Fish Audio S2! Fein abgestimmte KI-Stimmsteuerung auf Wortebene

Fish Audio S2 bringt Open-Domain-Inline-Tags, KI-Stimmsteuerung auf Wortebene und Unterstützung für 80 Sprachen in die expressive TTS. Erfahren Sie anhand echter Beispiele, wie es funktioniert.
März 2026 | Fish Audio S2 ist ab sofort verfügbar
Inhaltsverzeichnis
-
Was ist Fish Audio S2?
-
Was S2 kann — In 30 Sekunden
-
Inline-Tags in Fish Audio S2
-
Echte Beispiele
-
Die Leistung von S2 — Benchmark-Ergebnisse
-
80 Sprachen
-
Open Source
-
Erste Schritte
-
FAQ
Die meisten KI-Stimm-Tools bieten Ihnen eine Stimme und lassen Sie die Stimmung auf globaler Ebene anpassen — ruhiger, energetischer, etwas wärmer. Fish Audio S2 verfolgt einen anderen Ansatz für expressive TTS. Sie führen Regie über die Stimme auf Wortebene, in einfacher Sprache, direkt in Ihrem Skript. Wenn Sie mit den Fish Audio Emotions-Tags in S1 vertraut sind: S2 erweitert dieses Konzept dramatisch durch Open-Domain-Inline-Steuerung.
So sieht das in der Praxis aus:
I thought I was ready. [voice breaking] I wasn't.
[soft voice] Take your time. There's no rush.
That was the third time this week. [sigh] I really need to fix that.
Keine Einstellungsmenüs. Kein SSML. Keine Postproduktion. Sie schreiben die Anweisung direkt in den Text, und S2 setzt sie um.
Kurzzusammenfassung
Fish Audio S2 führt Inline-Tags für die expressive TTS-Steuerung auf Wortebene ein.
-
Open-Domain-Tags in natürlicher Sprache — kein festes Vokabular
-
Platzierung mitten im Satz für präzises Timing und Wechsel in der Darbietung
-
Unterstützung für ca. 80 Sprachen
-
Open-Source-Modellgewichte, Fine-Tuning-Code und Inference-Stack
Anstatt globale Stimmeinstellungen anzupassen, lässt S2 Sie die Darbietung direkt in Ihrem Skript steuern.
Was ist Fish Audio S2?
https://www.youtube.com/watch?v=NIcXTOSdOXc
Fish Audio S2 ist das TTS-Modell der zweiten Generation von Fish Audio. Es wurde mit über 10 Millionen Stunden Audiomaterial in etwa 80 Sprachen trainiert und führt die Inline-Tag-Steuerung ein: Anweisungen in natürlicher Sprache, die an jeder beliebigen Stelle direkt in Ihr Skript eingebettet werden können. Dies ermöglicht eine fein abgestimmte Steuerung darüber, wie Sprache auf Wort- oder Phrasenebene ausgegeben wird.
Das Modell ist Open Source auf GitHub und HuggingFace verfügbar und kann über die Fish Audio API und APP genutzt werden.
Was S2 kann — In 30 Sekunden
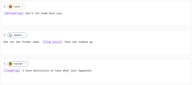
Die Inline-Tags von S2 sind Anweisungen in eckigen Klammern, die an einer beliebigen Stelle in Ihrem Text platziert werden:
[whispering] Don't let them hear you.
She set the folder down. [long pause] Then she looked up.
[laughing] I have absolutely no idea what just happened.
Tags beeinflussen das, was nach ihnen kommt. Platzieren Sie den Tag genau an dem Punkt, an dem der Wechsel stattfinden soll — nicht am Anfang des Satzes, es sei denn, Sie möchten es genau dort.
Sie wählen nicht aus einem festen Menü. Sie schreiben die Beschreibung, und S2 interpretiert sie:
[the calm, measured tone of someone who has done this a thousand times]
Please place your hands where I can see them.
[overly cheerful, clearly forcing it]
Everything is completely fine. Totally fine.
Wenn Sie es einem Synchronsprecher beschreiben können, kann S2 es versuchen.
