Text-to-Speech mit mehreren Stimmen — Der komplette Multispeaker-Leitfaden (Fish Audio)

Einstimmiges TTS klingt flach für Dialoge, Hörbücher und Podcasts. Dieser Leitfaden zeigt Ihnen, wie Sie Stimmen auf Fish Audio finden und organisieren und anschließend Multispeaker in TTS und Story Studio verwenden, um natürliche Audioinhalte mit mehreren Charakteren zu erstellen – ganz ohne traditionelle Sprachaufnahmeprozesse.
März 2026 | Fish Audio Multispeaker TTS ist jetzt auf S2 Pro verfügbar
Inhaltsverzeichnis
- Was ist Multispeaker Text-to-Speech?
- Schritt 1 — Die richtigen Stimmen mit Discovery finden
- Schritt 2 — Multispeaker in Text-to-Speech
- Schritt 3 — Multispeaker in Story Studio
- TTS vs. Story Studio — Welches sollten Sie verwenden?
- Anwendungsfälle — Was können Sie mit Multispeaker TTS erstellen?
- Vom Skript zum Audio — In einer Sitzung
- FAQs zu Multispeaker TTS
Die meisten Text-to-Speech-Tools bieten Ihnen nur eine Stimme. Einen Erzähler. Einen Tonfall, von Anfang bis Ende. Für ein Erklärvideo mit einem einzelnen Sprecher funktioniert das gut. Aber in dem Moment, in dem Ihr Skript zwei sich unterhaltende Charaktere, einen Moderator und einen Gast oder eine Geschichte mit verschiedenen Rollen umfasst, verwandelt eine einzige Stimme den Dialog in eine flache, monotone Lesung. Zuhörer schalten schnell ab.
Text-to-Speech mit mehreren Stimmen löst dieses Problem. Weisen Sie jedem Sprecher eine andere AI-Stimme zu, steuern Sie das Timing zwischen ihnen, und das Ergebnis ist ein Gespräch, das auch wie eines klingt. Fish Audio fungiert als kompletter Text-to-Speech-Dialoggenerator — von der Entdeckung der Stimmen bis hin zum Export mehrerer Kapitel. Dieser Leitfaden führt Sie durch den gesamten Workflow: wie Sie Stimmen entdecken und organisieren, wie Sie Multispeaker im Text-to-Speech-Tool für kürzere Inhalte nutzen und wie Sie mit Story Studio zu vollwertigen Produktionen skalieren.
Was ist Multispeaker Text-to-Speech?
Multispeaker Text-to-Speech ist ein TTS-Workflow, bei dem verschiedenen Abschnitten eines Skripts unterschiedliche AI-Stimmen zugewiesen werden — jede mit ihrem eigenen Tonfall, Geschlecht, Alter und Sprechstil — und dann als eine einzige, kontinuierliche Audiodatei generiert werden.
Traditionelle TTS-Tools sind um ein einzelnes Narrationsmodell herum aufgebaut: eine Stimme, eine Texteingabe, eine Audiodatei. Dieses Design funktioniert für die Vertonung von Hörbüchern mit einem einzelnen Erzähler, Voiceover oder Ankündigungen. Bei allem, was Dialoge beinhaltet, versagt es jedoch völlig. Um eine Unterhaltung mit zwei Charakteren mit veralteten Tools zu erstellen, müssten Sie jeden Sprecher separat generieren und das Audio dann manuell in einem Editor zusammenfügen — wobei Sie das Timing anpassen, Lautstärken abgleichen und hoffen müssen, dass die Übergänge nicht wie zwei verschiedene Aufnahmen klingen.
Das Problem sind nicht nur die zusätzlichen Schritte. Es ist fast unmöglich, das Timing zwischen den Sprechern ohne dedizierte Steuerelemente richtig hinzubekommen. Ein echtes Gespräch hat einen Rhythmus: eine kurze Stille vor einer Antwort, ein leichtes Überlappen, wenn jemand unterbricht, eine längere Pause vor einer schwierigen Antwort. Ohne präzise Kontrolle über die Lücken zwischen den Sprechern klingt selbst ein gut besetzter Dialog roboterhaft.
Multispeaker-TTS-Tools lösen beide Probleme. Jeder Sprecher erhält seine eigene Stimme und seinen eigenen Textblock. Die Abstände zwischen den Sprechern sind anpassbar. Das Endergebnis ist eine einzige, kohärente Audiodatei — inklusive des fertigen Timings.
