Fish Audio veröffentlicht S2 als Open Source: Fein abgestufte Steuerung trifft auf produktionsreifes Streaming
S2 Pro ist in der Fish Audio App verfügbar, und sein Open-Source-Code ist über das GitHub-Repository des Projekts sowie HuggingFace zugänglich.
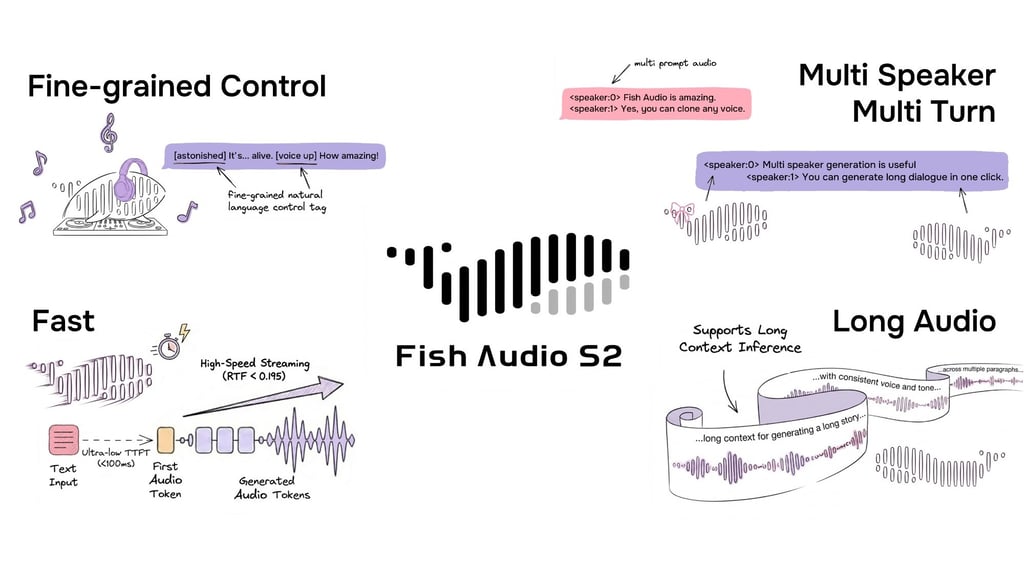
Fish Audio hat S2 als Open Source veröffentlicht, ein Text-to-Speech-Modell, das eine fein abgestufte Inline-Steuerung von Prosodie und Emotionen mittels natürlicher Sprach-Tags wie [laugh], [whispers] und [super happy] unterstützt. Das System wurde auf über 10 Millionen Stunden Audiomaterial in etwa 50 Sprachen trainiert und kombiniert Reinforcement Learning Alignment mit einer dual-autoregressiven Architektur. Die Veröffentlichung umfasst Modellgewichte, Code für das Fine-Tuning und eine SGLang-basierte Streaming-Inferenz-Engine.
Fein abgestufte Inline-Steuerung über natürliche Sprache
S2 ermöglicht die Inline-Steuerung der Sprachgenerierung, indem Anweisungen in natürlicher Sprache direkt an bestimmten Wort- oder Phrasenpositionen im Text eingebettet werden. Anstatt auf einen festen Satz vordefinierter Tags angewiesen zu sein, akzeptiert S2 freiformulierte Textbeschreibungen – wie [whisper in small voice], [professional broadcast tone] oder [pitch up] – was eine ergebnisoffene Ausdruckskontrolle auf Wortebene erlaubt.
Im Audio-Turing-Test erreicht S2 einen Posterior-Mittelwert von 0,515 mit Instruction-Rewriting, verglichen mit 0,417 für Seed-TTS und 0,387 für MiniMax-Speech. Auf EmergentTTS-Eval erzielt es eine Gesamt-Win-Rate von 81,88 % gegenüber einer gpt-4o-mini-tts Baseline – der höchste Wert unter allen evaluierten Modellen, einschließlich Closed-Source-Systemen von Google und OpenAI.
 Beispiel für das S2-Eingabeformat, das einen Dialog mit mehreren Sprechern und frei formulierten Inline-Tags in natürlicher Sprache für eine fein abgestufte Steuerung zeigt.
Beispiel für das S2-Eingabeformat, das einen Dialog mit mehreren Sprechern und frei formulierten Inline-Tags in natürlicher Sprache für eine fein abgestufte Steuerung zeigt.
Ein einheitliches Rezept: Datenkuratierung und RL-Belohnungen aus denselben Modellen
Eine zentrale architektonische Entscheidung bei S2 besteht darin, dass dieselben Modelle, die zum Filtern und Annotieren von Trainingsdaten verwendet werden, direkt als Reward-Modelle während des Reinforcement Learning wiederverwendet werden:
- Sprachqualitätsmodell bewertet Audio in Dimensionen wie SNR, Sprecherkonsistenz und Verständlichkeit während der Datenfilterung – und dient dann als akustische Präferenzbelohnung während des RL.
- Rich-Transcription-ASR-Modell (weiter vortrainiert auf Basis von Qwen3-Omni-30B-A3B) erzeugt mit Bildunterschriften ergänzte Transkripte mit paralinguistischen Inline-Annotationen während der Datenkuratierung – und liefert dann die Belohnung für Verständlichkeit und Befolgung von Anweisungen, indem generiertes Audio neu transkribiert und mit dem ursprünglichen Prompt verglichen wird.
Dieses Dual-Purpose-Design eliminiert konstruktionsbedingt die Diskrepanz in der Verteilung (Distribution Mismatch) zwischen Pre-Training-Daten und Post-Training-Zielen – ein Problem, das in anderen TTS-Systemen, die Reward-Modelle separat von ihren Daten-Pipelines trainieren, ungelöst bleibt.