Inline-Tags in Fish Audio S2
Inline-Tags sind der zentrale Steuerungsmechanismus in Fish Audio S2. Es handelt sich um Anweisungen in natürlicher Sprache in [eckigen Klammern], die Sie direkt in Ihr Skript einbetten, um die Sprechweise zu steuern — bei jedem Wort, an jedem Punkt.
Syntax
Platzieren Sie einen Tag in [eckigen Klammern] unmittelbar vor dem Wort oder der Phrase, die er beeinflussen soll. Tags können überall stehen — am Anfang, in der Mitte oder am Ende eines Satzes.
[whispering] I didn't want to go inside.
I didn't want to go [whispering] inside.
Beides funktioniert. Das erste flüstert die gesamte Zeile. Das zweite flüstert ab „inside“. Die Platzierung bestimmt die Bedeutung.
Schreiben Sie Tags in Ihrer Sprache
Tags müssen nicht auf Englisch sein. S2 versteht Anweisungen in natürlicher Sprache in 80 Sprachen — Sie können Tags also in derselben Sprache wie Ihr Skript schreiben.
日本語 (Japanisch)
[囁き声で] 誰にも聞かせないで。
[ため息をついて] もう一度やり直そう。
中文 (Chinesisch)
[低声说] 不要让他们听见。
[叹气] 我真的不知道该怎么办了。
español (Spanisch)
[susurrando] No dejes que te escuchen.
[enojado] ¿Cómo pudiste hacer eso?
한국어 (Koreanisch)
[속삭이며] 아무도 모르게 해줘.
[화나서] 어떻게 그럴 수가 있어.
Es gilt dieselbe Logik: Platzieren Sie den Tag unmittelbar vor dem Wort oder der Phrase, die er beeinflussen soll, in der Sprache, die sich für Ihr Skript natürlich anfühlt.
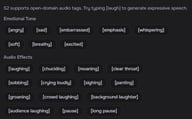
Bewährte Tags
S2 akzeptiert jede Beschreibung in natürlicher Sprache, aber diese Tags liefern konsistent starke Ergebnisse. Tags gelten ab dem Punkt ihres Erscheinens bis zum nächsten Tag oder zum Ende des Satzes.
Atmung & Reaktionen
Vokale Klänge
Tempo
Stimmstil
Emotion
Sonstiges
Freiform-Beschreibungen
Über die obige Liste hinaus akzeptiert S2 völlig freie Beschreibungen. Schreiben Sie das, was Sie einem Synchronsprecher sagen würden:
[speaking slowly, almost hesitant]
[professional broadcast tone]
[dead tired, end of a very long shift]
[pitch up]
[voice rough from crying, trying to sound normal]
Da S2 mit offenen Beschreibungen trainiert wurde, lassen sich neue Tags gut verallgemeinern — Sie sind nicht auf Beispiele beschränkt, die während des Trainings vorkamen.
Kombinieren von Tags
Verketten Sie Tags über einen Abschnitt hinweg, um Wechsel in der Darbietung zu erzeugen:
[soft voice] I wasn't sure what to say. [long pause] [loud voice] But then it hit me.
Verwenden Sie Reaktions-Tags zwischen Sätzen für natürliche Übergänge:
That was the third time this week. [sigh] I really need to fix that.
Die Kombination einer Reaktion mit einem Emotions-Tag lässt das Gefühl physisch realer wirken:
[sigh] [sad] I just don't know anymore.
Echte Beispiele
Hörbuch-Vertonung
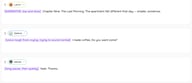
[NARRATOR, low and slow] Chapter Nine. The Last Morning. The apartment felt different that day — smaller, somehow.
SARAH: [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
DANIEL: [long pause, then quietly] Yeah. Thanks.
Podcast

Today we're looking at something I've spent three months trying to understand.
[chuckling] I kept getting it wrong. My producer will confirm this.
Spiel-Dialog
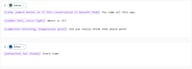
VILLAIN: [calm, almost bored, as if this conversation is beneath them] You came all this way.
