Fish Audio Abre o Código do S2: Controle de Granularidade Fina com Streaming de Produção
O S2 Pro está disponível no Fish Audio App e seu código aberto está disponível através do repositório GitHub do projeto e do HuggingFace.
A Fish Audio abriu o código do S2, um modelo de texto para fala que suporta controle inline de granularidade fina de prosódia e emoção usando tags de linguagem natural como [laugh], [whispers] e [super happy]. Treinado em mais de 10 milhões de horas de áudio em aproximadamente 50 idiomas, o sistema combina alinhamento por aprendizagem por reforço com uma arquitetura autorregressiva dupla. O lançamento inclui pesos do modelo, código para ajuste fino e um motor de inferência de streaming baseado em SGLang.
Controle Inline de Granularidade Fina via Linguagem Natural
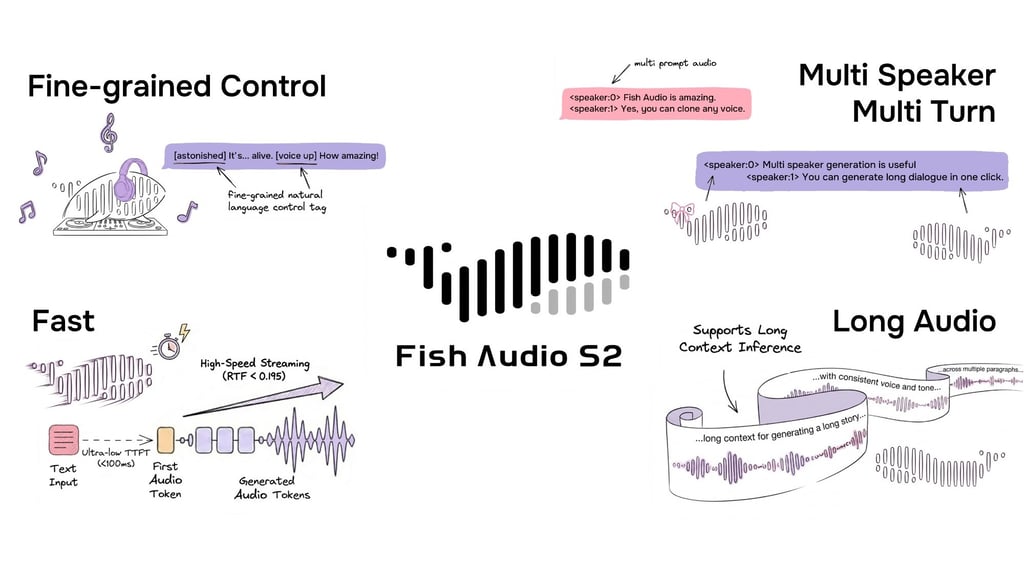
O S2 permite controle inline sobre a geração de fala ao incorporar instruções de linguagem natural diretamente em posições específicas de palavras ou frases dentro do texto. Em vez de depender de um conjunto fixo de tags predefinidas, o S2 aceita descrições textuais de forma livre — como [whisper in small voice], [professional broadcast tone] ou [pitch up] — permitindo controle de expressão ilimitado ao nível da palavra.
No Teste de Turing de Áudio, o S2 atinge uma média posterior de 0,515 com reescrita de instruções, em comparação com 0,417 para Seed-TTS e 0,387 para MiniMax-Speech. No EmergentTTS-Eval, alcança uma taxa de vitória geral de 81,88% contra uma linha de base gpt-4o-mini-tts — a mais alta entre todos os modelos avaliados, incluindo sistemas de código fechado do Google e OpenAI.
 Exemplo do formato de entrada do S2 mostrando um diálogo multi-falante com tags inline de linguagem natural de forma livre para controle de granularidade fina.
Exemplo do formato de entrada do S2 mostrando um diálogo multi-falante com tags inline de linguagem natural de forma livre para controle de granularidade fina.
Uma Receita Unificada: Curadoria de Dados e Recompensas RL dos Mesmos Modelos
Uma decisão arquitetônica central no S2 é que os mesmos modelos usados para filtrar e anotar dados de treinamento são reutilizados diretamente como modelos de recompensa durante a aprendizagem por reforço (RL):
- O modelo de qualidade de fala pontua o áudio em dimensões como SNR, consistência do falante e inteligibilidade durante a filtragem de dados — servindo então como a recompensa de preferência acústica durante a RL.
- O modelo ASR de transcrição rica (pré-treinado a partir do Qwen3-Omni-30B-A3B) gera transcrições aumentadas por legendas com anotações paralinguísticas inline durante a curadoria de dados — fornecendo então a recompensa de inteligibilidade e seguimento de instruções ao re-transcrever o áudio gerado e compará-lo com o prompt original.
Este design de propósito duplo elimina a incompatibilidade de distribuição entre os dados de pré-treinamento e os objetivos de pós-treinamento por construção — um problema que permanece sem solução em outros sistemas de TTS que treinam modelos de recompensa separadamente de seus pipelines de dados.
