Wir haben unser TTS im Blindtest gegen alle großen Wettbewerber getestet. Hier sind die Ergebnisse.

Wir haben unser TTS im Blindtest gegen alle großen Wettbewerber getestet. Hier sind die Ergebnisse.
Fish Audio führte einen 10-tägigen blinden A/B-Test mit echtem Produktiv-Traffic durch und ließ Fish Audio S2 Pro und S1 gegen ElevenLabs, Inworld und MiniMax antreten. Über 5.000 Präferenzpaare wurden von echten Nutzern gesammelt, die keine Ahnung hatten, welcher Anbieter welches Audio generiert hat.
TLDR: Ergebnisse
Fish Audio S2 Pro belegte den Gesamtrang 1 mit einem Bradley-Terry-Score von 3,07, was fast dem 1,7-fachen des nächstbesten Modells entspricht. Unser älteres Modell, Fish Audio S1 (BT 1,86), übertraf im Aggregat ebenfalls jeden Drittanbieter.
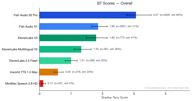
| Rang | Modell | BT-Score | Gewinnrate | Stichproben |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3,07 | 65,7 % | 4.573 |
| 2 | Fish Audio S1 | 1,86 | 41,0 % | 3.560 |
| 3 | ElevenLabs V3 | 1,80 | 40,6 % | 766 |
| 4 | ElevenLabs Multilingual V2 | 1,35 | 36,2 % | 359 |
| 5 | ElevenLabs 2.5 Flash | 1,00 | 29,8 % | 364 |
| 6 | Inworld TTS 1.5 Max | 0,59 | 20,1 % | 373 |
| 7 | MiniMax Speech 2.8 HD | 0,12 | 5,0 % | 201 |
Wichtige Head-to-Head-Duelle:
- Fish S2 Pro schlägt ElevenLabs V3 60 % zu 40 % (581 Paare)
- Fish S2 Pro schlägt Inworld 80 % zu 20 % (261 Paare)
- Fish S2 Pro schlägt MiniMax 95 % zu 5 % (142 Paare)
- Fish S1 schlägt ElevenLabs V3 64 % zu 36 % (150 Paare)
Warum wir das gemacht haben
Das Problem mit traditionellen Metriken
MOS (Mean Opinion Score) bleibt der De-facto-Standard für die TTS-Evaluierung, ist jedoch tiefgreifend fehlerhaft. Die Testbedingungen werden selten offengelegt – Stichprobenlänge, Demografie der Hörer, Wiedergabeumgebung und Bewertungsanweisungen variieren von Studie zu Studie, was Vergleiche zwischen verschiedenen Publikationen bedeutungslos macht. Inzwischen können WER/CER (Wort-/Zeichenfehlerrate) als Optimierungsziel kontraproduktiv sein: Ein zu starkes Senken der WER zwingt das Modell oft in eine hyperartikulierte, roboterhafte Sprache, die Natürlichkeit und Prosodie zugunsten der Verständlichkeit opfert. Ein Modell, das gelegentlich wie ein echter Mensch nuschelt, kann tatsächlich besser klingen als eines, das jede Silbe perfekt artikuliert.
Das Problem mit bestehenden Ranglisten
Öffentliche Ranglisten wie TTS-Arena-V2 und Artificial Analysis bewerten Modelle anhand kurzer, einfacher Sätze – typischerweise eine einzelne Dialogzeile oder eine kurze Erzählung. Dies wird der Komplexität der realen TTS-Nutzung nicht gerecht: Long-Form-Inhalte, Dialoge mit mehreren Sprechern, expressive Prosodie-Tags und mehrsprachige Texte.
