Fish Audio veröffentlicht S2 als Open-Source: Feingranulare Kontrolle trifft auf produktionsreifes Streaming
9. März 2026
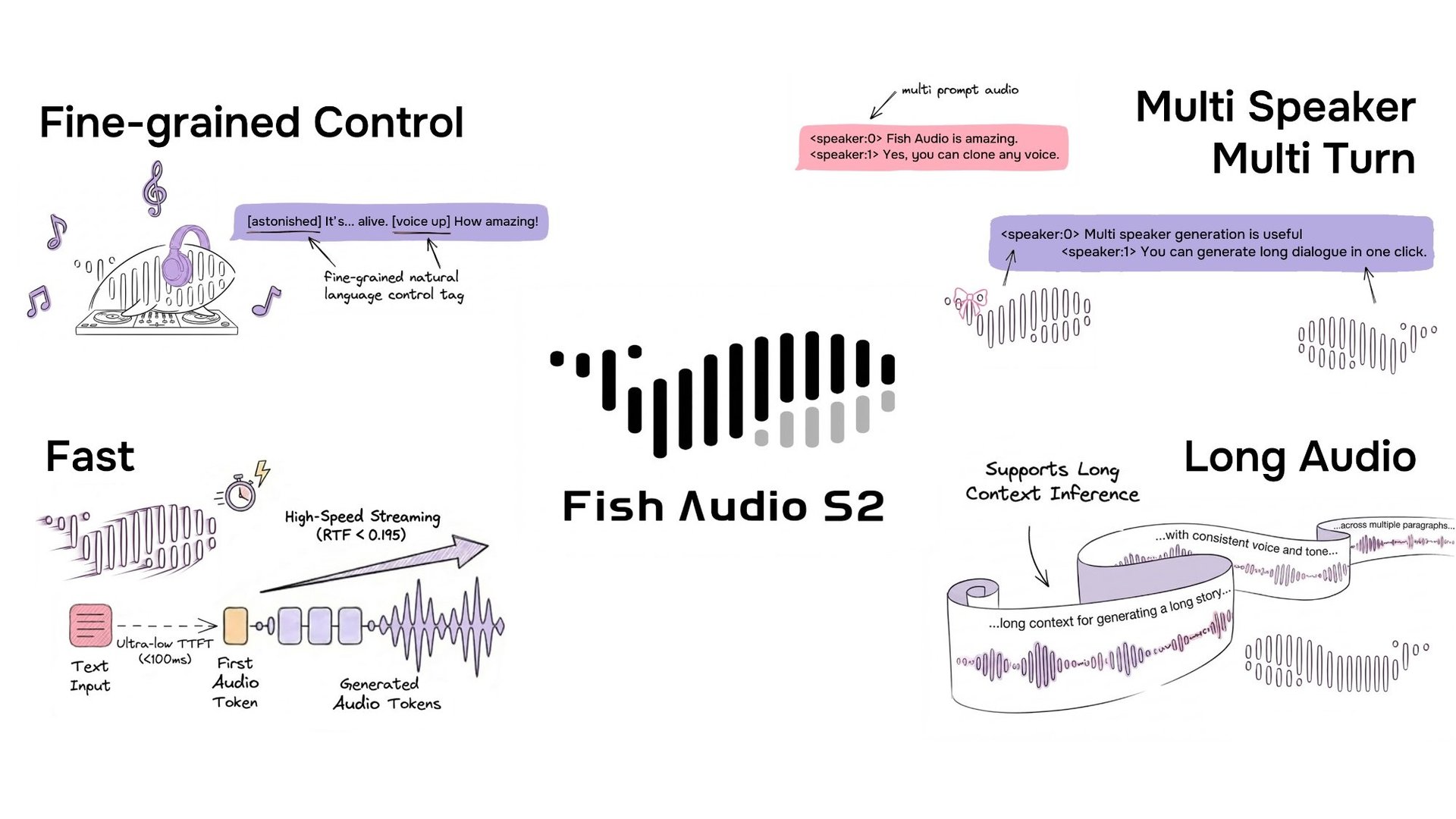
S2 Open Source ist über das GitHub-Repository des Projekts und HuggingFace verfügbar.
