Fish Audio 开源 S2:精细化控制与生产级流式推理
2026年3月9日
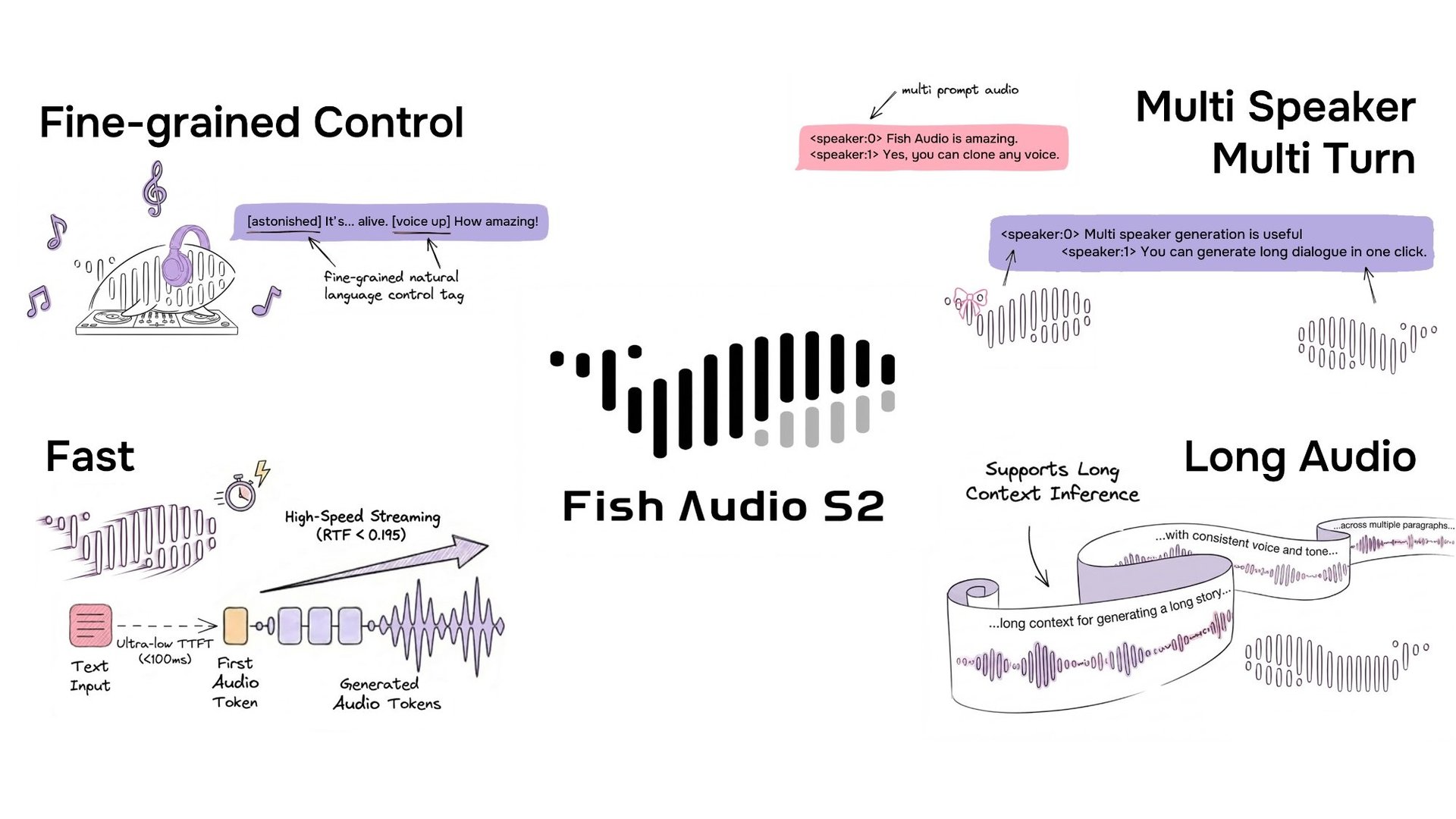
S2 Pro 现已在 Fish Audio App 上线,其开源版本可通过项目的 GitHub 仓库 和 HuggingFace 获取。
Fish Audio 现已开源 S2,这是一款支持通过自然语言标签(如 [laugh]、[whispers] 和 [super happy])对韵律和情感进行精细化行内(inline)控制的文本转语音模型。该系统基于约 50 种语言、超过 1000 万小时的音频数据训练,结合了强化学习对齐与双自回归(Dual-AR)架构。此次发布包含模型权重、微调代码以及基于 SGLang 的流式推理引擎。
通过自然语言进行精细化行内控制
S2 通过在文本中特定单词或短语位置嵌入自然语言指令,实现了行内控制。S2 并不依赖于一组固定的预定义标签,而是接受自由格式的文本描述——如 [whisper in small voice](小声耳语)、[professional broadcast tone](专业播音腔)或 [pitch up](提高音调)——允许在词级进行开放式的表达控制。
在音频图灵测试中,S2 在指令重写后的后验均值为 0.515,相比之下 Seed-TTS 为 0.417,MiniMax-Speech 为 0.387。在 EmergentTTS-Eval 评估中,相比 gpt-4o-mini-tts 基准,S2 达到了 81.88% 的综合胜率——在包括 Google 和 OpenAI 的闭源系统在内的所有评估模型中排名第一。
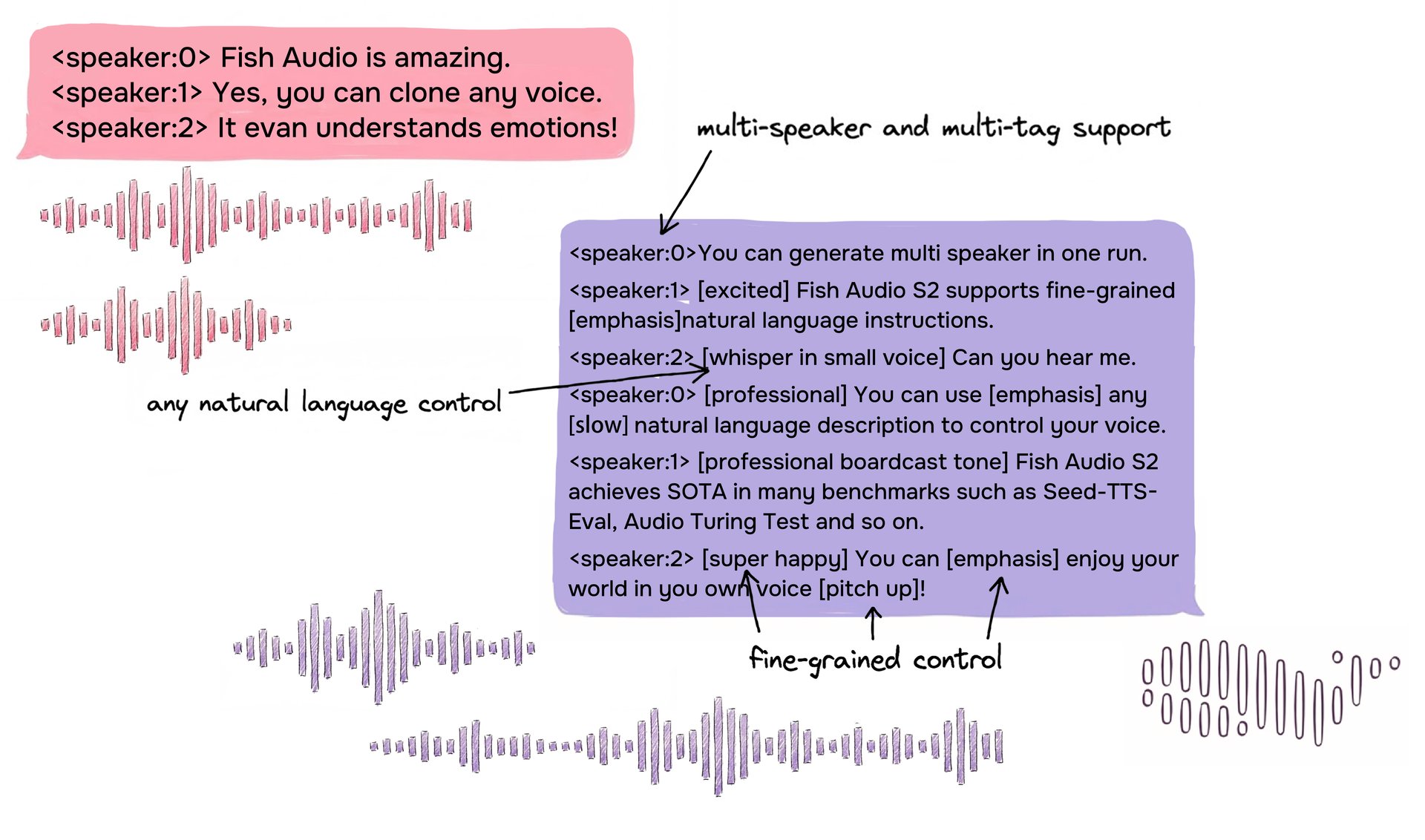 展示了多发言人对话及使用自由格式自然语言行内标签进行精细化控制的 S2 输入格式示例。
展示了多发言人对话及使用自由格式自然语言行内标签进行精细化控制的 S2 输入格式示例。
统一配方:来自相同模型的数据清洗与 RL 奖励
S2 的核心架构决策之一是:用于过滤和标注训练数据的模型,在强化学习(RL)阶段被直接复用为奖励模型:
- 语音质量模型:在数据过滤期间对音频的信噪比(SNR)、发言人一致性和清晰度等维度进行评分,然后在 RL 期间充当声学偏好奖励。