Abgesehen von der Methodik gibt es Bedenken hinsichtlich der Integrität. TTS-Arena-V2 hatte bekannte Probleme mit Audio-Header-Leaks, bei denen Metadaten in der Audiodatei die Identität des Anbieters preisgeben konnten – was das Prinzip der Blindevaluierung bricht. Wir sind uns auch bewusst, dass Leaderboard-Manipulation weit verbreitet ist: Anbieter optimieren gezielt für Benchmark-Sätze, reichen handverlesene Modell-Checkpoints ein oder blähen Rankings durch koordinierte Abstimmungen auf. Diese Ranglisten sind eher zu Marketinginstrumenten als zu zuverlässigen Qualitätssignalen geworden.
Was wir eigentlich wollten
Wir brauchten ein zuverlässiges internes Belohnungssignal – ein Ground-Truth-Maßstab dafür, welche TTS-Ausgabe echte Nutzer tatsächlich bevorzugen, dem wir bei Modellentwicklungsentscheidungen vertrauen konnten. Keine Zahl aus einer wissenschaftlichen Arbeit, kein Rang in einer manipulierbaren Rangliste, sondern ein kontinuierlicher Strom ehrlicher Präferenzdaten von Nutzern, die echte Entscheidungen treffen.
Deshalb haben wir eine Pipeline zur Blindevaluierung direkt in unsere Produktionsplattform integriert.
Versuchsaufbau
Blinder Paarvergleich
Das Studio von Fish Audio präsentiert Nutzern für jede TTS-Aufgabe zwei Audioversionen nebeneinander. Jede Version hat unabhängig eine Chance von 10 %, im Hintergrund unbemerkt an einen Konkurrenzanbieter statt an das Standard-Backend von Fish Audio geleitet zu werden. Gleicher Text, gleiche Referenzstimme, gleiche Benutzeroberfläche – der Nutzer hat keine Ahnung, welcher Anbieter welches Audio generiert hat.
Das Experiment lief über 10 Tage (26. März – 5. April 2026) und sammelte über 71.000 Paargruppen, von denen 5.098 Vergleiche zwischen verschiedenen Anbietern enthielten, die unsere Qualitätskriterien erfüllten.
Was als „Sieg“ zählt
Wir verwenden ein striktes verhaltensbasiertes Signal, keine subjektive Bewertung:
- Der Nutzer muss beide Versionen mindestens je 2 Mal abspielen – um zu bestätigen, dass er beide tatsächlich verglichen hat.
- Genau eine Version wird heruntergeladen – das ist der Gewinner.
Dieses „Anhören-dann-Herunterladen“-Signal ist weitaus zuverlässiger als Sternebewertungen oder Umfragen mit erzwungener Auswahl. Die Nutzer treffen echte Entscheidungen über Audioinhalte, die sie tatsächlich verwenden werden.
Nutzerzusammensetzung
Das Experiment umfasste etwa 70 % neue Nutzer und 30 % wiederkehrende Nutzer. Diese Zusammensetzung kann eine leichte Tendenz zugunsten von Fish Audio einführen (wiederkehrende Nutzer sind bereits mit unserer Plattform vertraut), stellt aber auch sicher, dass wir echte Präferenzen basierend auf dem ersten Eindruck der Mehrheit der Teilnehmer erfassen.
Stimmauswahl
Wir haben die Top 500 der öffentlichen Stimmen der Plattform für das Experiment verwendet. Jede Stimme wurde zuvor in das System des Drittanbieters geklont, um sicherzustellen, dass auf beiden Seiten dieselbe Identität der Referenzstimme verfügbar war. Die Zuordnungen der Sprach-IDs werden in speziellen JSON-Dateien verwaltet, die als zentrale Referenzquelle (Single Source of Truth) für die Routing-Berechtigung dienen.
Getestete Anbieter und Modelle
| Anbieter | Modell | Routing-Ziel |
|---|---|---|
| Fish Audio | S2 Pro (aktuell) | fish:s2-pro |
| Fish Audio | S1 (vorherige Gen.) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
Abdeckung der Evaluierung und Tag-Unterstützung
Nicht alle Anbieter unterstützen den gleichen Funktionsumfang. Fish Audio S2 Pro unterstützt reichhaltige Prosodie-Tags (z. B. [laughs], [sighs]) und Sprecher-Tags (<|speaker:N|>) für Inhalte mit mehreren Sprechern. Dies ist wichtig, da unser Produktions-Traffic natürlicherweise getaggte Texte enthält.