Fish Audio hat S2 als Open Source veröffentlicht, ein Text-to-Speech-Modell, das eine feingranulare Inline-Steuerung von Prosodie und Emotionen durch natürlichsprachliche Tags wie [laugh], [whispers] und [super happy] unterstützt. Das System wurde mit über 10 Millionen Stunden Audiomaterial in etwa 50 Sprachen trainiert und kombiniert Reinforcement Learning Alignment mit einer dual-autoregressiven Architektur. Die Veröffentlichung umfasst Modellgewichte, Fine-Tuning-Code und eine SGLang-basierte Streaming-Inference-Engine.
Feingranulare Inline-Steuerung via natürlicher Sprache
S2 ermöglicht eine Inline-Steuerung der Spracherzeugung, indem natürlichsprachliche Anweisungen direkt an bestimmten Wort- oder Phrasenpositionen im Text eingebettet werden. Anstatt auf einen festen Satz vordefinierter Tags angewiesen zu sein, akzeptiert S2 freiformulierte Textbeschreibungen – wie [whisper in small voice], [professional broadcast tone] oder [pitch up] – was eine ergebnisoffene Steuerung des Ausdrucks auf Wortebene ermöglicht.
Beim Audio Turing Test erreicht S2 einen Posterior-Mittelwert von 0,515 mit Instruction Rewriting, verglichen mit 0,417 für Seed-TTS und 0,387 für MiniMax-Speech. Auf EmergentTTS-Eval erreicht es eine Gesamt-Win-Rate von 81,88 % gegenüber einer gpt-4o-mini-tts-Baseline – der höchste Wert unter allen evaluierten Modellen, einschließlich Closed-Source-Systemen von Google und OpenAI.
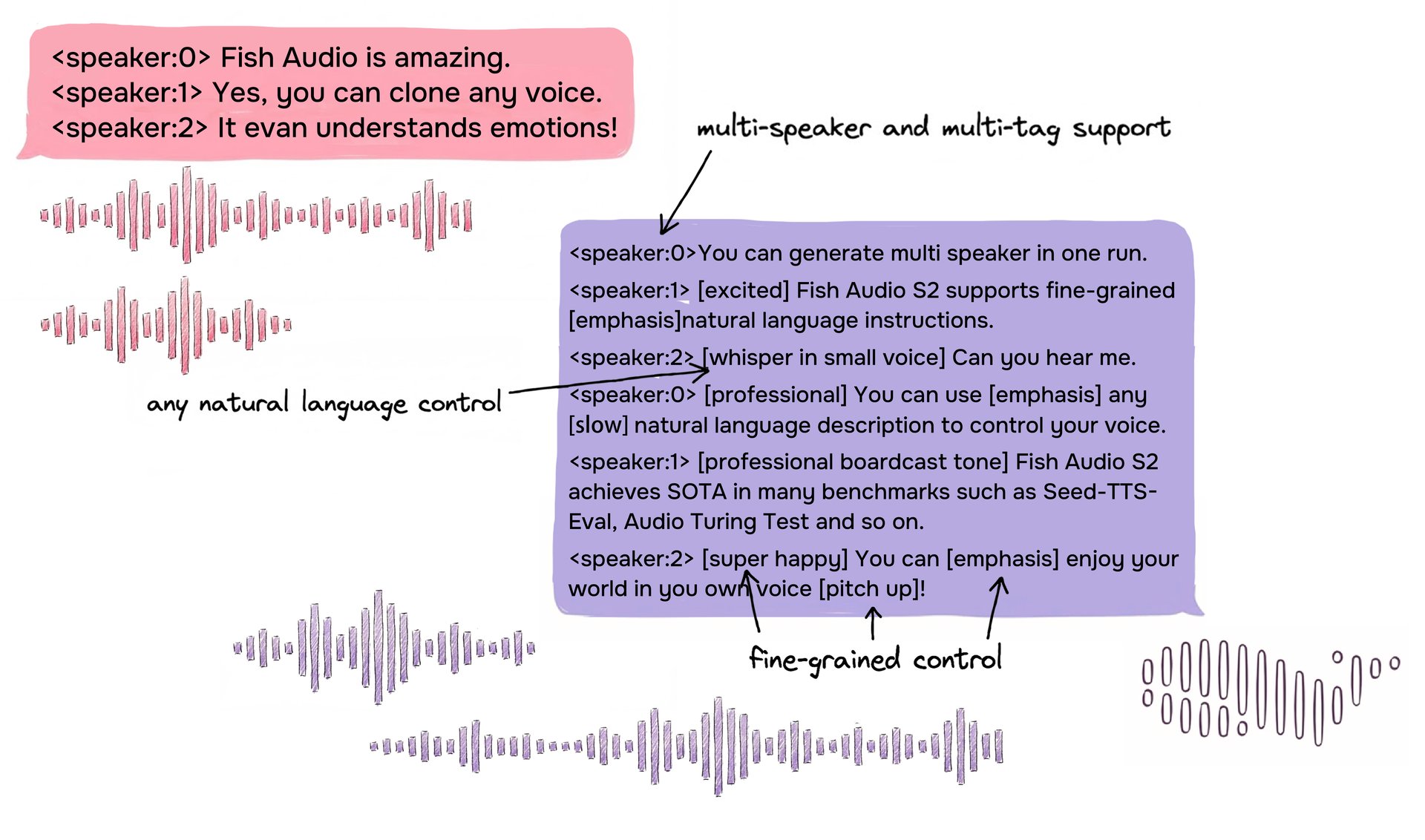 Beispiel für das S2-Eingabeformat mit einem Dialog mehrerer Sprecher und freiformulierten natürlichsprachlichen Inline-Tags für eine feingranulare Steuerung.
Beispiel für das S2-Eingabeformat mit einem Dialog mehrerer Sprecher und freiformulierten natürlichsprachlichen Inline-Tags für eine feingranulare Steuerung.
Ein einheitliches Rezept: Daten-Kuratierung und RL-Belohnungen aus denselben Modellen