- 富转录 ASR 模型(基于 Qwen3-Omni-30B-A3B 进行持续预训练):在数据清洗期间生成带有行内副语言注释的增强字幕转录,然后通过重新转录生成的音频并与原始提示词进行对比,提供清晰度和指令遵循奖励。
这种双重用途的设计从结构上消除了预训练数据与后训练目标之间的分布不匹配(distribution mismatch)——这是其他将奖励模型与数据流水线分开训练的 TTS 系统尚未解决的问题。
深入模型:双自回归(Dual-AR)架构
S2 基于 decoder-only Transformer 架构,并结合了基于 RVQ 的音频编解码器(10 个 codebook,~21 Hz 帧率)。将所有 codebook 沿时间轴展平会导致序列长度爆炸 10 倍。S2 通过双自回归(Dual-AR)架构解决了这一问题:
- Slow AR:沿时间轴运行,预测主要的语义 codebook。
- Fast AR:在每个时间步生成剩余的 9 个残差 codebook,重建精细的声学细节。
这种非对称设计——时间轴上 4B 参数,深度轴上 400M 参数——在保持音频保真度的同时保证了推理效率。
语音强化学习对齐
在后训练阶段,S2 使用了群体相对策略优化(GRPO),旨在避免长音频语境下 PPO 式价值模型的内存开销。奖励信号结合了多个维度,包括:
- 语义准确性与指令遵循
- 声学偏好评分
- 音色相似度
基准测试结果
S2 在多个公开基准测试中均取得了领先成绩:
| 基准测试 | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (中文) | 0.54% (全场最佳) |
| Seed-TTS Eval — WER (英文) | 0.99% (全场最佳) |
| 音频图灵测试 (带指令) | 0.515 后验均值 |
| EmergentTTS-Eval — 胜率 | 81.88% (全场最高) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — 质量 | 4.51 / 5.0 |
| 多语言 (MiniMax 测试集) — 最佳 WER | 24 种语言中的 11 种 |
| 多语言 (MiniMax 测试集) — 最佳 SIM | 24 种语言中的 17 种 |