- ElevenLabs V3 erhielt die vollständigste Evaluierung – es unterstützt beliebige Tags nach einer Normalisierung in Klammerform und war somit für praktisch alle Anfragen unabhängig vom Inhalt berechtigt.
- ElevenLabs 2.5 Flash und Multilingual V2 – an diese Modelle haben wir nur reine Textanfragen gesendet (keine Tags).
- Inworld – nur reiner Text und beschränkt auf das
mp3-Ausgabeformat, was den berechtigten Traffic weiter einschränkte. - MiniMax – akzeptierte Interjektions-Tags (
(laughs),(sighs), etc.), lehnte aber andere Tag-Typen ab. Aufgrund konsistent schlechter Ergebnisse bei den Nutzerpräferenzen wurde das Experiment vorzeitig abgebrochen, um die Nutzererfahrung nicht weiter zu beeinträchtigen.
Das Routing-System bewertet jeden alternativen Anbieter anhand der Merkmale der aktuellen Anfrage (Sprache, Tags, Format, Stimmen mit mehreren Referenzen). Nur unterstützte Alternativen kommen als Kandidaten in Frage, und eine wird per gewichteter Zufallsauswahl ausgewählt. Wenn die einzige berechtigte Alternative ein Vergleich zwischen Fish-Modellen ist (S1 vs. S2 Pro), wird die effektive Stichprobenwahrscheinlichkeit auf 1/10 der Basisrate reduziert, um die Datenerhebung zwischen verschiedenen Anbietern zu priorisieren.
Was uns das gekostet hat
Diese Experimente sind nicht kostenlos. Drittanbieter-TTS-APIs sind bei großen Volumina teuer:
- ElevenLabs: Über 1.500 $ für API-Aufrufe ausgegeben
- MiniMax: 330 $ ausgegeben (vorzeitig abgebrochen wegen schlechter Leistung)
- Inworld: 170 $ ausgegeben

Statistische Methodik
Bradley-Terry-Modell
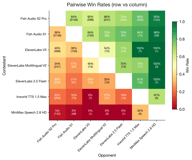
Rohe Gewinnraten können irreführend sein, wenn verschiedene Modelle in unterschiedlicher Häufigkeit gegen verschiedene Gegner antreten. Das Bradley-Terry-Modell löst dies, indem es aus paarweisen Vergleichsdaten einen globalen Stärkewert berechnet. Es schätzt iterativ den latente „Stärke“-Parameter jedes Modells so, dass die vorhergesagte Gewinnwahrscheinlichkeit zwischen zwei beliebigen Modellen mit den beobachteten Daten übereinstimmt.
Für zwei Modelle und mit BT-Scores und :
Unsere Implementierung läuft bis zu 500 Iterationen mit einer Konvergenztoleranz von und normalisiert die Scores in jedem Schritt unter Verwendung des geometrischen Mittels.
Konfidenzintervalle
Wir geben 95 % Bootstrap-Konfidenzintervalle an, die aus 200 Resamplings der Präferenzpaardaten berechnet wurden. Jedes Resampling zieht Paare mit Zurücklegen aus den ursprünglichen Paaren und führt die vollständige BT-Berechnung erneut aus. Das 2,5. und 97,5. Perzentil der gebootstrappten Scores bilden die CI-Grenzen.
Für die Gewinnraten pro Backend verwenden wir Wilson-Score-Intervalle, die bei extremen Gewinnraten eine bessere Abdeckung bieten als normale Approximationsintervalle.
Ergebnisse nach Sprache
Sprachen mit lateinischer Schrift (Englisch, Spanisch, Französisch, Deutsch, ...)