Multispeaker Text-to-Speech ermöglicht Ihnen:
- Jedem Sprecher in einem Skript eine andere AI-Stimme zuzuweisen
- Das Timing und die Pausen zwischen jedem Sprecher zu steuern
- Einen gesamten Dialog als eine einzige, kontinuierliche Audiodatei zu generieren
- Von einem Austausch zwischen zwei Personen bis hin zu einem kompletten Ensemble zu skalieren — ohne zusätzliche Exporte oder manuelle Bearbeitung
Schritt 1 — Die richtigen Stimmen mit Discovery finden
Bevor Sie ein Multispeaker-Projekt erstellen können, benötigen Sie Stimmen. Auf der Discovery-Seite von Fish Audio finden Sie diese — und bei Tausenden von Stimmen in der Bibliothek sind die Filterwerkzeuge entscheidend.
Gehen Sie zu fish.audio/app/discovery/.
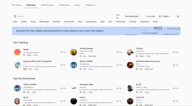
Suchen und Filtern
Die Discovery-Seite öffnet sich mit einer Suchleiste, Quick-Filter-Tags in der oberen Zeile sowie Sortier- und Sprachsteuerungen auf der rechten Seite.
Suchen Sie nach Namen, wenn Sie bereits wissen, wonach Sie suchen. Sortieren Sie nach Empfohlen (Recommended) oder Trending, um zu sehen, was für andere Creator gut funktioniert. Der Sprachfilter (Language) filtert die gesamte Bibliothek nach Stimmen, die in Ihrer Zielsprache trainiert wurden.
Die Quick-Filter-Tags oben decken die gängigsten Attribute ab — Männlich, Weiblich, Jung, Mittleres Alter, Narration, Social Media, Tief, Sanft, Professionell, Dramatisch, Geheimnisvoll, Anime — und Sie können diese kombinieren. Wenn Sie Weiblich + Jung + Narration auswählen, werden die Ergebnisse sofort auf Stimmen eingegrenzt, die diesem Profil entsprechen.

Für mehr Kontrolle öffnen Sie das Filter-Panel (das Schieberegler-Icon oben rechts). Dies bietet Ihnen:
- Sprachen — Eingrenzung auf eine bestimmte Sprache, mit Multi-Sprach-Abgleich
- Tags — Von Erstellern hinzugefügte Freiform-Tags
- Geschlecht — Männlich, Weiblich, Neutral
- Alter — Jung, Mittleres Alter, Alt
- Anwendungsfall (Use Case) — Konversation, Narration, Charakterstimme, Social Media, Bildung, Werbung und mehr
- Stimmqualitäten — Tief, Niedrig, Mittel, Hoch, Sanft, Hell und über 48 weitere Deskriptoren
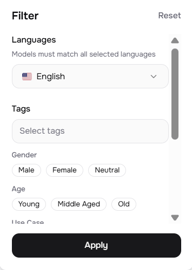
Für ein Multispeaker-Projekt sind die Filter für Anwendungsfall und Stimmqualitäten besonders nützlich. Wenn Sie einen Dialog im Podcast-Stil erstellen, möchten Sie vielleicht eine konversationelle, sanfte Stimme und eine tiefe Narrationsstimme — so unterschiedlich, dass die Zuhörer sie auseinanderhalten können, ohne das Transkript sehen zu müssen.
Liken, Bookmarken und in einer Collection speichern
Wenn Sie eine Stimme finden, die Sie wiederverwenden möchten, haben Sie mehrere Möglichkeiten, sie zu speichern. Das Herz-Icon auf jeder Sprachkarte in den Suchergebnissen ist ein schneller Like — es fügt die Stimme für später zu Ihrem Likes-Tab hinzu.
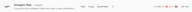
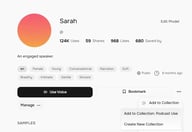
Für ein dauerhafteres Speichern öffnen Sie die Detailseite der Stimme und klicken Sie auf Bookmark. Lesezeichen markierte Stimmen erscheinen im Bookmarks-Tab, getrennt von Ihren Likes, und sind direkt über die Sprachauswahl in TTS und Story Studio zugänglich.
