Fish Audio, S2 오픈 소스 공개: 미세 제어와 프로덕션 스트리밍의 결합
2026년 3월 9일
S2 Pro는 Fish Audio 앱에서 사용할 수 있으며, 오픈 소스는 프로젝트의 GitHub 저장소 및 HuggingFace를 통해 제공됩니다.
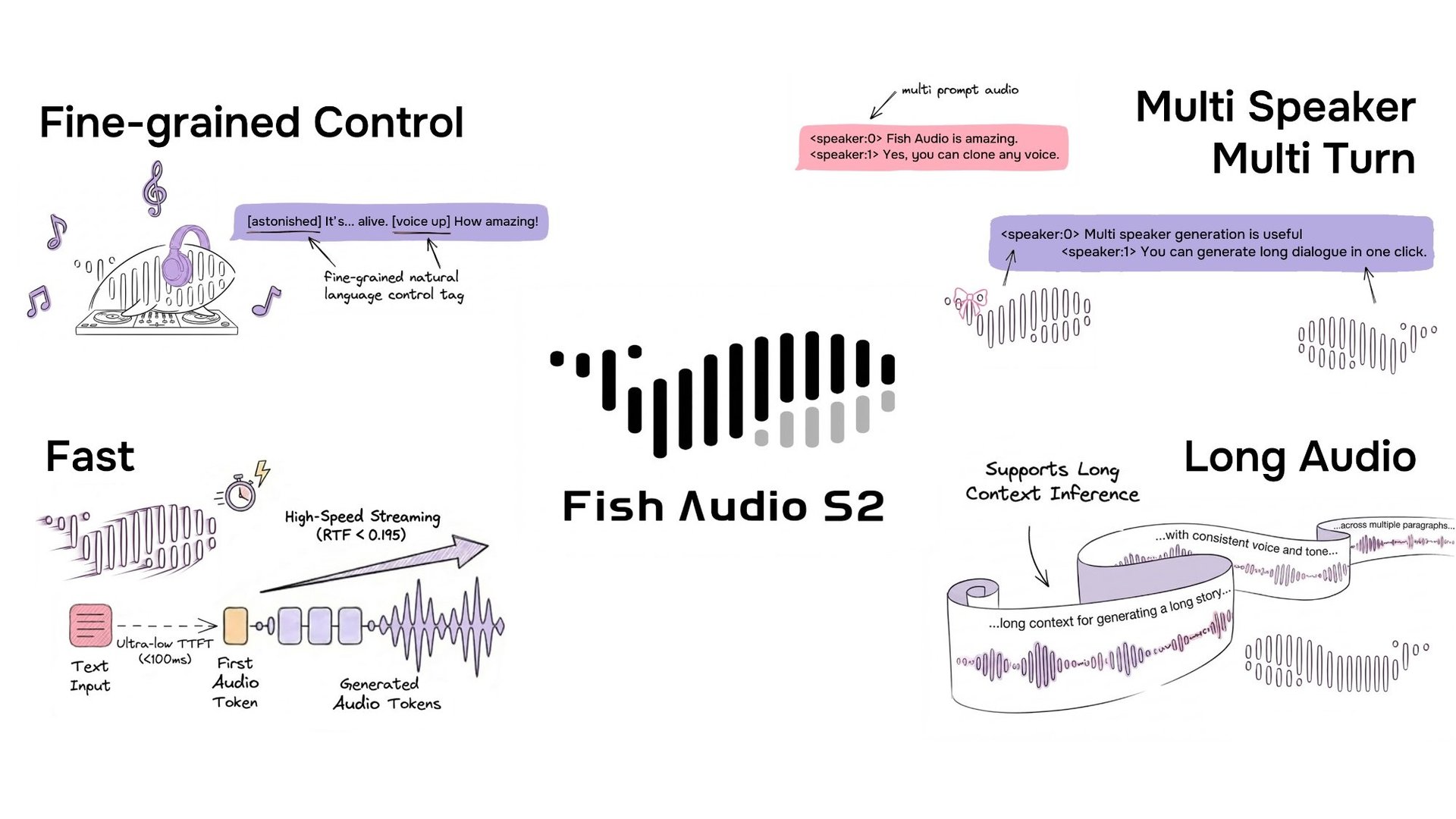
Fish Audio는 [laugh], [whispers], [super happy]와 같은 자연어 태그를 사용하여 운율과 감정을 미세하게 인라인 제어할 수 있는 텍스트 음성 변환 모델인 S2를 오픈 소스로 공개했습니다. 약 50개 언어에 걸쳐 1,000만 시간 이상의 오디오로 학습된 이 시스템은 강화 학습 정렬과 이중 자기회귀(Dual-autoregressive) 아키텍처를 결합했습니다. 이번 릴리스에는 모델 가중치, 미세 조정(fine-tuning) 코드 및 SGLang 기반 스트리밍 추론 엔진이 포함됩니다.