Sprachen mit lateinischer Schrift stellen mit 4.173 Präferenzpaaren das größte Segment dar.
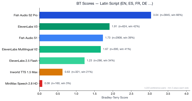
Fish S2 Pro führt mit 3,05. Bemerkenswerterweise übertrifft ElevenLabs V3 (1,90) Fish S1 (1,72) in dieser Kategorie leicht – die einzige Sprachgruppe, in der ein Wettbewerber unser älteres Modell knapp hinter sich lässt. ElevenLabs Multilingual V2 schneidet mit 1,70 ebenfalls gut ab, dicht hinter S1.
Das ist logisch: ElevenLabs hat sich historisch auf Englisch und europäische Sprachen konzentriert, und ihr V3-Modell ist in diesem Bereich stark. Dennoch behält Fish S2 Pro einen 1,6-fachen Vorteil gegenüber ElevenLabs V3.
Chinesisch
Chinesisch weist 329 Präferenzpaare auf und zeigt die deutlichste Dominanz von Fish Audio.
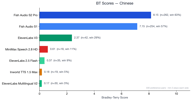
Beide Fish Audio-Modelle (S2 Pro mit 8,11, S1 mit 7,11) übertreffen alle Wettbewerber massiv. ElevenLabs V3 erreicht 2,36 – respektabel, aber weit abgeschlagen. Alle anderen Wettbewerber liegen unter 1,0.
Japanisch
Japanisch weist 354 Präferenzpaare auf.
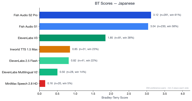
Fish S2 Pro (3,12) und Fish S1 (3,02) liegen sehr nah beieinander, beide weit vor ElevenLabs V3 (1,88). Der Abstand zwischen Fish-Modellen und Wettbewerbern ist bei CJK-Sprachen am größten.
Sprachübergreifende Zusammenfassung
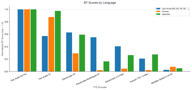
Fish Audio S2 Pro belegt in jeder Sprachkategorie den ersten Platz. Der Wettbewerbsvorteil variiert:
- Lateinische Schrift: Wettbewerber liegen am nächsten dran, ElevenLabs V3 ist wirklich konkurrenzfähig (relativer Score 0,62).
- Chinesisch: Die Dominanz von Fish Audio ist überwältigend, Wettbewerber spielen kaum eine Rolle.
- Japanisch: Ähnlich wie bei Chinesisch – Fish-Modelle sind weit voraus.
Einschränkungen
API-Nutzer ausgeschlossen
Um die Plattformstabilität zu gewährleisten, wurden API-Nutzer nicht in das Experiment einbezogen. Die 10 %-Stichprobenrate gilt nur für Nutzer der Web-Plattform. Dies bedeutet, dass unsere Ergebnisse die Nutzungsmuster der Web-Plattform widerspiegeln, die sich von API-intensiven Produktions-Workloads unterscheiden können.
Tag-Unterstützung schafft ungleiche Abdeckung
Da Drittanbieter unterschiedliche Tag-Unterstützung bieten, erhielten sie unterschiedliche Teilmengen des Traffics:
- ElevenLabs V3 war für fast alle Anfragen berechtigt (unterstützt Tags).
- ElevenLabs Flash/Multilingual erhielten nur tag-freie Anfragen.
- Inworld erhielt nur tag-freie Anfragen im mp3-Format.
Dies bedeutet, dass das Wettbewerbsfeld nicht vollkommen ausgeglichen ist. Die Ergebnisse von ElevenLabs V3 sind am ehesten mit denen von Fish Audio vergleichbar, da dieses Modell die repräsentativste Traffic-Stichprobe erhielt. Andere Modelle wurden anhand einer Teilmenge bewertet, die eher zu einfacheren, rein textbasierten Anfragen neigt – was sie theoretisch begünstigen sollte.
