Realizamos Testes Cego de Nosso TTS Contra Todos os Principais Concorrentes. Aqui Estão os Resultados.

Realizamos Testes Cego de Nosso TTS Contra Todos os Principais Concorrentes. Aqui Estão os Resultados.
A Fish Audio realizou um teste A/B cego de 10 dias em tráfego de produção real, colocando o Fish Audio S2 Pro e o S1 contra ElevenLabs, Inworld e MiniMax. Mais de 5.000 pares de preferência foram coletados de usuários reais que não tinham ideia de qual provedor gerou qual áudio.
Resumo: Resultados
O Fish Audio S2 Pro ficou em 1º lugar geral com uma pontuação Bradley-Terry de 3,07, quase 1,7x superior ao próximo melhor modelo. Nosso modelo anterior, o Fish Audio S1 (BT 1,86), também superou todos os provedores de terceiros no agregado.
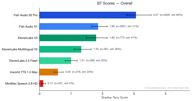
| Classificação | Modelo | Pontuação BT | Taxa de Vitória | Amostras |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3,07 | 65,7% | 4.573 |
| 2 | Fish Audio S1 | 1,86 | 41,0% | 3.560 |
| 3 | ElevenLabs V3 | 1,80 | 40,6% | 766 |
| 4 | ElevenLabs Multilingual V2 | 1,35 | 36,2% | 359 |
| 5 | ElevenLabs 2.5 Flash | 1,00 | 29,8% | 364 |
| 6 | Inworld TTS 1.5 Max | 0,59 | 20,1% | 373 |
| 7 | MiniMax Speech 2.8 HD | 0,12 | 5,0% | 201 |
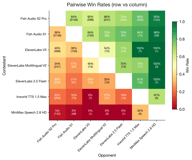
Principais confrontos diretos:
- Fish S2 Pro vence ElevenLabs V3 por 60% a 40% (581 pares)
- Fish S2 Pro vence Inworld por 80% a 20% (261 pares)
- Fish S2 Pro vence MiniMax por 95% a 5% (142 pares)
- Fish S1 vence ElevenLabs V3 por 64% a 36% (150 pares)
Por Que Fizemos Isso
O Problema com as Métricas Tradicionais
O MOS (Mean Opinion Score) continua sendo o padrão de fato para avaliação de TTS, mas é profundamente falho. As condições dos testes raramente são divulgadas — a duração da amostra, a demografia dos ouvintes, o ambiente de reprodução e as instruções de avaliação variam entre os estudos, tornando as comparações entre artigos sem sentido. Enquanto isso, o WER/CER (taxa de erro de palavra/caractere) pode ser contraproducente como meta de otimização: forçar o WER para níveis muito baixos muitas vezes leva o modelo a uma fala hiperarticulada e robótica que sacrifica a naturalidade e a prosódia em favor da inteligibilidade. Um modelo que ocasionalmente resmunga como um humano real pode, na verdade, soar melhor do que um que enuncia cada sílaba perfeitamente.
O Problema com os Rankings Existentes
Rankings públicos como o TTS-Arena-V2 e o Artificial Analysis avaliam modelos em frases curtas e simples — normalmente uma única linha de diálogo ou uma breve narração. Isso falha em capturar a complexidade do uso real de TTS: conteúdo de formato longo, diálogos com múltiplos interlocutores, tags de prosódia expressivas e texto multilíngue.
Além da metodologia, existem preocupações com a integridade. O TTS-Arena-V2 teve problemas conhecidos de vazamento de cabeçalho de áudio, onde metadados no arquivo de áudio poderiam revelar a identidade do provedor — quebrando a premissa da avaliação cega. Também estamos cientes de que a manipulação de rankings é generalizada: provedores otimizam especificamente para frases de referência, enviam checkpoints de modelos selecionados a dedo ou inflam classificações por meio de votação coordenada. Esses rankings tornaram-se ferramentas de marketing em vez de sinais confiáveis de qualidade.