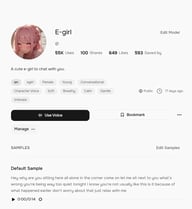
Für die Organisation auf Projektebene sind Collections die leistungsstärkste Option. Klicken Sie in der oberen Navigation auf Collections und dann auf Create Collection, um eine benannte Gruppe einzurichten — zum Beispiel „Podcast-Nutzung“ oder „Hörbuchprojekt A“. Vergeben Sie einen Titel und eine Beschreibung und klicken Sie auf Create.

Um eine Stimme zu einer Collection hinzuzufügen, öffnen Sie die Detailseite der Stimme, klicken Sie auf das Drei-Punkte-Menü (⋯) neben dem Bookmark-Button und wählen Sie Add to Collection. Wenn Sie bereits eine Collection erstellt haben, erscheint diese im Dropdown — ein Klick genügt, um die Stimme hinzuzufügen.
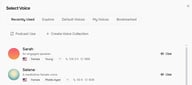
Der Vorteil zeigt sich, wenn Sie TTS oder Story Studio nutzen. Wenn Sie das Select Voice Panel öffnen, erscheinen Ihre Collections als Tabs oben — direkt neben Recently Used, Explore, Default Voices, My Voices und Bookmarked. Anstatt jedes Mal von vorne zu suchen, sind Ihre Projektstimmen bereits gruppiert und bereit.
Schritt 2 — Multispeaker in Text-to-Speech
Das Text-to-Speech-Tool von Fish Audio unterstützt mehrere Sprecher in einer einzigen Generierung. Es ist das richtige Werkzeug für kurze bis mittellange Inhalte — Dialogschnipsel, Anzeigen, kurze Podcast-Intros, Demo-Skripte und alles, bei dem Sie ein schnelles, poliertes Ergebnis ohne Kapitelverwaltung benötigen. Wenn Sie Ihre Stimmen noch nicht gefunden haben, stöbern Sie zuerst in der Discovery-Bibliothek.
Gehen Sie zu fish.audio/app/text-to-speech/.
Ihren ersten Sprecher einrichten
Wenn Sie TTS öffnen, sehen Sie einen einzelnen Textblock mit einer Sprachauswahl oben. Klicken Sie auf den Namen der Stimme, um das Select Voice Panel zu öffnen und Ihren ersten Sprecher auszuwählen. Tippen oder fügen Sie die Sätze des ersten Sprechers in den Textblock ein.
Sie können auch Inline-Emotion-Tags verwenden, um die Aussprache zu beeinflussen — [sad], [emphasis], [excited] — direkt im Text vor den Wörtern platziert, die sie betreffen sollen.
Weitere Sprecher hinzufügen
Klicken Sie auf + Add Speaker unter dem ersten Textblock. Ein neuer Block erscheint mit einer eigenen, unabhängigen Sprachauswahl. Wählen Sie eine andere Stimme für diesen Sprecher, geben Sie den Text ein, und die beiden Blöcke werden als eine einzige, kontinuierliche Audiodatei generiert — in der Reihenfolge, in der sie auf dem Bildschirm erscheinen.
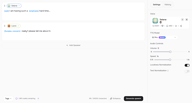
Es gibt keine Obergrenze für die Anzahl der Sprecher, die Sie hinzufügen können. Jeder Block ist unabhängig: andere Stimme, anderer Text, bei Bedarf andere Emotion-Tags. In der Praxis funktionieren die meisten Dialogprojekte gut mit 2–4 verschiedenen Stimmen — genug Vielfalt für Klarheit, ohne dass es schwer verständlich wird. Im rechten Panel können Sie Volume, Speed, Loudness Normalization und Text Normalization (was die Lesegenauigkeit von Zahlen, Währungen und ähnlichen Texten verbessert) vor der Generierung feinjustieren.
Zeichenlimit und wann Sie zu Story Studio wechseln sollten
Behalten Sie den Zeichenzähler am unteren Bildschirmrand im Auge. Das Limit hängt von Ihrem Plan ab — prüfen Sie die Preise und Pläne von Fish Audio für das spezifische Kontingent Ihrer Stufe. Für kurze und mittellange Inhalte ist TTS der schnellere und einfachere Workflow. Aber wenn Sie an etwas Längerem arbeiten — einem kompletten Hörbuchkapitel, einem mehrteiligen Podcast, einem Spiele-Dialogskript — bietet Story Studio die Werkzeuge, die Sie tatsächlich benötigen.
