다중 음성 텍스트 음성 변환 — 멀티스피커 완벽 가이드 (Fish Audio)

단일 음성 TTS는 대화, 오디오북, 팟캐스트에서 밋밋하게 들립니다. 이 가이드에서는 Fish Audio에서 음성을 찾고 정리하는 방법과, TTS 및 Story Studio에서 멀티스피커 기능을 사용하여 전통적인 녹음 방식 없이도 자연스러운 다중 캐릭터 오디오를 제작하는 방법을 설명합니다.
2026년 3월 | Fish Audio 멀티스피커 TTS를 이제 S2 Pro에서 사용할 수 있습니다.
목차
- 멀티스피커 텍스트 음성 변환이란 무엇인가요?
- 1단계 — Discovery를 통해 적합한 음성 찾기
- 2단계 — Text to Speech에서의 멀티스피커 활용
- 3단계 — Story Studio에서의 멀티스피커 활용
- TTS vs Story Studio — 어떤 것을 사용해야 할까요?
- 활용 사례 — 멀티스피커 TTS로 무엇을 만들 수 있을까요?
- 대본에서 오디오까지 — 단 한 번의 세션으로
- 멀티스피커 TTS에 대해 자주 묻는 질문
대부분의 텍스트 음성 변환 도구는 하나의 음성, 하나의 내레이터, 처음부터 끝까지 하나의 톤만 제공합니다. 화자가 한 명인 설명 영상에는 괜찮을 수 있습니다. 하지만 대본에 두 캐릭터의 대화, 호스트와 게스트, 또는 뚜렷한 역할이 있는 이야기가 포함되는 순간, 단일 음성은 대화를 평면적이고 단조로운 낭독으로 만들어 버립니다. 청취자들은 금방 흥미를 잃습니다.
다중 음성 기능을 지원하는 텍스트 음성 변환은 이 문제를 해결합니다. 각 화자에게 서로 다른 AI 음성을 할당하고 화자 사이의 타이밍을 조절하면, 결과물은 실제 대화처럼 들리게 됩니다. Fish Audio는 음성 탐색부터 다중 챕터 내보내기까지 모든 과정을 아우르는 완전한 텍스트 음성 변환 대화 생성기 역할을 합니다. 이 가이드에서는 음성을 탐색하고 정리하는 방법부터, 짧은 콘텐츠를 위한 Text to Speech 도구에서의 멀티스피커 사용법, 그리고 Story Studio를 통해 전문적인 제작물로 확장하는 방법까지 전체 워크플로우를 안내합니다.
멀티스피커 텍스트 음성 변환이란 무엇인가요?
멀티스피커 텍스트 음성 변환은 대본의 각 세그먼트에 서로 다른 AI 음성(각각 고유한 톤, 성별, 연령 및 말하기 스타일을 가짐)을 할당한 다음, 이를 하나의 연속된 오디오 출력으로 생성하는 TTS 워크플로우입니다.
기존의 TTS 도구는 단일 내레이션 모델을 중심으로 구축되었습니다. 즉, 하나의 음성, 하나의 텍스트 입력, 하나의 오디오 파일 방식입니다. 이 방식은 한 명의 내레이터가 읽는 오디오북 낭독, 성우 녹음 또는 공지사항에는 적합합니다. 하지만 대화가 포함된 경우에는 완전히 한계에 부딪힙니다. 기존 도구로 두 캐릭터의 대화를 제작하려면 각 화자의 음성을 별도로 생성한 다음, 오디오 편집기에서 수동으로 이어 붙여야 했습니다. 이때 타이밍을 맞추고, 음량 수준을 조절하며, 전환 부위가 서로 다른 녹음처럼 들리지 않기를 바랄 뿐이었습니다.
문제는 추가적인 단계뿐만이 아닙니다. 전용 컨트롤 없이는 화자 사이의 타이밍을 맞추는 것이 거의 불가능하다는 점입니다. 실제 대화에는 리듬이 있습니다. 대답하기 전의 짧은 침묵, 누군가 말을 가로챌 때의 약간의 겹침, 어려운 질문에 답하기 전의 긴 멈춤 등이 그것입니다. 화자 간 간격을 정밀하게 제어하지 못하면 아무리 음성이 좋아도 대화가 로봇처럼 들리게 됩니다.