O Que Realmente Queríamos
Precisávamos de um sinal de recompensa interno confiável — uma medida de verdade fundamental sobre "qual saída de TTS os usuários reais realmente preferem?" em que pudéssemos confiar para decisões de desenvolvimento de modelos. Não um número de um artigo científico, não uma posição em um ranking manipulável, mas um fluxo contínuo de dados de preferência honestos de usuários fazendo escolhas reais.
Por isso, construímos um pipeline de avaliação cega diretamente em nossa plataforma de produção.
Design do Experimento
Comparação Pareada Cega
O estúdio da Fish Audio apresenta aos usuários duas versões de áudio lado a lado para cada tarefa de TTS. Cada versão tem, independentemente, 10% de chance de ser silenciosamente roteada para um provedor concorrente em vez do backend padrão da Fish Audio. Mesmo texto, mesma voz de referência, mesma interface — o usuário não tem ideia de qual provedor gerou qual áudio.
O experimento durou 10 dias (26 de março a 5 de abril de 2026) e coletou mais de 71.000 grupos pareados, dos quais 5.098 continham comparações entre provedores que atenderam aos nossos critérios de qualidade.
O Que Conta Como uma "Vitória"
Usamos um sinal comportamental rigoroso, não uma avaliação subjetiva:
- O usuário deve reproduzir ambas as versões pelo menos 2 vezes cada — confirmando que ele realmente comparou ambas
- Exatamente uma versão é baixada — essa é a vencedora
Este sinal de "ouvir e depois baixar" é muito mais confiável do que avaliações por estrelas ou pesquisas de escolha forçada. Os usuários estão tomando decisões reais sobre o áudio que realmente irão utilizar.
Composição dos Usuários
O experimento amostrou aproximadamente 70% de novos usuários e 30% de usuários recorrentes. Essa composição pode introduzir um leve viés em direção à Fish Audio (usuários recorrentes já estão familiarizados com nossa plataforma), mas também garante que capturemos preferências genuínas de primeira impressão da maioria dos participantes.
Seleção de Voz
Usamos as 500 vozes públicas principais da plataforma para o experimento. Cada voz foi clonada no sistema do provedor terceirizado antecipadamente, garantindo que a mesma identidade de voz de referência estivesse disponível em ambos os lados. Os mapeamentos de ID de voz são mantidos em arquivos de mapa JSON dedicados que servem como a única fonte de verdade para a elegibilidade de roteamento.
Provedores e Modelos Testados
| Provedor | Modelo | Alvo de Rota |
|---|---|---|
| Fish Audio | S2 Pro (mais recente) | fish:s2-pro |
| Fish Audio | S1 (geração anterior) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
Cobertura de Avaliação e Suporte a Tags
Nem todos os provedores suportam o mesmo conjunto de recursos. O Fish Audio S2 Pro suporta tags de prosódia ricas (ex: [laughs], [sighs]) e tags de falante (<|speaker:N|>) para conteúdo com múltiplos interlocutores. Isso importa porque nosso tráfego de produção naturalmente inclui texto com tags.
- ElevenLabs V3 recebeu a avaliação mais completa — ele suporta tags arbitrárias após a normalização para o formato entre parênteses, portanto, foi elegível para virtualmente todas as solicitações, independentemente do conteúdo
- ElevenLabs 2.5 Flash e Multilingual V2 — enviamos apenas solicitações de texto simples para esses modelos (sem tags)
- Inworld — apenas texto simples e restrito ao formato de saída
mp3, limitando ainda mais seu tráfego elegível - MiniMax — aceitou tags de interjeição (
(laughs),(sighs), etc.), mas rejeitou outros tipos de tags. Devido aos resultados de preferência do usuário consistentemente baixos, o experimento foi encerrado precocemente para evitar degradar ainda mais a experiência do usuário
O sistema de roteamento avalia cada provedor alternativo em relação aos recursos da solicitação atual (idioma, tags, formato, vozes de multi-referência). Apenas as alternativas suportadas tornam-se candidatos elegíveis, e uma é selecionada via escolha aleatória ponderada. Se a única alternativa elegível for uma comparação Fish-vs-Fish (S1 vs S2 Pro), a probabilidade de amostragem efetiva é reduzida para 1/10 da taxa base para priorizar a coleta de dados entre provedores.