VILLAIN: [sudden fury, voice tight] Where is it?
VILLAIN: [composure returning, dangerously quiet] Did you really think that would work?
HERO: [exhausted, but steady] Every time.
Sprachassistent

[friendly, warm] Hi — thanks for calling. How can I help you today?
[empathetic, unhurried] I'm sorry to hear that. Let me pull this up.
[confident] Good news — I can see exactly what happened, and I'm going to get this sorted for you right now.
Tipps für die besten Ergebnisse
Die Inline-Tags von S2 sind ausdrucksstark, aber wie stark sie wirken, hängt davon ab, wie Sie sie einsetzen — und mit welcher Stimme Sie arbeiten. Diese Tipps basieren auf Praxistests.

Kombinieren Sie physische Tags mit einem Emotions-Tag. Tags wie [panting], [whispering] und [shouting] funktionieren zwar allein, aber der Effekt kann ohne emotionalen Kontext flach wirken. Die Kombination mit einem Emotions-Tag liefert konsistentere, natürlicher klingende Ergebnisse:
[panting] [tired] I've been running for twenty minutes.
[whispering] [scared] Don't move. Don't make a sound.
[shouting] [angry] I told you this would happen!

Lassen Sie auf einen beschreibenden Tag immer Text folgen. Ein beschreibender Tag wie [voice rough from crying, trying to sound normal] benötigt eine Zeile zum Sprechen — lassen Sie ihn nicht allein stehen. Der Tag steuert die Darbietung dessen, was folgt; ohne Text danach kann die Ausgabe unvorhersehbar sein.
✅ [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
❌ [voice rough from crying, trying to sound normal]
Testen Sie die Stimme, bevor Sie das Skript erstellen. Verschiedene Stimmen reagieren auf denselben Tag mit unterschiedlicher Intensität. Eine Stimme mit einer von Natur aus ruhigen Lage zeigt subtilere Änderungen als eine ausdrucksstarke. Wenn ein Tag nicht wie erwartet wirkt, versuchen Sie es mit einer anderen Stimme, bevor Sie den Tag selbst anpassen — das Problem liegt oft an der Stimme, nicht an der Anweisung.
Beginnen Sie einfach und fügen Sie dann Ebenen hinzu. Ein einzelner, gut platzierter [sigh] oder [long pause] kann eine Zeile komplett verändern. Fügen Sie erst dann mehr Tags hinzu, wenn die einfachere Version nicht ausreicht. Zu viele Tags können sich gegenseitig stören.
Demnächst: Wählen Sie Ihren Favoriten aus mehreren Generierungen. S2 wird die gleichzeitige Generierung mehrerer Versionen derselben Zeile unterstützen, sodass Sie die Darbietung vergleichen und auswählen können, die am besten passt — ähnlich wie bei Bildgenerierungstools, bei denen Sie aus einem Batch wählen können. Dies wird es erheblich erleichtern, die richtige Performance zu finden, ohne die Tags jedes Mal manuell anpassen zu müssen.
Die Leistung von S2 — Benchmark-Ergebnisse
Die Inline-Steuerung von S2 ist nicht nur ein UX-Feature — sie korreliert auch mit einer starken Leistung in öffentlichen Sprach-Benchmarks. Diese Benchmarks messen die Natürlichkeit der Sprache, die Genauigkeit der Aussprache und die Fähigkeit zur Befolgung von Anweisungen bei modernen TTS-Systemen.
Beim Audio-Turing-Test erzielt S2 eine Punktzahl von 0,515 — und übertrifft damit Seed-TTS um 24 % und MiniMax-Speech um 33 %. Bei EmergentTTS-Eval erreicht es besonders starke Ergebnisse in der Paralinguistik (91,61 % Gewinnrate), was direkt die Qualität der Inline-Tag-Ausführung widerspiegelt.