자연어를 통한 미세 인라인 제어
S2는 텍스트 내의 특정 단어 또는 구문 위치에 자연어 지침을 직접 삽입함으로써 음성 생성에 대한 인라인 제어를 가능하게 합니다. 미리 정의된 고정된 태그 세트에 의존하는 대신, S2는 [whisper in small voice], [professional broadcast tone], [pitch up]과 같은 자유 형식의 텍스트 설명을 수용하여 단어 수준에서 개방형 표현 제어를 허용합니다.
오디오 튜링 테스트(Audio Turing Test)에서 S2는 지침 재작성(instruction rewriting) 시 0.515의 사후 평균(posterior mean)을 기록했습니다. 이는 Seed-TTS의 0.417, MiniMax-Speech의 0.387과 비교되는 수치입니다. EmergentTTS-Eval에서는 gpt-4o-mini-tts 베이스라인 대비 81.88%의 전체 승률을 기록하며, Google 및 OpenAI의 폐쇄형 소스 시스템을 포함한 모든 평가 모델 중 가장 높은 점수를 달성했습니다.
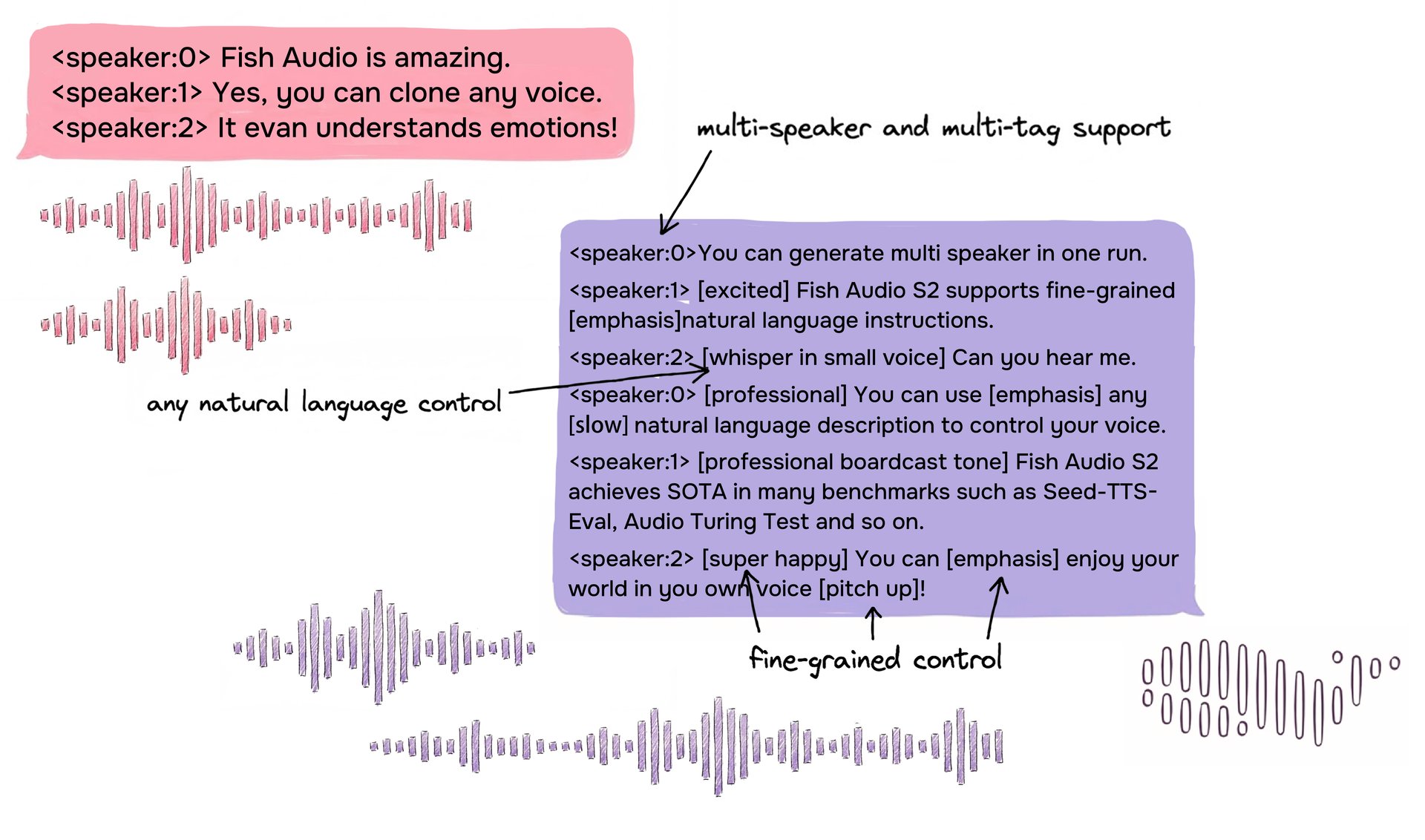 미세 제어를 위한 자유 형식 자연어 인라인 태그가 포함된 다중 화자 대화의 S2 입력 형식 예시.
미세 제어를 위한 자유 형식 자연어 인라인 태그가 포함된 다중 화자 대화의 S2 입력 형식 예시.
통합 레시피: 동일한 모델을 통한 데이터 큐레이션 및 RL 보상
S2의 핵심 아키텍처 결정 사항 중 하나는 학습 데이터를 필터링하고 주석을 다는 데 사용된 동일한 모델이 강화 학습(RL) 과정에서 보상 모델로 직접 재사용된다는 점입니다.