멀티스피커 TTS 도구는 이 두 가지 문제를 모두 해결합니다. 각 화자는 자신만의 음성과 텍스트 블록을 갖습니다. 화자 사이의 간격은 조절 가능합니다. 최종 결과물은 타이밍이 완벽하게 맞춰진 하나의 일관된 오디오 파일입니다.
멀티스피커 텍스트 음성 변환을 사용하면 다음과 같은 작업이 가능합니다:
- 대본의 각 화자에게 서로 다른 AI 음성 할당
- 각 화자 사이의 타이밍 및 일시 정지 제어
- 전체 대화를 하나의 연속된 오디오 파일로 생성
- 추가 내보내기나 수동 편집 없이 두 명의 짧은 대화에서 전체 출연진이 등장하는 대규모 제작물로 확장
1단계 — Discovery를 통해 적합한 음성 찾기
멀티스피커 프로젝트를 만들기 전에는 음성이 필요합니다. Fish Audio의 Discovery 페이지는 수만 개의 라이브러리에서 음성을 찾는 곳이며, 필터링 도구가 매우 중요합니다.
fish.audio/app/discovery/로 이동하세요.
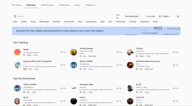
검색 및 필터링
Discovery 페이지는 검색창, 상단 행의 퀵 필터 태그, 그리고 우측의 정렬 및 언어 컨트롤로 시작됩니다.
찾고 있는 이름을 이미 알고 있다면 이름으로 검색하세요. 다른 제작자들에게 인기 있는 음성을 확인하려면 추천순(Recommended) 또는 트렌딩(Trending)으로 정렬하세요. 언어(Language) 필터는 전체 라이브러리를 대상 언어로 학습된 음성으로 좁혀줍니다.
상단 행의 퀵 필터 태그는 남성(Male), 여성(Female), 젊은(Young), 중년(Middle Aged), 내레이션(Narration), 소셜 미디어(Social Media), 깊은(Deep), 부드러운(Soft), 전문가(Professional), 드라마틱(Dramatic), 신비로운(Mysterious), 애니메이션(Anime) 등 가장 일반적인 속성을 포함하며, 이를 조합할 수 있습니다. 예를 들어 'Female + Young + Narration'을 선택하면 해당 프로필에 맞는 음성으로 결과가 즉시 좁혀집니다.

더 세밀한 제어를 위해 우측 상단의 필터 패널(슬라이더 아이콘)을 여세요. 여기서는 다음과 같은 옵션을 제공합니다:
- 언어(Languages) — 특정 언어로 좁히기 (다중 언어 매칭 지원)
- 태그(Tags) — 음성 제작자가 추가한 자유 형식 태그
- 성별(Gender) — 남성, 여성, 중성
- 연령(Age) — 청년, 중년, 노년
- 활용 사례(Use Case) — 대화형, 내레이션, 캐릭터 음성, 소셜 미디어, 교육용, 광고 등
- 음성 특성(Voice Qualities) — 깊은, 낮은, 중간, 높은, 부드러운, 밝은 등 48개 이상의 추가 설명어
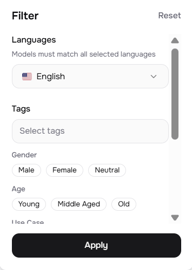
멀티스피커 프로젝트의 경우 '활용 사례'와 '음성 특성' 필터가 특히 유용합니다. 팟캐스트 스타일의 대화를 만들고 있다면 'Conversational + Soft' 음성 하나와 'Narration + Deep' 음성 하나를 선택하여, 청취자가 대본을 보지 않고도 목소리만으로 화자를 구분할 수 있게 할 수 있습니다.
좋아요, 북마크 및 Collection에 저장
다시 사용하고 싶은 음성을 찾았다면 몇 가지 저장 방법이 있습니다. 검색 결과의 각 음성 카드에 있는 하트 아이콘은 '좋아요' 기능으로, 나중에 참고할 수 있도록 'Likes' 탭에 음성을 추가합니다.
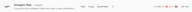
더 확실하게 저장하려면 음성 상세 페이지를 열고 Bookmark를 클릭하세요. 북마크된 음성은 'Bookmarks' 탭에 표시되며, TTS 및 Story Studio의 음성 선택기에서 직접 액세스할 수 있습니다.