O Que Isso Nos Custou
Esses experimentos não são gratuitos. APIs de TTS de terceiros são caras em escala:
- ElevenLabs: $1.500+ gastos em chamadas de API
- MiniMax: $330 gastos (encerrado precocemente devido ao mau desempenho)
- Inworld: $170 gastos

Metodologia Estatística
Modelo Bradley-Terry
As taxas de vitória brutas podem ser enganosas quando diferentes modelos enfrentam oponentes diferentes em frequências diferentes. O modelo Bradley-Terry resolve isso calculando uma pontuação de força global a partir de dados de comparação pareada. Ele estima iterativamente o parâmetro de "força" latente de cada modelo, de modo que a probabilidade de vitória prevista entre quaisquer dois modelos corresponda aos dados observados.
Para dois modelos e com pontuações BT e :
Nossa implementação executa até 500 iterações com tolerância de convergência de , normalizando as pontuações usando a média geométrica em cada etapa.
Intervalos de Confiança
Relatamos intervalos de confiança bootstrap de 95% calculados a partir de 200 reamostragens dos dados de pares de preferência. Cada reamostragem extrai pares com reposição dos pares originais e executa novamente o cálculo BT completo. Os percentis 2,5 e 97,5 das pontuações bootstrap formam os limites do IC.
Para taxas de vitória por backend, usamos intervalos de pontuação de Wilson, que fornecem melhor cobertura do que os intervalos de aproximação normal em taxas de vitória extremas.
Resultados por Idioma
Idiomas de Alfabeto Latino (Inglês, Espanhol, Francês, Alemão, ...)
Os idiomas de alfabeto latino representam o maior segmento com 4.173 pares de preferência.
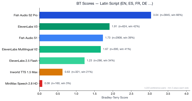
O Fish S2 Pro lidera com 3,05. Notavelmente, o ElevenLabs V3 (1,90) supera ligeiramente o Fish S1 (1,72) nesta categoria — o único grupo de idiomas onde algum concorrente ultrapassou nosso modelo anterior. O ElevenLabs Multilingual V2 também teve um bom desempenho com 1,70, logo atrás do S1.
Isso faz sentido: a ElevenLabs historicamente se concentrou no inglês e em idiomas europeus, e seu modelo V3 é forte nesse domínio. Ainda assim, o Fish S2 Pro mantém uma vantagem de 1,6x sobre o ElevenLabs V3.
Chinês
O chinês possui 329 pares de preferência e mostra a dominância mais dramática da Fish Audio.
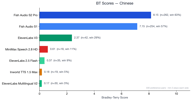
Ambos os modelos Fish Audio (S2 Pro em 8,11, S1 em 7,11) superam massivamente todos os concorrentes. O ElevenLabs V3 marca 2,36 — respeitável, mas muito atrás. Todos os outros concorrentes pontuaram abaixo de 1,0.
Japonês
O japonês possui 354 pares de preferência.
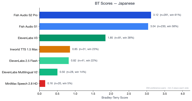
Fish S2 Pro (3,12) e Fish S1 (3,02) estão muito próximos, ambos muito à frente do ElevenLabs V3 (1,88). A lacuna entre os modelos Fish e os concorrentes é maior nos idiomas CJK (Chinês, Japonês e Coreano).
Resumo entre Idiomas
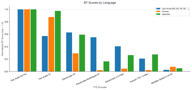
O Fish Audio S2 Pro ocupa o 1º lugar em todas as categorias de idiomas. A lacuna competitiva varia:
- Alfabeto latino: Os concorrentes estão mais próximos, o ElevenLabs V3 é genuinamente competitivo (pontuação relativa 0,62)
- Chinês: A dominância da Fish Audio é esmagadora, os concorrentes mal aparecem
- Japonês: Semelhante ao chinês — os modelos Fish estão muito à frente
Limitações
Usuários de API Excluídos
Para garantir a estabilidade da plataforma, os usuários de API não foram incluídos no experimento. A taxa de amostragem de 10% aplica-se apenas aos usuários da plataforma web. Isso significa que nossos resultados refletem padrões de uso da plataforma web, que podem diferir de cargas de trabalho de produção pesadas em API.