Por Dentro do Modelo: Arquitetura Dual-AR
O S2 baseia-se em um transformer apenas de decodificador combinado com um codec de áudio baseado em RVQ (10 codebooks, taxa de quadros de ~21 Hz). Achatar todos os codebooks ao longo do tempo causaria uma explosão de 10x no comprimento da sequência. O S2 aborda isso com uma arquitetura Autorregressiva Dupla (Dual-AR):
- AR Lento opera ao longo do eixo do tempo e prevê o codebook semântico primário.
- AR Rápido gera os 9 codebooks residuais restantes em cada etapa de tempo, reconstruindo detalhes acústicos de granularidade fina.
Este design assimétrico — 4B de parâmetros ao longo do eixo do tempo, 400M de parâmetros ao longo do eixo da profundidade — mantém a inferência eficiente enquanto preserva a fidelidade do áudio.
Alinhamento por Aprendizagem por Reforço para Fala
Para o pós-treinamento, o S2 utiliza o Group Relative Policy Optimization (GRPO), escolhido para evitar a sobrecarga de memória de modelos de valor estilo PPO em contextos de áudio longos. O sinal de recompensa combina múltiplas dimensões, incluindo:
- Precisão semântica e adesão a instruções
- Pontuação de preferência acústica
- Similaridade de timbre
Resultados de Referência
O S2 alcança resultados de liderança em vários benchmarks públicos:
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chinês) | 0,54% (melhor geral) |
| Seed-TTS Eval — WER (Inglês) | 0,99% (melhor geral) |
| Teste de Turing de Áudio (com instrução) | 0,515 média posterior |
| EmergentTTS-Eval — Taxa de Vitória | 81,88% (mais alta no geral) |
| Fish Instruction Benchmark — TAR | 93,3% |
| Fish Instruction Benchmark — Qualidade | 4,51 / 5,0 |
| Multilíngue (MiniMax Testset) — Melhor WER | 11 de 24 idiomas |
| Multilíngue (MiniMax Testset) — Melhor SIM | 17 de 24 idiomas |
No Seed-TTS Eval, o S2 alcança o menor WER entre todos os modelos avaliados, incluindo sistemas de código fechado: Qwen3-TTS (0,77/1,24), MiniMax Speech-02 (0,99/1,90), Seed-TTS (1,12/2,25). No Teste de Turing de Áudio, 0,515 supera o Seed-TTS (0,417) em 24% e o MiniMax-Speech (0,387) em 33%. No EmergentTTS-Eval, o S2 alcança resultados particularmente fortes em paralinguística (taxa de vitória de 91,61%), perguntas (84,41%) e complexidade sintática (83,39%).
Para uma visão mais ampla de como diferentes soluções se avaliam em relação ao controle de emoção, latência e suporte multilíngue, você pode consultar esta comparação independente de ferramentas de voz e áudio de IA.
Streaming de Produção via SGLang
Como a arquitetura Dual-AR do S2 é estruturalmente isomórfica aos LLMs autorregressivos padrão, ela pode herdar diretamente todas as otimizações de serviço nativas de LLM do SGLang com modificações mínimas — incluindo loteamento contínuo (continuous batching), paged KV cache, replay de grafo CUDA e prefix caching baseado em RadixAttention.
Para clonagem de voz, o S2 coloca tokens de áudio de referência no prompt do sistema. O RadixAttention do SGLang armazena automaticamente esses estados KV em cache, atingindo uma taxa média de acerto de prefix-cache de 86,4% (mais de 90% no pico) quando a mesma voz é reutilizada em várias solicitações — tornando a sobrecarga de prefill do áudio de referência quase insignificante.
Em uma única GPU NVIDIA H200:
- Fator de Tempo Real (RTF): 0,195
- Tempo para o primeiro áudio: aproximadamente 100 ms
- Taxa de transferência: 3.000+ tokens acústicos/s mantendo o RTF abaixo de 0,5
Para um passo a passo de como rodar o S2 em GPUs H100/H200 na nuvem, veja o guia de implantação de TTS de código aberto da Spheron.
Por Que Este Lançamento é Importante
O S2 é lançado não apenas como um checkpoint de modelo, mas como um sistema completo: pesos do modelo, código de ajuste fino e uma pilha de inferência pronta para produção.
Duas escolhas de design se destacam. Primeiro, o pipeline unificado de dados e recompensa elimina um problema estrutural — a incompatibilidade de distribuição entre o pré-treinamento e o RL — que outros sistemas de TTS não abordaram no nível arquitetônico. Segundo, o isomorfismo estrutural entre a arquitetura Dual-AR e os LLMs padrão significa que o S2 pode aproveitar todo o ecossistema de otimizações de serviço de LLM, em vez de exigir uma infraestrutura de inferência personalizada.
O S2 está disponível através do repositório GitHub do projeto, SGLang-Omni, HuggingFace e demonstração interativa em fish.audio.
Perguntas Frequentes
Como funciona a geração de diálogo com vários falantes?
Isso está disponível via API?
Quais tags de áudio são suportadas?
Quais idiomas ele suporta?