Bei Seed-TTS Eval erreicht S2 die niedrigste Wortfehlerrate unter allen evaluierten Modellen, einschließlich Closed-Source-Systemen: Qwen3-TTS (0,77 % / 1,24 %), MiniMax Speech-02 (0,99 % / 1,90 %) und Seed-TTS (1,12 % / 2,25 %).
Quelle: Fish Audio S2 Launch-Beitrag von Shijia Liao, Chief Scientist
80 Sprachen
S2 wurde mit über 10 Millionen Stunden Audiomaterial in etwa 80 Sprachen trainiert. Im multilingualen MiniMax-Testset, das 24 Sprachen abdeckt, erreicht S2 in 11 Sprachen die beste Wortfehlerrate und in 17 die beste Sprecherähnlichkeit — und übertrifft damit sowohl MiniMax als auch ElevenLabs in der Mehrheit des Benchmarks.
Zu den Sprachen mit bestätigter starker Leistung gehören: Arabisch, Kantonesisch, Chinesisch, Tschechisch, Niederländisch, Englisch, Finnisch, Französisch, Deutsch, Griechisch, Hindi, Indonesisch, Italienisch, Japanisch, Koreanisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Spanisch, Thailändisch, Türkisch, Ukrainisch, Vietnamesisch.
Open Source
Im Gegensatz zu den meisten kommerziellen TTS-Systemen ist Fish Audio S2 vollständig Open Source — Modellgewichte, Fine-Tuning-Code und eine produktionsreife, auf SGLang basierende Inference-Engine — was es Entwicklern ermöglicht, das Modell selbst zu hosten, zu verfeinern und in großem Maßstab einzusetzen.
-
GitHub: github.com/fishaudio/fish-speech
-
HuggingFace: huggingface.co/fishaudio/s2-pro
-
SGLang Inference: SGLang-Omni
Produktionsleistung auf einer einzelnen H200-GPU:
-
Echtzeit-Faktor: 0,195
-
Zeit bis zum ersten Audio: ~100ms
-
Durchsatz: 3.000+ akustische Token/s
Für das Stimmenklonen im großen Maßstab platziert S2 Referenz-Audio-Token im System-Prompt. Der KV-Cache von SGLang erreicht eine durchschnittliche Prefix-Cache-Trefferquote von 86,4 %, wenn dieselbe Stimme über mehrere Anfragen hinweg wiederverwendet wird — was den Overhead für wiederholtes Stimmenklonen nahezu vernachlässigbar macht.
Erste Schritte
-
Probieren Sie es in der APP aus — fish.audio unterstützt S2-Inline-Tags direkt. Platzieren Sie
[eckige Klammern]an einer beliebigen Stelle in Ihrem Skript und generieren Sie. -
Über die API integrieren — Verfügbar über die Fish Audio API. In der API-Referenz finden Sie Informationen zu Endpunkten und Authentifizierung.
-
Das Modell selbst hosten — Gewichte und Inference-Stack sind Open Source auf GitHub und HuggingFace verfügbar.
-
Demnächst verfügbar: Dialog-Generierung mit mehreren Sprechern in der Fish Audio APP und API.
-
Für eine vollständige Anleitung zu Inline-Tag-Syntax, Platzierungsregeln und Tipps: → Verwendung von Fish Audio S2 Inline-Tags
-
Wenn Sie von S1 kommen und wissen möchten, wie die beiden Systeme zusammenhängen: → Fish Audio S1 Emotions-Tags — Vollständiger Leitfaden
FAQ
Was sind Inline-Tags in TTS?
Inline-Tags sind kurze Anweisungen, die direkt in ein Text-to-Speech-Skript eingebettet werden, um zu steuern, wie ein bestimmtes Wort oder eine Phrase gesprochen wird — die Darbietung, Emotion, das Tempo oder die Stimmqualität an genau diesem Punkt. Im Gegensatz zu globalen Stimmeinstellungen, die für eine gesamte Generierung gelten, ermöglichen Inline-Tags die Steuerung einzelner Momente innerhalb einer Zeile. Fish Audio S2 verwendet [eckige Klammern] für Inline-Tags und akzeptiert freie Beschreibungen in natürlicher Sprache.
