは、プロトタイピング、デモ、または本制作のための音声付き対話を制作できます。従来の音声録音ワークフローを介さず、各NPCにすべてのセリフで一貫したボイスを割り当てることが可能です。
スクリプトからオーディオへ — 1回のセッションで
かつて複数のキャラクターが登場するオーディオを制作するには、声優を予約し、録音セッションを調整し、何時間もかけてポストプロダクションでテイクを繋ぎ合わせる必要がありました。マルチスピーカーTTSを使えば、そのワークフロー全体が1回のセッションに凝縮されます。Discoveryでボイスを見つけ、コレクションに整理し、ブロックごとに台本を構築してエクスポートするだけです。
短いコンテンツなら、Text to Speech を使って数分で完成します。オーディオブック、ポッドキャストシリーズ、ゲームの対話などのより長い制作物には、Story Studio が、実際に演じられたかのように聞こえる作品を作るための構造とタイミング制御を提供します。

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