MiniMax-Ergebnisse könnten unzuverlässig sein
MiniMax Speech 2.8 HD schnitt außerordentlich schlecht ab (BT 0,12, 5 % Gewinnrate – sogar gegen Inworld). Wir vermuten, dass unsere MiniMax-API-Integration nicht optimal sein könnte. Nach dem Anhören mehrerer von MiniMax generierter Proben konnten wir kein spezifisches technisches Problem feststellen – das Audio war verständlich, wies aber im Vergleich zu allen anderen Anbietern eine spürbar schlechtere Prosodie und Natürlichkeit auf. Wir haben die Routing-Berechtigung für MiniMax während des Experiments ausgeweitet, um den Stichprobenumfang zu erhöhen, aber die Leistung verbesserte sich nicht. Das Experiment wurde vorzeitig abgebrochen, nachdem 330 $ an API-Kosten angefallen waren, ohne dass Anzeichen für wettbewerbsfähige Ergebnisse vorlagen.
Falls MiniMax der Ansicht ist, dass diese Ergebnisse nicht die tatsächlichen Fähigkeiten ihres Modells widerspiegeln, begrüßen wir eine gemeinsame Überprüfung unserer Integration.
Einschränkungen beim Voice-Mapping
Nur Stimmen, die erfolgreich auf der Drittanbieter-Plattform geklont werden konnten, konnten geroutet werden. Wenn ein Stimmenklon fehlschlug, wurde diese Stimme aus dem berechtigten Pool dieses Anbieters ausgeschlossen. Dies bedeutet, dass jeder Anbieter mit einer etwas anderen (wenn auch weitgehend überschneidenden) Teilmenge der Top 500 Stimmen getestet wurde.
Mögliche Voreingenommenheit durch Plattform-Vertrautheit
Während wir etwa 70 % neue Nutzer befragt haben, könnten die restlichen etwa 30 % wiederkehrenden Nutzer Präferenzen entwickelt haben, die auf die Audiocharakteristika von Fish Audio abgestimmt sind. Wir glauben, dass dieser Effekt angesichts der Zusammensetzung aus überwiegend neuen Nutzern gering ist, er kann jedoch nicht vollständig ausgeschlossen werden.
Fazit
Wir glauben, dass dies eine der strengsten öffentlichen Evaluierungen der TTS-Qualität ist, die jemals durchgeführt wurde:
- Echte Nutzer, keine bezahlten Annotatoren
- Blinder Vergleich – Nutzer wissen nie, welcher Anbieter welches Audio generiert hat
- Verhaltensbasiertes Signal (Download) statt subjektiver Bewertungen
- Produktiv-Traffic mit realer Textkomplexität, einschließlich Long-Form-Inhalten, Prosodie-Tags und mehrsprachigen Texten
- Über 5.000 Präferenzpaare in mehreren Sprachen, gesammelt über 10 Tage
- Über 2.000 $ allein für API-Aufrufe bei Drittanbietern ausgegeben
Die Ergebnisse sind eindeutig: Fish Audio S2 Pro ist das bevorzugte TTS-Modell in allen getesteten Sprachen, mit besonders starken Vorteilen in Chinesisch und Japanisch. Sogar unser S1-Modell der vorherigen Generation übertrifft im Aggregat jeden Wettbewerber.
Diese Ergebnisse bestätigen unsere Roadmap für End-to-End-Modellierung und RLHF (Reinforcement Learning from Human Feedback). Wir setzen auf Transparenz. Die Methodik, die Routing-Logik und der Analyse-Code sind Teil unserer Plattform-Infrastruktur. Wir laden die TTS-Community ein, unseren Ansatz kritisch zu prüfen und Verbesserungen für zukünftige Evaluierungen vorzuschlagen.
Diese Evaluierung wurde vom Fish Audio-Team vom 26. März bis zum 5. April 2026 durchgeführt. Für Fragen oder zur Diskussion der Methodik kontaktieren Sie uns unter fish.audio.