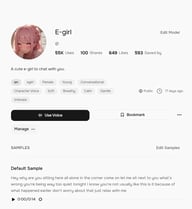
프로젝트 단위로 정리하려면 Collections 기능이 가장 강력합니다. 상단 내비게이션에서 Collections를 클릭한 다음, Create Collection을 눌러 "팟캐스트용" 또는 "오디오북 프로젝트 A"와 같은 이름의 그룹을 만드세요. 제목과 설명을 입력한 후 Create를 클릭합니다.

음성을 컬렉션에 추가하려면 음성 상세 페이지를 열고 북마크 버튼 옆의 더 보기(⋯) 메뉴를 클릭한 후 Add to Collection을 선택하세요. 이미 만든 컬렉션이 드롭다운에 표시되며, 클릭 한 번으로 음성을 추가할 수 있습니다.
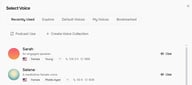
이 기능의 진가는 TTS나 Story Studio 내부에서 발휘됩니다. 음성 선택(Select Voice) 패널을 열면 상단에 최근 사용, 탐색, 기본 음성, 내 음성, 북마크와 함께 사용자의 컬렉션이 탭으로 표시됩니다. 매번 처음부터 검색할 필요 없이 프로젝트용으로 그룹화된 음성을 즉시 사용할 수 있습니다.
2단계 — Text to Speech에서의 멀티스피커 활용
Fish Audio의 Text to Speech 도구는 단일 생성 작업에서 여러 스피커를 지원합니다. 대화 스니펫, 광고, 짧은 팟캐스트 인트로, 데모 스크립트 등 챕터 관리 없이 빠르고 깔끔한 결과물이 필요한 중단편 콘텐츠에 적합합니다. 아직 음성을 찾지 못했다면 Discovery 라이브러리를 먼저 살펴보세요.
fish.audio/app/text-to-speech/로 이동하세요.
첫 번째 스피커 설정
TTS를 열면 상단에 음성 선택기가 있는 단일 텍스트 블록이 보입니다. 음성 이름을 클릭하여 음성 선택(Select Voice) 패널을 열고 첫 번째 스피커를 선택하세요. 그런 다음 첫 번째 화자의 대사를 텍스트 블록에 입력하거나 붙여넣으세요.
또한 인라인 감정 태그를 사용하여 [sad], [emphasis], [excited]와 같이 단어 앞에 배치함으로써 전달 방식을 조절할 수 있습니다.
추가 스피커 추가
첫 번째 텍스트 블록 아래의 + Add Speaker를 클릭하세요. 독립적인 음성 선택기가 있는 새 블록이 나타납니다. 이 스피커에 다른 음성을 선택하고 대사를 입력하면, 화면에 표시된 순서대로 두 블록이 하나의 연속된 오디오 파일로 생성됩니다.
추가할 수 있는 스피커 수에는 상한선이 없습니다. 각 블록은 독립적입니다. 즉, 서로 다른 음성, 텍스트, 감정 태그를 가질 수 있습니다. 실제 대화 프로젝트에서는 2~4개의 뚜렷한 음성을 사용하는 것이 청취자가 혼동하지 않으면서도 다양성을 주기에 좋습니다. 우측 패널에서는 생성 전 볼륨(Volume), 속도(Speed), 음량 정규화(Loudness Normalization), 그리고 숫자나 통화 등의 읽기 정확도를 높여주는 **텍스트 정규화(Text Normalization)**를 미세 조정할 수 있습니다.
글자 수 제한 및 Story Studio로 이동해야 할 시점
화면 하단의 글자 수 카운터를 확인하세요. 제한은 요금제에 따라 다르므로, 해당 등급의 구체적인 허용 한도는 Fish Audio 가격 및 플랜 페이지에서 확인하시기 바랍니다. 짧거나 중간 길이의 콘텐츠에는 TTS가 더 빠르고 간단한 워크플로우입니다. 하지만 전체 오디오북 챕터, 여러 세그먼트로 구성된 팟캐스트, 게임 대화 스크립트와 같은 긴 작업을 수행한다면 Story Studio가 필요한 도구를 제공합니다.
3단계 — Story Studio에서의 멀티스피커 활용
Story Studio는 장편 오디오 제작을 위해 설계되었습니다. TTS가 빠른 생성에 최적화되어 있다면, Story Studio는 블록별로 여러 음성을 배치할 수 있는 구조화된 환경을 제공하며, 스피커 간의 정밀한 타이밍 제어와 복잡한 프로젝트를 위한 챕터 구성을 지원합니다. 각 블록은 할당된 음성으로 독립적으로 생성되며, 최종 내보내기 시 하나의 연속된 파일로 결합됩니다. fish.audio/app/story-studio/로 이동하세요.