Ein Blick ins Modell: Dual-AR-Architektur
S2 basiert auf einem Decoder-only Transformer kombiniert mit einem RVQ-basierten Audio-Codec (10 Codebooks, ~21 Hz Framerate). Das Abflachen aller Codebooks entlang der Zeitachse würde zu einer 10-fachen Explosion der Sequenzlänge führen. S2 löst dies mit einer dual-autoregressiven Architektur (Dual-AR):
- Slow AR arbeitet entlang der Zeitachse und sagt das primäre semantische Codebook voraus.
- Fast AR generiert bei jedem Zeitschritt die verbleibenden 9 Residual-Codebooks und rekonstruiert so fein abgestufte akustische Details.
Dieses asymmetrische Design – 4 Mrd. Parameter entlang der Zeitachse, 400 Mio. Parameter entlang der Tiefenachse – hält die Inferenz effizient und bewahrt gleichzeitig die Audiotreue.
Reinforcement Learning Alignment für Sprache
Für das Post-Training verwendet S2 die Group Relative Policy Optimization (GRPO), die gewählt wurde, um den Speicher-Overhead von PPO-ähnlichen Value-Modellen in langen Audiokontexten zu vermeiden. Das Belohnungssignal kombiniert mehrere Dimensionen, darunter:
- Semantische Genauigkeit und Befolgung von Anweisungen
- Akustische Präferenzbewertung
- Timbre-Ähnlichkeit
Benchmark-Ergebnisse
S2 erzielt führende Ergebnisse über mehrere öffentliche Benchmarks hinweg:
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chinesisch) | 0,54 % (insgesamt am besten) |
| Seed-TTS Eval — WER (Englisch) | 0,99 % (insgesamt am besten) |
| Audio Turing Test (mit Anweisung) | 0,515 Posterior-Mittelwert |
| EmergentTTS-Eval — Win-Rate | 81,88 % (insgesamt am höchsten) |
| Fish Instruction Benchmark — TAR | 93,3 % |
| Fish Instruction Benchmark — Qualität | 4,51 / 5,0 |
| Multilingual (MiniMax-Testset) — Beste WER | 11 von 24 Sprachen |
| Multilingual (MiniMax-Testset) — Beste SIM | 17 von 24 Sprachen |
Bei Seed-TTS Eval erreicht S2 die niedrigste WER unter allen evaluierten Modellen, einschließlich Closed-Source-Systemen: Qwen3-TTS (0,77/1,24), MiniMax Speech-02 (0,99/1,90), Seed-TTS (1,12/2,25). Im Audio-Turing-Test übertrifft 0,515 Seed-TTS (0,417) um 24 % und MiniMax-Speech (0,387) um 33 %. Bei EmergentTTS-Eval erzielt S2 besonders starke Ergebnisse in den Bereichen Paralinguistik (91,61 % Win-Rate), Fragen (84,41 %) und syntaktische Komplexität (83,39 %).
Für einen umfassenderen Blick darauf, wie verschiedene Lösungen in Bezug auf Emotionssteuerung, Latenz und mehrsprachige Unterstützung abschneiden, können Sie diesen unabhängigen Vergleich von KI-Sprach- und Audiotools heranziehen.
Produktionsreifes Streaming via SGLang
Da die Dual-AR-Architektur von S2 strukturell isomorph zu standardmäßigen autoregressiven LLMs ist, kann sie direkt alle LLM-nativen Serving-Optimierungen von SGLang mit minimalen Änderungen übernehmen – einschließlich Continuous Batching, Paged KV Cache, CUDA Graph Replay und RadixAttention-basiertes Prefix Caching.
Für das Voice Cloning platziert S2 Referenz-Audio-Token im System-Prompt. Die RadixAttention von SGLang cached diese KV-Zustände automatisch und erreicht eine durchschnittliche Prefix-Cache-Trefferquote von 86,4 % (über 90 % in der Spitze), wenn dieselbe Stimme über mehrere Anfragen hinweg wiederverwendet wird – was den Prefill-Overhead für Referenz-Audio nahezu vernachlässigbar macht.
Auf einer einzelnen NVIDIA H200 GPU:
- Echtzeitfaktor (RTF): 0,195
- Zeit bis zum ersten Audio: ca. 100 ms
- Durchsatz: 3.000+ akustische Token/s bei Beibehaltung eines RTF unter 0,5
Eine schrittweise Anleitung zur Ausführung von S2 auf Cloud-H100/H200-GPUs finden Sie im Spheron Open-Source TTS Deployment Guide.
Warum diese Veröffentlichung wichtig ist
S2 wird nicht nur als Modell-Checkpoint veröffentlicht, sondern als komplettes System: Modellgewichte, Fine-Tuning-Code und ein produktionsreifer Inferenz-Stack.
Zwei Design-Entscheidungen stechen hervor. Erstens eliminiert die vereinheitlichte Daten- und Belohnungs-Pipeline ein strukturelles Problem – die Diskrepanz in der Verteilung zwischen Pre-Training und RL –, das andere TTS-Systeme auf architektonischer Ebene noch nicht angegangen sind. Zweitens bedeutet die strukturelle Isomorphie zwischen der Dual-AR-Architektur und Standard-LLMs, dass S2 das gesamte Ökosystem der LLM-Serving-Optimierungen nutzen kann, anstatt eine eigene Inferenz-Infrastruktur zu erfordern.
S2 ist über das GitHub-Repository des Projekts, SGLang-Omni, HuggingFace und als interaktive Demo auf fish.audio verfügbar.
Häufig Gestellte Fragen
Wie funktioniert die Dialoggenerierung mit mehreren Sprechern?
Ist dies über eine API verfügbar?
Welche Audio-Tags werden unterstützt?
Welche Sprachen werden unterstützt?