Schritt 3 — Multispeaker in Story Studio
Story Studio ist für die Produktion von Long-Form-Audio konzipiert. Während TTS auf schnelle Generierung optimiert ist, bietet Story Studio eine strukturierte Umgebung, um mehrere Stimmen Block für Block zu sequenzieren — mit präziser Kontrolle über das Timing zwischen den Sprechern und Kapitelorganisation für komplexe Projekte. Jeder Block wird unabhängig mit seiner zugewiesenen Stimme generiert, und der finale Export fügt sie zu einer einzigen, kontinuierlichen Datei zusammen. Gehen Sie zu fish.audio/app/story-studio/.
Ein neues Projekt erstellen
Klicken Sie auf + Project auf dem Startbildschirm von Story Studio. Der Dialog Create project öffnet sich mit diesen Einstellungen:
- Project Name — Benennen Sie Ihr Projekt
- Default Voice — Die Stimme, die neuen Blöcken standardmäßig zugewiesen wird (Sie können sie pro Block ändern)
- Speech Model — Derzeit S2 Pro (neueste Version)
- Text Normalization — Verbessert im aktivierten Zustand die Lesegenauigkeit von Zahlen, Währungen, Daten und ähnlichen Texten
- Loudness Normalization — Normalisiert die Lautstärkepegel über alle Blöcke hinweg für ein konsistentes Ergebnis
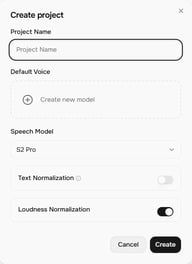
Klicken Sie auf Create, um den Projekteditor zu öffnen.
Blöcke hinzufügen und Stimmen wechseln
Ihr Projekt öffnet sich mit einem Standardkapitel und einem ersten Textblock. Die Stimme des ersten Sprechers wird als farbiger Avatar links neben jedem Block angezeigt.
Um die Zeile eines neuen Sprechers hinzuzufügen, klicken Sie auf den +-Button unter einem bestehenden Block. Ein neuer Block erscheint. Klicken Sie auf den farbigen Sprach-Avatar auf der linken Seite des neuen Blocks, um das Select Voice Panel zu öffnen und eine andere Stimme zuzuweisen. Tippen Sie den Text des zweiten Sprechers in den Block ein.
Wiederholen Sie dies für jeden Austausch in Ihrem Skript. Jeder Block entspricht dem Redeanteil eines Sprechers. Das rechte Panel zeigt Voices used in the project — eine Live-Liste jeder Stimme, die derzeit in allen Blöcken zugewiesen ist, damit Sie Ihr Ensemble auf einen Blick im Auge behalten können.
Feinanpassung der Pausen zwischen den Sprechern
Zwischen jedem Blockpaar sehen Sie eine kleine Timing-Bubble, die die aktuelle Pause anzeigt — zum Beispiel 0.35s. Klicken Sie darauf, um die Pausendauer zwischen diesem spezifischen Sprecherpaar anzupassen.
Dies ist eine der wichtigsten Funktionen von Story Studio für realistisch klingende Dialoge. Menschliche Gespräche bestehen nicht aus einer Abfolge perfekt aufeinanderfolgender Äußerungen. Ein Moment der Stille vor einer Antwort signalisiert Verarbeitungszeit. Eine längere Pause vor einer emotionalen Antwort verleiht ihr Gewicht. Diese Lücken richtig hinzubekommen, macht den Unterschied zwischen produziertem und echt klingendem Audio aus. Sogar eine Anpassung von 0,2–0,5s kann spürbar verändern, wie natürlich sich ein Gespräch anfühlt — es lohnt sich, jeden Austausch individuell abzustimmen, anstatt alle Lücken auf dem Standardwert zu lassen. Justieren Sie jede Pause zwischen den Blöcken individuell, um sie dem Rhythmus der Szene anzupassen.
Kapitel für lange Projekte hinzufügen
Auf der linken Seite des Editors sehen Sie das Chapters Panel. Standardmäßig beginnt jedes Projekt mit einem einzelnen „Default Chapter“. Klicken Sie auf +, um ein neues Kapitel hinzuzufügen.