Eine zentrale architektonische Entscheidung bei S2 ist, dass dieselben Modelle, die zum Filtern und Annotieren der Trainingsdaten verwendet werden, direkt als Belohnungsmodelle (Reward Models) während des Reinforcement Learning wiederverwendet werden:
- Sprachqualitätsmodell bewertet Audioaufnahmen während der Datenfilterung in Dimensionen wie SNR, Sprecherkonsistenz und Verständlichkeit – und dient dann als akustische Präferenzbelohnung während des RL.
- Rich-Transcription ASR-Modell (weiterentwickelt aus Qwen3-Omni-30B-A3B) generiert während der Daten-Kuratierung mit Captions ergänzte Transkripte mit paralinguistischen Inline-Annotationen – und liefert dann die Belohnung für Verständlichkeit und Befolgung von Anweisungen, indem es generiertes Audio erneut transkribiert und mit dem ursprünglichen Prompt vergleicht.
Dieses duale Design eliminiert konstruktionsbedingt die Verteilungsdiskrepanz (Distribution Mismatch) zwischen Pre-Training-Daten und Post-Training-Zielen – ein Problem, das in anderen TTS-Systemen, die Belohnungsmodelle getrennt von ihren Daten-Pipelines trainieren, ungelöst bleibt.
Blick ins Modell: Dual-AR-Architektur
S2 basiert auf einem Decoder-only Transformer in Kombination mit einem RVQ-basierten Audio-Codec (10 Codebücher, ~21 Hz Framerate). Das Abflachen aller Codebücher entlang der Zeitachse würde zu einer zehnfachen Explosion der Sequenzlänge führen. S2 löst dies mit einer Dual-Autoregressiven (Dual-AR) Architektur:
- Slow AR arbeitet entlang der Zeitachse und sagt das primäre semantische Codebuch voraus.
- Fast AR generiert bei jedem Zeitschritt die verbleibenden 9 Residual-Codebücher und rekonstruiert so feingranulare akustische Details.
Dieses asymmetrische Design – 4 Mrd. Parameter entlang der Zeitachse, 400 Mio. Parameter entlang der Tiefenachse – hält die Inferenz effizient und bewahrt gleichzeitig die Audioqualität.