- **음성 품질 모델(Speech quality model)**은 데이터 필터링 시 SNR, 화자 일관성, 명료도 등의 차원에서 오디오 점수를 매기며, 이후 RL 단계에서 음향 선호도 보상 역할을 수행합니다.
- 풍부한 전사 ASR 모델(Rich-transcription ASR model)(Qwen3-Omni-30B-A3B에서 계속 사전 학습됨)은 데이터 큐레이션 중에 인라인 언어 외적 주석이 포함된 캡션 강화 전사본을 생성하며, 생성된 오디오를 다시 전사하여 원래 프롬프트와 비교함으로써 명료도 및 지침 준수 보상을 제공합니다.
이러한 이중 목적 설계는 사전 학습 데이터와 사후 학습 목표 간의 분포 불일치(distribution mismatch) 문제를 구조적으로 제거합니다. 이는 데이터 파이프라인과 별도로 보상 모델을 학습시키는 다른 TTS 시스템에서는 아직 해결되지 않은 문제입니다.
모델 내부: 이중 자기회귀(Dual-AR) 아키텍처
S2는 디코더 전용 트랜스포머와 RVQ 기반 오디오 코덱(10개 코드북, ~21Hz 프레임 속도)을 기반으로 구축되었습니다. 모든 코드북을 시간에 따라 평탄화(flattening)하면 시퀀스 길이가 10배로 늘어나는 문제가 발생합니다. S2는 이중 자기회귀(Dual-AR) 아키텍처를 통해 이를 해결합니다.
- Slow AR은 시간 축을 따라 작동하며 기본 시맨틱 코드북을 예측합니다.
- Fast AR은 각 타임스텝에서 나머지 9개의 잔차 코드북을 생성하여 미세한 음향 세부 사항을 재구성합니다.
시간 축을 따른 40억(4B) 파라미터와 깊이 축을 따른 4억(400M) 파라미터로 구성된 이 비대칭 설계는 오디오 충실도를 유지하면서도 추론 효율성을 높게 유지합니다.