Was ist Fish Audio S2?
Fish Audio S2 ist das TTS-Modell der zweiten Generation von Fish Audio. Es unterstützt eine fein abgestimmte Inline-Steuerung über Tags in natürlicher Sprache in [eckigen Klammern], die überall in einem Skript platziert werden können. Trainiert wurde es mit über 10 Millionen Stunden Audiomaterial in etwa 80 Sprachen. Es ist Open Source auf GitHub und HuggingFace verfügbar und kann über die Fish Audio API und APP genutzt werden.
Wie funktionieren Inline-Tags in S2?
Platzieren Sie einen Tag in [eckigen Klammern] unmittelbar vor dem Wort oder der Phrase, die er beeinflussen soll. Sie können bewährte Tags wie [whispering], [sigh] oder [long pause] verwenden oder jede beliebige Beschreibung in natürlicher Sprache schreiben. Tags gelten für alles Folgende bis zum nächsten Tag oder zum Ende des Satzes.
Ist Fish Audio S2 Open Source?
Ja. Modellgewichte, Fine-Tuning-Code und die SGLang-basierte Inference-Engine sind Open Source unter github.com/fishaudio/fish-speech und huggingface.co/fishaudio/s2-pro verfügbar.
Wie viele Sprachen unterstützt S2?
S2 wurde mit etwa 80 Sprachen trainiert. In einem multilingualen Benchmark mit 24 Sprachen erreicht S2 die beste Wortfehlerrate in 11 Sprachen und die beste Sprecherähnlichkeit in 17, womit es MiniMax und ElevenLabs übertrifft.
Unterstützt S2 die Klammer-Syntax () von S1?
Nein. S2 verwendet nativ [eckige Klammern]. Die Fish Audio Web-Oberfläche übersetzt () automatisch in [], wenn S2 ausgewählt ist. Wenn Sie jedoch die API direkt verwenden, nutzen Sie eckige Klammern.
Unterstützt S2 Dialoge mit mehreren Sprechern?
Die Generierung für mehrere Sprecher wird in Kürze in der Fish Audio APP und API verfügbar sein. Das Modell unterstützt dies nativ — bleiben Sie gespannt auf den Rollout.
Was ist der Unterschied zwischen Fish Audio S1 und S2?
S1 verwendet ein festes Vokabular aus voreingestellten Emotions-Tags in (runden Klammern), die am Anfang von Sätzen platziert werden. S2 verwendet Open-Domain-Tags in natürlicher Sprache in [eckigen Klammern], die überall im Skript erscheinen können — mitten im Satz, zwischen Wörtern oder am Anfang. S2 akzeptiert zudem freie Beschreibungen anstelle einer geschlossenen Stichwortliste, sodass Sie nicht auf vordefinierte Emotionen beschränkt sind. Eine vollständige Aufschlüsselung finden Sie im Fish Audio S1 Emotions-Tag-Leitfaden.
Kann Fish Audio S2 SSML ersetzen?
Für die meisten expressiven Anwendungsfälle: Ja. Fish Audio S2 kann viele SSML-ähnliche Steuerungen durch Inline-Tags in natürlicher Sprache nachbilden — statt XML-Markup wie <prosody rate="slow"> schreiben Sie [speaking slowly] direkt in das Skript. Tags wie [whispering], [long pause] und [angry] decken die häufigsten expressiven Funktionen von SSML ab, ohne dass spezielle Markup-Kenntnisse erforderlich sind.
Sind die Inline-Tags von Fish Audio S2 mit anderen TTS-Systemen kompatibel?
Nein. Die Inline-Tag-Syntax in Fish Audio S2 ist spezifisch für dieses Modell. Andere TTS-Systeme verwenden SSML oder eigene proprietäre Formate. Die zugrunde liegenden expressiven Konzepte — Pausen, Tonfalländerungen, vokale Hinweise — lassen sich jedoch konzeptionell übertragen, auch wenn die Syntax abweicht.
Weiterführende Ressourcen:

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
Mehr von Sabrina Shu lesen







