我们将我们的 TTS 与所有主要竞争对手进行了盲测。以下是结果。

我们将我们的 TTS 与所有主要竞争对手进行了盲测。以下是结果。
Fish Audio 在实际生产流量上进行了一项为期 10 天的 A/B 盲测,将 Fish Audio S2 Pro 和 S1 与 ElevenLabs、Inworld 和 MiniMax 进行了对比。我们从完全不知道音频是由哪个供应商生成的真实用户那里,收集了超过 5,000 组偏好对数据。
TLDR:结果
Fish Audio S2 Pro 排名全场第一,Bradley-Terry (BT) 得分为 3.07,几乎是第二名模型的 1.7 倍。我们的旧模型 Fish Audio S1 (BT 1.86) 的综合表现也优于所有第三方供应商。
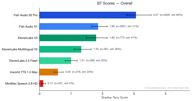
| 排名 | 模型 | BT 得分 | 胜率 | 样本量 |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3.07 | 65.7% | 4,573 |
| 2 | Fish Audio S1 | 1.86 | 41.0% | 3,560 |
| 3 | ElevenLabs V3 | 1.80 | 40.6% | 766 |
| 4 | ElevenLabs Multilingual V2 | 1.35 | 36.2% | 359 |
| 5 | ElevenLabs 2.5 Flash | 1.00 | 29.8% | 364 |
| 6 | Inworld TTS 1.5 Max | 0.59 | 20.1% | 373 |
| 7 | MiniMax Speech 2.8 HD | 0.12 | 5.0% | 201 |
关键强强对话:
- Fish S2 Pro 以 60% 对 40% 击败 ElevenLabs V3 (581 组数据)
- Fish S2 Pro 以 80% 对 20% 击败 Inworld (261 组数据)
- Fish S2 Pro 以 95% 对 5% 击败 MiniMax (142 组数据)
- Fish S1 以 64% 对 36% 击败 ElevenLabs V3 (150 组数据)
我们为什么要这样做
传统指标的问题
MOS (平均主观意见分) 仍然是 TTS 评估的事实标准,但它存在严重缺陷。测试条件很少公开——样本长度、听众的人口统计学特征、播放环境和评分指令在不同研究中各不相同,这使得跨论文比较毫无意义。与此同时,WER/CER (词/字符错误率) 作为优化目标可能会适得其反:过度追求降低 WER 通常会迫使模型产生过度发音的、机械化的语音,为了清晰度而牺牲了自然度和韵律。一个偶尔像真人一样含糊不清的模型,实际上可能比一个每个音节都发音完美的模型听起来更好。
现有排行榜的问题
像 TTS-Arena-V2 和 Artificial Analysis 这样的公共排行榜通常在简短的句子上评估模型——通常是单行对话或简短的旁白。这无法捕捉到现实世界中 TTS 使用的复杂性:长内容、多角色对话、富有表现力的韵律标签以及多语言文本。
除了方法论之外,还存在诚信问题。TTS-Arena-V2 曾出现过已知的音频头泄露问题,音频文件中的元数据可能会揭示供应商身份,从而破坏了盲测评估的前提。我们也意识到排行榜刷榜现象非常普遍:供应商针对基准测试句子进行专门优化,提交精心挑选的模型检查点,或者通过协同投票来提高排名。这些排行榜已经变成了营销工具,而不是可靠的质量信号。
我们真正想要的是什么
我们需要一个可靠的内部奖励信号——一个衡量“真实用户到底更喜欢哪种 TTS 输出?”的基准指标,以便我们可以信赖它来做出模型开发决策。不是论文中的数字,不是可操纵排行榜上的排名,而是来自做出真实选择的用户所提供的源源不断的真实偏好数据。
因此,我们直接在生产平台中构建了一个盲测评估流水线。
实验设计
盲样对齐比较
Fish Audio 的编辑器会为每个 TTS 任务并排向用户展示两个音频版本。每个版本都有 10% 的概率被静默路由到竞争供应商,而不是默认的 Fish Audio 后端。相同的文本、相同的参考音色、相同的界面——用户完全不知道哪个供应商生成了哪个音频。
实验运行了 10 天 (2026 年 3 月 26 日至 4 月 5 日),共收集了 71,000 多组配对数据,其中 5,098 组包含符合我们质量标准的跨供应商比较。
什么算作“胜出”
我们使用严格的行为信号,而不是主观评分:
- 用户必须播放两个版本各至少 2 次——确认他们确实对比了两者
- 只有一个版本被下载——该版本即为获胜者
这种“先听后下”的信号比星级评价或强迫选择调查要可靠得多。用户是在为他们将要实际使用的音频做出真实决策。
用户构成
实验样本中大约包含 70% 的新用户和 30% 的老用户。这种构成可能会对 Fish Audio 产生轻微偏见(老用户已经熟悉我们的平台),但也确保了我们捕捉到了大多数参与者最真实的初次印象偏好。
音色选择
我们在实验中使用了平台上前 500 名的热门公共音色。每个音色都预先克隆到第三方供应商的系统中,确保两边都能使用相同的参考音色身份。音色 ID 映射维护在专门的 JSON 映射文件中,作为路由资格的唯一事实来源。
供应商与测试模型
| 供应商 | 模型 | 路由目标 |
|---|---|---|
| Fish Audio | S2 Pro (最新版) | fish:s2-pro |
| Fish Audio | S1 (上一代) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
评估覆盖范围与标签支持
并非所有供应商都支持相同的功能集。Fish Audio S2 Pro 支持丰富的韵律标签(例如 [laughs],[sighs])和用于多说话人内容的话者标签(<|speaker:N|>)。这一点很重要,因为我们的生产流量自然包含带标签的文本。
- ElevenLabs V3 接受了最完整的评估——它在归一化为括号形式后支持任意标签,因此几乎符合所有请求的条件,无论内容如何
- ElevenLabs 2.5 Flash 和 Multilingual V2 —— 我们只向这些模型发送纯文本请求(无标签)
- Inworld —— 仅限纯文本,且限制为
mp3输出格式,进一步限制了其符合条件的流量 - MiniMax —— 接受感叹词标签(
(laughs),(sighs)等),但拒绝其他标签类型。由于用户偏好结果持续低迷,实验被提前停止,以避免进一步损害用户体验
路由系统根据当前请求的功能(语言、标签、格式、多参考音色)评估每个备选供应商。只有受支持的备选方案才成为符合条件的候选者,并通加权随机选择其中之一。如果唯一的符合条件的备选方案是 Fish 与 Fish 的比较(S1 vs S2 Pro),则有效采样概率将降低至基础比率的 1/10,以优先收集跨供应商数据。
我们的成本支出
这些实验并非免费。大规模调用第三方 TTS API 非常昂贵:
- ElevenLabs:API 调用花费 $1,500+
- MiniMax:花费 $330 (因表现不佳提前停止)
- Inworld:花费 $170

统计方法论
Bradley-Terry 模型
当不同模型以不同频率面对不同对手时,原始胜率可能会产生误导。Bradley-Terry 模型 通过从两两比较数据中计算全局强度得分来解决这个问题。它通过迭代估计每个模型的潜在“强度”参数,使得任意两个模型之间预测的获胜概率与观察到的数据相匹配。
对于具有 BT 得分 和 的两个模型 和 :
我们的实现运行多达 500 次迭代,收敛容差为 ,并在每一步使用几何平均值对分数进行归一化。
置信区间
我们报告了根据偏好对数据的 200 次重采样计算出的 95% 自举 (bootstrap) 置信区间。每次重采样从原始 对数据中有放回地抽取 对数据,并重新运行完整的 BT 计算。自举得分的第 2.5 个和第 97.5 个百分位数构成了置信区间边界。
对于每个后端的胜率,我们使用 Wilson 得分区间,它在极端胜率下比正态近似区间提供更好的覆盖范围。
分语言结果
拉丁语系语言 (英语、西班牙语、法语、德语等)
拉丁语系语言是最大的细分市场,拥有 4,173 组偏好对数据。
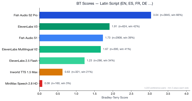
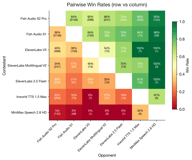
Fish S2 Pro 以 3.05 领先。值得注意的是,ElevenLabs V3 (1.90) 在这一类别中略微优于 Fish S1 (1.72) —— 这是唯一一个有竞争对手超过我们旧语言模型的语言组。ElevenLabs Multilingual V2 表现也很好,得分为 1.70,紧随 S1 之后。
这符合常理:ElevenLabs 历史上一直专注于英语和欧洲语言,其 V3 模型在这一领域非常强大。尽管如此,Fish S2 Pro 仍然对 ElevenLabs V3 保持了 1.6 倍的优势。