Reinforcement Learning Alignment für Sprache
Für das Post-Training verwendet S2 die Group Relative Policy Optimization (GRPO), die gewählt wurde, um den Speicher-Overhead von Value-Modellen im PPO-Stil in langen Audiokontexten zu vermeiden. Das Belohnungssignal kombiniert mehrere Dimensionen, darunter:
- Semantische Genauigkeit und Befolgung von Anweisungen
- Akustische Präferenzbewertung
- Timbre-Ähnlichkeit
Benchmark-Ergebnisse
S2 erzielt führende Ergebnisse in mehreren öffentlichen Benchmarks:
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chinesisch) | 0,54 % (insgesamt am besten) |
| Seed-TTS Eval — WER (Englisch) | 0,99 % (insgesamt am besten) |
| Audio Turing Test (mit Anweisung) | 0,515 Posterior-Mittelwert |
| EmergentTTS-Eval — Win-Rate | 81,88 % (insgesamt am höchsten) |
| Fish Instruction Benchmark — TAR | 93,3 % |
| Fish Instruction Benchmark — Qualität | 4,51 / 5,0 |
| Multilingual (MiniMax Testset) — Beste WER | 11 von 24 Sprachen |
| Multilingual (MiniMax Testset) — Beste SIM | 17 von 24 Sprachen |
Bei Seed-TTS Eval erreicht S2 die niedrigste WER unter allen evaluierten Modellen, einschließlich Closed-Source-Systemen: Qwen3-TTS (0,77/1,24), MiniMax Speech-02 (0,99/1,90), Seed-TTS (1,12/2,25). Beim Audio Turing Test übertrifft 0,515 Seed-TTS (0,417) um 24 % und MiniMax-Speech (0,387) um 33 %. Bei EmergentTTS-Eval erzielt S2 besonders starke Ergebnisse in den Bereichen Paralinguistik (91,61 % Win-Rate), Fragen (84,41 %) und syntaktische Komplexität (83,39 %).
Produktionsreifes Streaming via SGLang
Da die Dual-AR-Architektur von S2 strukturell isomorph zu standardmäßigen autoregressiven LLMs ist, kann sie direkt alle LLM-nativen Serving-Optimierungen von SGLang mit minimalen Änderungen übernehmen – einschließlich Continuous Batching, Paged KV Cache, CUDA Graph Replay und RadixAttention-basiertem Prefix Caching.
Für das Voice Cloning platziert S2 Referenz-Audio-Token im System-Prompt. RadixAttention von SGLang cached diese KV-Zustände automatisch und erreicht eine durchschnittliche Prefix-Cache-Trefferquote von 86,4 % (über 90 % in der Spitze), wenn dieselbe Stimme über mehrere Anfragen hinweg wiederverwendet wird – wodurch der Overhead für den Referenz-Audio-Prefill fast vernachlässigbar wird.
Auf einer einzelnen NVIDIA H200 GPU:
- Real-Time Factor (RTF): 0,195
- Time-to-first-audio: ca. 100 ms
- Durchsatz: 3.000+ akustische Token/s bei einem RTF unter 0,5
Warum diese Veröffentlichung wichtig ist
S2 wird nicht nur als Modell-Checkpoint veröffentlicht, sondern als komplettes System: Modellgewichte, Fine-Tuning-Code und ein produktionsreifer Inferenz-Stack.
Zwei Design-Entscheidungen stechen hervor. Erstens eliminiert die einheitliche Daten- und Belohnungs-Pipeline ein strukturelles Problem – die Verteilungsdiskrepanz zwischen Pre-Training und RL –, das andere TTS-Systeme auf architektonischer Ebene bisher nicht gelöst haben. Zweitens bedeutet die strukturelle Isomorphie zwischen der Dual-AR-Architektur und Standard-LLMs, dass S2 das gesamte Ökosystem von LLM-Serving-Optimierungen nutzen kann, anstatt eine maßgeschneiderte Inferenz-Infrastruktur zu erfordern.
S2 ist über das GitHub-Repository des Projekts, SGLang-Omni, HuggingFace und als interaktive Demo auf fish.audio verfügbar.