새 프로젝트 만들기
Story Studio 홈 화면에서 + Project를 클릭하세요. Create project 대화상자에서 다음 설정을 확인합니다:
- Project Name — 프로젝트 이름
- Default Voice — 새 블록에 기본적으로 할당될 음성 (블록별로 변경 가능)
- Speech Model — 현재 S2 Pro (최신)
- Text Normalization — 활성화 시 숫자, 통화, 날짜 등의 읽기 정확도 향상
- Loudness Normalization — 일관된 출력을 위해 블록 간 볼륨 수준 정규화
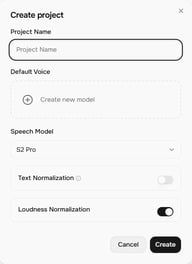
Create를 클릭하여 프로젝트 편집기를 엽니다.
블록 추가 및 음성 전환
프로젝트를 열면 기본 챕터와 첫 번째 텍스트 블록이 이미 준비되어 있습니다. 첫 번째 스피커의 음성은 각 블록 왼쪽의 컬러 아바타로 표시됩니다.
새로운 화자의 대사를 추가하려면 기존 블록 아래의 + 버튼을 클릭하세요. 새 블록이 나타납니다. 새 블록 왼쪽의 컬러 음성 아바타를 클릭하여 음성 선택 패널을 열고 다른 음성을 할당하세요. 그런 다음 두 번째 화자의 대사를 입력합니다.
대본의 모든 대화에 대해 이 과정을 반복하세요. 각 블록은 한 명의 화자 차례를 의미합니다. 우측 패널에는 프로젝트에 사용된 음성(Voices used in the project) 목록이 실시간으로 표시되어, 출연진 구성을 한눈에 파악할 수 있습니다.
스피커 간 일시 정지 미세 조정
각 블록 사이에는 현재 간격을 나타내는 작은 타이밍 버블(예: 0.35s)이 표시됩니다. 이를 클릭하여 해당 화자들 사이의 일시 정지 길이를 조정할 수 있습니다.
이는 대화의 사실감을 높여주는 Story Studio의 가장 중요한 기능 중 하나입니다. 실제 대화는 완벽하게 꼬리에 꼬리를 무는 발화의 연속이 아닙니다. 대답 전의 짧은 침묵은 생각하는 시간을 나타내고, 감정적인 반응 앞의 긴 멈춤은 무게감을 더합니다. 이 간격을 적절히 맞추는 것이 기계적인 소리와 실제 같은 소리를 가르는 차이입니다. 0.2~0.5초의 미세한 조정만으로도 대화의 자연스러움이 현격히 달라집니다. 모든 간격을 기본값으로 두기보다는 각 장면에 맞춰 개별적으로 튜닝하는 것을 추천합니다. 장면의 리듬에 맞춰 각 블록 사이의 정지 시간을 개별적으로 조정해 보세요.
장편 프로젝트를 위한 챕터 추가
편집기 왼쪽에는 챕터(Chapters) 패널이 있습니다. 기본적으로 모든 프로젝트는 하나의 "Default Chapter"로 시작합니다. **+**를 눌러 새 챕터를 추가하세요.
챕터를 사용하면 장편 프로젝트를 탐색 가능한 섹션으로 나눌 수 있습니다. 오디오북의 섹션별, 팟캐스트의 세그먼트별, 또는 게임 스크립트의 장면별로 챕터를 나눌 수 있습니다. 각 챕터는 고유한 블록 시퀀스를 가지며 독립적으로 작업할 수 있습니다. 최종 내보내기 시에는 모든 챕터가 순서대로 하나의 결과물로 결합됩니다.
수백 단어 이상의 대화가 포함된 프로젝트라면 챕터 기능을 통해 Story Studio 프로젝트를 체계적으로 관리하고 편집할 수 있습니다.