中文
中文拥有 329 组偏好对数据,并显示出 Fish Audio 最显著的统治地位。
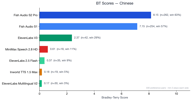
两款 Fish Audio 模型 (S2 Pro 为 8.11, S1 为 7.11) 均大幅领先于所有竞争对手。ElevenLabs V3 获得 2.36 分 —— 表现尚可但远落后。所有其他竞争对手的分数都低于 1.0。
日语
日语拥有 354 组偏好对数据。
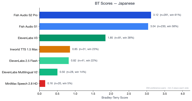
Fish S2 Pro (3.12) 和 Fish S1 (3.02) 非常接近,均远领先于 ElevenLabs V3 (1.88)。Fish 模型与竞争对手之间的差距在 CJK (中日韩) 语言中最大。
跨语言总结
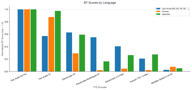
Fish Audio S2 Pro 在每个语言类别中均排名第一。竞争差距各不相同:
- 拉丁语系:竞争对手最接近,ElevenLabs V3 具有真正的竞争力 (相对得分 0.62)
- 中文:Fish Audio 具有压倒性优势,竞争对手几乎没有存在感
- 日语:与中文类似 —— Fish 模型遥遥领先
局限性
排除 API 用户
为了确保平台稳定性,API 用户未被纳入实验。10% 的采样率仅适用于 Web 平台用户。这意味着我们的结果反映了 Web 平台的使用模式,可能与 API 密集型的生产工作负载有所不同。
标签支持造成了覆盖不均
由于第三方供应商对标签的支持程度不同,他们接收到的流量子集也不同:
- ElevenLabs V3 符合几乎所有请求的条件 (支持标签)
- ElevenLabs Flash/Multilingual 仅接收无标签请求
- Inworld 仅接收无标签、mp3 格式的请求
这意味着竞争环境并非完全平等。ElevenLabs V3 的结果与 Fish Audio 最具直接可比性,因为它接收了最具代表性的流量样本。其他模型是在偏向于更简单的纯文本请求的子集上进行评估的 —— 理论上这应该对它们更有利。
MiniMax 结果可能不可靠
MiniMax Speech 2.8 HD 的得分极低 (BT 0.12, 胜率 5% —— 甚至低于 Inworld)。我们怀疑我们的 MiniMax API 集成可能不是最优的。在听取了几个 MiniMax 生成的样本后,我们无法确定具体的技术问题 —— 音频是清晰的,但与其他供应商相比,其韵律和自然度明显较差。我们在实验中期扩大了 MiniMax 的路由资格以增加样本量,但表现并未改善。在累积了 330 美元的 API 成本且没有竞争结果迹象后,实验被提前停止。
如果 MiniMax 认为这些结果不能反映其模型的真实能力,我们欢迎对其集成进行协作审查。
音色映射约束
只有在第三方平台上成功克隆的音色才能进行路由。如果音色克隆失败,该音色将被排除在该供应商的合格池之外。这意味着每个供应商都是在 Top 500 音色的稍微不同 (尽管大部分重叠) 的子集上进行测试的。
可能存在的平台熟悉度偏见
虽然我们采样了约 70% 的新用户,但剩下的约 30% 老用户可能已经养成了符合 Fish Audio 音频特性的偏好。我们认为考虑到大多数用户是新用户,这种影响很小,但不能完全排除。
结论
我们相信这是有史以来对 TTS 质量进行的最严谨的公开评估之一:
- 真实用户,而非受薪标注员
- 盲样比较 —— 用户永远不知道音频是由哪个供应商生成的
- 行为信号 (下载) 而非主观评分
- 生产流量 具有现实世界的文本复杂性,包括长内容、韵律标签和多语言文本
- 5,000 多组偏好对数据 涵盖多种语言,历时 10 天收集
- 仅第三方 API 调用就花费了 2,000 多美元
结果显而易见:Fish Audio S2 Pro 是所有测试语言中首选的 TTS 模型,在中日文方面具有特别强大的优势。甚至我们的上一代 S1 模型在综合表现上也优于所有竞争对手。
这些结果进一步验证了我们关于端到端建模和 RLHF (来自人类反馈的强化学习) 的路线图。 我们致力于透明化。方法论、路由逻辑和分析代码都是我们平台基础设施的一部分。我们邀请 TTS 社区审查我们的方法,并为未来的评估提出改进建议。
本次评估由 Fish Audio 团队于 2026 年 3 月 26 日至 4 月 5 日进行。如有疑问或讨论方法论,请通过 fish.audio 联系我们。