음성을 위한 강화 학습 정렬
사후 학습을 위해 S2는 긴 오디오 컨텍스트에서 PPO 방식의 가치 모델(value models)이 초래하는 메모리 오버헤드를 피하기 위해 그룹 상대 정책 최적화(GRPO)를 사용합니다. 보상 신호는 다음과 같은 여러 차원을 결합합니다.
- 의미론적 정확성 및 지침 준수
- 음향 선호도 점수
- 음색 유사성
벤치마크 결과
S2는 여러 공개 벤치마크에서 선도적인 결과를 달성했습니다.
| 벤치마크 | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (중국어) | 0.54% (전체 최고) |
| Seed-TTS Eval — WER (영어) | 0.99% (전체 최고) |
| 오디오 튜링 테스트 (지침 포함) | 0.515 사후 평균 |
| EmergentTTS-Eval — 승률 | 81.88% (전체 최고) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — 품질 | 4.51 / 5.0 |
| 다국어 (MiniMax 테스트셋) — 최고 WER | 24개 언어 중 11개 |
| 다국어 (MiniMax 테스트셋) — 최고 SIM | 24개 언어 중 17개 |
Seed-TTS Eval에서 S2는 Qwen3-TTS (0.77/1.24), MiniMax Speech-02 (0.99/1.90), Seed-TTS (1.12/2.25) 등 폐쇄형 소스 시스템을 포함한 모든 평가 모델 중 가장 낮은 단어 오류율(WER)을 달성했습니다. 오디오 튜링 테스트에서 0.515는 Seed-TTS(0.417)보다 24%, MiniMax-Speech(0.387)보다 33% 높은 수치입니다. EmergentTTS-Eval에서 S2는 특히 언어 외적 요소(91.61% 승률), 질문(84.41%), 구문 복잡성(83.39%) 영역에서 매우 강력한 결과를 보여주었습니다.
SGLang을 통한 프로덕션 스트리밍
S2의 이중 자기회귀(Dual-AR) 아키텍처는 구조적으로 표준 자기회귀 LLM과 동형(isomorphic)이기 때문에, 연속 일괄 처리(continuous batching), 페이징된 KV 캐시(paged KV cache), CUDA 그래프 재생, RadixAttention 기반 프리픽스 캐싱 등 SGLang의 모든 LLM 네이티브 서빙 최적화를 최소한의 수정만으로 직접 상속받을 수 있습니다.
목소리 복제(voice cloning)의 경우, S2는 참조 오디오 토큰을 시스템 프롬프트에 배치합니다. SGLang의 RadixAttention은 이러한 KV 상태를 자동으로 캐싱하며, 동일한 목소리가 요청 간에 재사용될 때 평균 86.4%(피크 시 90% 이상)의 프리픽스 캐시 히트율을 달성하여 참조 오디오 프리필(prefill) 오버헤드를 거의 무시할 수 있는 수준으로 만듭니다.
단일 NVIDIA H200 GPU 기준:
- 실시간 계수 (RTF): 0.195
- 첫 오디오 생성 시간 (TTFA): 약 100ms
- 처리량: RTF 0.5 미만을 유지하면서 초당 3,000개 이상의 음향 토큰 처리
이번 릴리스의 의의
S2는 단순한 모델 체크포인트가 아니라 모델 가중치, 미세 조정 코드, 프로덕션 준비가 완료된 추론 스택을 포함한 완전한 시스템으로 릴리스되었습니다.
두 가지 설계 선택이 돋보입니다. 첫째, 통합된 데이터 및 보상 파이프라인은 다른 TTS 시스템이 아키텍처 수준에서 해결하지 못한 사전 학습과 RL 간의 분포 불일치라는 구조적 문제를 해결합니다. 둘째, 이중 자기회귀 아키텍처와 표준 LLM 간의 구조적 동형성은 S2가 맞춤형 추론 인프라를 요구하는 대신 LLM 서빙 최적화 생태계 전체를 활용할 수 있음을 의미합니다.
S2는 프로젝트의 GitHub 저장소, SGLang-Omni, HuggingFace 및 fish.audio의 대화형 데모를 통해 만나보실 수 있습니다.