在 Seed-TTS Eval 上,S2 在所有评估模型(包括闭源系统)中实现了最低的 WER:Qwen3-TTS (0.77/1.24)、MiniMax Speech-02 (0.99/1.90)、Seed-TTS (1.12/2.25)。在音频图灵测试中,0.515 的得分比 Seed-TTS (0.417) 高出 24%,比 MiniMax-Speech (0.387) 高出 33%。在 EmergentTTS-Eval 上,S2 在副语言(91.61% 胜率)、提问(84.41%)和语法复杂性(83.39%)方面表现尤为强劲。
通过 SGLang 实现生产级流式传输
由于 S2 的 Dual-AR 架构在结构上与标准的自回归 LLM 同构,因此它可以直接继承来自 SGLang 的所有原生 LLM 服务优化,只需极少的修改——包括连续批处理(continuous batching)、分页 KV 缓存(paged KV cache)、CUDA graph 重放以及基于 RadixAttention 的前缀缓存。
对于语音克隆,S2 将参考音频 token 放置在系统提示词中。SGLang 的 RadixAttention 会自动缓存这些 KV 状态。在跨请求重复使用同一声音时,平均前缀缓存命中率达到 86.4%(峰值超过 90%),这使得参考音频的预填充开销几乎可以忽略不计。
在单张 NVIDIA H200 GPU 上:
- 实时因子 (RTF): 0.195
- 首包延迟 (Time-to-first-audio): 约 100 ms
- 吞吐量: 在保持 RTF 低于 0.5 的情况下,每秒产出 3,000+ 声学 token
为什么这次发布意义重大
S2 不仅仅是作为一个模型权重发布,而是一个完整的系统:包含模型权重、微调代码和生产就绪的推理栈。
两个设计选择脱颖而出。首先,统一的数据与奖励流水线从架构层面消除了预训练与 RL 之间的分布不匹配这一结构性问题,而其他 TTS 系统尚未在架构层面解决此问题。其次,Dual-AR 架构与标准 LLM 的结构同构性意味着 S2 可以利用 LLM 服务优化的完整生态系统,而无需定制推理基础设施。
S2 现可通过项目的 GitHub 仓库、SGLang-Omni、HuggingFace 获取,并在 fish.audio 提供交互式演示。