Suporte a Tags Cria uma Cobertura Desigual
Como os provedores terceirizados possuem suportes a tags variados, eles receberam subconjuntos diferentes de tráfego:
- O ElevenLabs V3 foi elegível para quase todas as solicitações (suporta tags)
- O ElevenLabs Flash/Multilingual recebeu apenas solicitações sem tags
- O Inworld recebeu apenas solicitações sem tags e em formato mp3
Isso significa que o campo competitivo não é perfeitamente nivelado. Os resultados do ElevenLabs V3 são os mais diretamente comparáveis aos da Fish Audio, pois ele recebeu a amostra de tráfego mais representativa. Outros modelos foram avaliados em um subconjunto que tende a solicitações mais simples de texto simples — o que, indiscutivelmente, deveria favorecê-los.
Resultados da MiniMax Podem Ser Não Confiáveis
O MiniMax Speech 2.8 HD obteve uma pontuação extraordinariamente baixa (BT 0,12, taxa de vitória de 5% — mesmo contra o Inworld). Suspeitamos que nossa integração com a API MiniMax possa não ser ideal. Após ouvir várias amostras geradas pela MiniMax, não conseguimos identificar um problema técnico específico — o áudio era inteligível, mas apresentava prosódia e naturalidade visivelmente piores em comparação com todos os outros provedores. Ampliamos a elegibilidade de roteamento da MiniMax no meio do experimento para aumentar o tamanho da amostra, mas o desempenho não melhorou. O experimento foi encerrado precocemente após acumular US$ 330 em custos de API sem sinais de resultados competitivos.
Se a MiniMax acreditar que esses resultados não refletem a verdadeira capacidade de seu modelo, aceitamos uma revisão colaborativa de nossa integração.
Restrições de Mapeamento de Voz
Apenas vozes com clones bem-sucedidos na plataforma de terceiros podem ser roteadas. Se um clone de voz falhasse, essa voz era excluída do pool elegível daquele provedor. Isso significa que cada provedor foi testado em um subconjunto ligeiramente diferente (embora amplamente sobreposto) das 500 vozes principais.
Possível Viés de Familiaridade com a Plataforma
Embora tenhamos amostrado cerca de 70% de novos usuários, os 30% restantes de usuários recorrentes podem ter desenvolvido preferências alinhadas com as características de áudio da Fish Audio. Acreditamos que esse efeito seja pequeno, dada a composição majoritária de novos usuários, mas não pode ser totalmente descartado.
Conclusão
Acreditamos que esta é uma das avaliações públicas mais rigorosas de qualidade de TTS já realizadas:
- Usuários reais, não anotadores pagos
- Comparação cega — os usuários nunca sabem qual provedor gerou qual áudio
- Sinal comportamental (download) em vez de avaliações subjetivas
- Tráfego de produção com complexidade de texto do mundo real, incluindo conteúdo de formato longo, tags de prosódia e texto multilíngue
- 5.000+ pares de preferência em vários idiomas, coletados ao longo de 10 dias
- $2.000+ gastos apenas em chamadas de API de terceiros
Os resultados são claros: O Fish Audio S2 Pro é o modelo de TTS preferido em todos os idiomas testados, com vantagens particularmente fortes em chinês e japonês. Até mesmo nosso modelo S1 de geração anterior supera todos os concorrentes no agregado.
Esses resultados validam ainda mais nosso roteiro para modelagem ponta a ponta e RLHF (Aprendizado por Reforço com Feedback Humano). Estamos comprometidos com a transparência. A metodologia, a lógica de roteamento e o código de análise fazem parte da infraestrutura da nossa plataforma. Convidamos a comunidade de TTS a examinar nossa abordagem e sugerir melhorias para futuras avaliações.
Esta avaliação foi conduzida pela equipe da Fish Audio de 26 de março a 5 de abril de 2026. Para dúvidas ou para discutir a metodologia, entre em contato em fish.audio.