TTS vs Story Studio — 어떤 것을 사용해야 할까요?
| Text to Speech | Story Studio | |
|---|---|---|
| 멀티스피커 방식 | 네이티브 (S2 Pro 모델 레벨) | 순차적 블록 생성 |
| 글자 수 제한 | 플랜에 따라 다름 | 제한 없음 (다중 챕터) |
| 스피커 수 | 최대 5명 | 무제한 |
| 스피커 간 일시 정지 제어 | ❌ | ✅ 블록별 정밀 제어 |
| 챕터 관리 | ❌ | ✅ |
| 타임라인 뷰 | ❌ | ✅ |
| 적합한 용도 | 짧은 대화, 광고, 데모 | 오디오북, 팟캐스트, 게임 스크립트, 장편 제작 |
핵심적인 기술적 차이: TTS는 S2 Pro 모델의 네이티브 멀티스피커 기능을 사용하여 단일 생성 과정에서 여러 화자를 처리합니다. Story Studio는 개별적으로 생성된 블록(각각 고유한 음성 할당)을 순차적으로 배치하여 하나의 연속된 파일로 만드는 방식으로 멀티스피커 출력을 구현합니다.
두 명의 화자가 등장하는 30초 광고나 짧은 대화 클립을 만든다면 TTS를 사용하세요. 더 빠르고 별도의 프로젝트 설정이 필요 없습니다. 대본이 길거나, 대화가 여러 번 오가거나, 화자 간의 정밀한 타이밍이 필요하다면 Story Studio를 여는 것이 좋습니다.
활용 사례 — 멀티스피커 TTS로 무엇을 만들 수 있을까요?
다중 캐릭터 오디오북
단일 내레이터 오디오북은 비문학 도서에 적합합니다. 하지만 대화가 포함된 소설의 경우, 한 명의 목소리로 모든 캐릭터를 읽으면 내용을 따라가기 어려울 수 있습니다. 멀티스피커 TTS를 사용하면 장면 속 각 캐릭터에게 고유한 목소리를 부여할 수 있습니다. 한 캐릭터는 깊고 중후한 음성으로, 다른 캐릭터는 젊고 에너지가 넘치는 음성으로 설정할 수 있죠. Story Studio의 챕터 구조는 책의 챕터와 직접 매칭되므로, 전통적인 캐스팅과 녹음 과정 없이도 완편 오디오북을 제작하는 것이 현실적으로 가능해집니다.
팟캐스트 스타일 대화
두 명의 호스트가 진행하는 팟캐스트 형식은 가장 대중적인 오디오 구조 중 하나입니다. 대화형 멀티스피커 AI 음성 생성기를 사용하면 대본만으로 이러한 형식을 구현할 수 있습니다. 각 호스트에게 음성을 부여하고 정교한 일시 정지를 통해 자연스러운 차례 교대를 재현할 수 있습니다. 이는 녹음 세션을 예약하기 어려운 콘텐츠 제작자들에게 특히 유용합니다.
이러닝(E-Learning) 및 교육 콘텐츠
교육 콘텐츠는 단조로운 독백보다 대화 형식으로 전달될 때 훨씬 더 높은 몰입감을 줍니다. 교사와 학생의 질의응답, 가이드 시나리오 등을 두 명 이상의 음성으로 구성하여 학습자가 수동적인 내레이션이 아닌 대화를 통해 정보를 더 효과적으로 처리하도록 도울 수 있습니다.
게임 대화 및 캐릭터 음성
게임 스크립트는 여러 캐릭터에 걸쳐 수백, 수천 줄의 대사로 구성되는 경우가 많습니다. Story Studio를 다중 캐릭터 음성 생성기로 활용하면 게임 개발자와 내러티브 디자이너는 프로토타이핑, 데모 또는 정식 제작을 위한 음성 대화를 생성할 수 있습니다. 전통적인 성우 녹음 없이도 각 NPC에게 모든 대사에 걸쳐 일관된 음성을 부여할 수 있습니다.
대본에서 오디오까지 — 단 한 번의 세션으로
여러 캐릭터가 등장하는 오디오를 제작하려면 과거에는 성우를 섭외하고, 녹음 일정을 조율하며, 후반 작업에서 수 시간 동안 오디오를 이어 붙여야 했습니다. 멀티스피커 TTS를 사용하면 이 모든 워크플로우가 단 한 번의 세션으로 축소됩니다. Discovery에서 음성을 찾고, Collection으로 정리하고, 블록별로 대본을 구성한 뒤 내보내기만 하면 됩니다.
짧은 콘텐츠라면 Text to Speech를 통해 몇 분 안에 완성할 수 있습니다. 오디오북, 팟캐스트 시리즈, 게임 대화와 같은 장편 제작물이라면 Story Studio가 실제 연기한 것처럼 들리는 결과물을 만들 수 있는 구조와 타이밍 제어 기능을 제공합니다.

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