Kapitel ermöglichen es Ihnen, lange Projekte in navigierbare Abschnitte zu unterteilen — ein Kapitel pro Hörbuchabschnitt, eines pro Podcast-Segment oder eines pro Szene in einem Spiele-Skript. Jedes Kapitel hat seine eigene Blocksequenz und kann unabhängig bearbeitet werden. Der finale Export kombiniert alle Kapitel in der richtigen Reihenfolge zu einer einzigen Datei.
Für alles, was über ein paar hundert Wörter Dialog hinausgeht, sind Kapitel die Methode, um ein Story Studio Projekt organisiert und bearbeitbar zu halten.
TTS vs. Story Studio — Welches sollten Sie verwenden?
| Text-to-Speech | Story Studio | |
|---|---|---|
| Multispeaker-Methode | Nativ (S2 Pro Modell-Ebene) | Sequenzielle Block-Generierung |
| Zeichenlimit | Plan-abhängig | Kein Limit (Multi-Kapitel) |
| Anzahl der Sprecher | Bis zu 5 | Unbegrenzt |
| Pausensteuerung | ❌ | ✅ Präzise, pro Block |
| Kapitelverwaltung | ❌ | ✅ |
| Timeline-Ansicht | ❌ | ✅ |
| Bestens geeignet für | Kurze Dialoge, Anzeigen, Demos | Hörbücher, Podcasts, Spiele-Skripte, lange Produktionen |
Der technische Hauptunterschied: TTS nutzt die native Multispeaker-Fähigkeit von S2 Pro — mehrere Sprecher werden auf Modell-Ebene in einer einzigen Generierung verarbeitet. Story Studio erreicht das Multispeaker-Ergebnis, indem es separat generierte Blöcke, jeder mit seiner eigenen zugewiesenen Stimme, in einer kontinuierlichen Datei aneinanderreiht.
Wenn Sie eine 30-sekündige Anzeige mit zwei Sprechern oder einen kurzen Dialog-Clip erstellen, beginnen Sie in TTS — es ist schneller und erfordert kein Projekt-Setup. Wenn Ihr Skript länger ist, mehr als nur ein paar Sätze umfasst oder präzises Timing zwischen den Sprechern benötigt, öffnen Sie stattdessen Story Studio.
Anwendungsfälle — Was können Sie mit Multispeaker TTS erstellen?
Hörbücher mit mehreren Charakteren
Hörbücher mit nur einem Erzähler funktionieren gut für Sachbücher. Bei Belletristik mit Dialogen wird es schwierig, einer einzelnen Stimme zu folgen, die alle Charaktere liest. Mit Multispeaker TTS erhält jeder Charakter in einer Szene seine eigene Stimme — eine tiefere, ältere Stimme für einen Charakter, eine jüngere und energischere für einen anderen. Die Kapitelstruktur von Story Studio lässt sich direkt auf Buchkapitel übertragen, was die Produktion kompletter Titel ohne traditionelle Casting- und Aufnahmeprozesse praktikabel macht.
Dialoge im Podcast-Stil
Podcast-Formate mit zwei Moderatoren gehören zu den bekanntesten Audiostrukturen überhaupt. Mit einem Multispeaker AI-Sprachgenerator für Dialoge können Sie dieses Format aus einem schriftlichen Skript erstellen — eine Stimme für jeden Moderator, mit gesteuerten Pausen, die ein natürliches Abwechseln simulieren. Dies ist besonders nützlich für Content Creator, die regelmäßig Audioinhalte produzieren möchten, ohne Aufnahmesitzungen planen zu müssen.
E-Learning und Schulungsinhalte
Lerninhalte werden deutlich ansprechender, wenn sie als Gespräch statt als Monolog präsentiert werden. Ein Lehrer-Schüler-Austausch, ein geführtes Szenario oder ein Q&A-Format können mit zwei oder mehr Stimmen geskriptet und produziert werden — was den Lernenden hilft, Informationen durch Dialog statt durch passive Erzählung zu verarbeiten.
Spiele-Dialoge und Charakterstimmen
Spiele-Skripte bestehen oft aus hunderten oder tausenden Zeilen für mehrere Charaktere. Durch die Nutzung von Story Studio als Generator für mehrere Charakterstimmen können Spieleentwickler und Narrative Designer vertonte Dialoge für Prototypen, Demos oder die Vollversion erstellen — wobei jedem NPC eine konsistente Stimme für jede Zeile zugewiesen wird, ohne dass traditionelle Sprachaufnahmeprozesse nötig sind.
Vom Skript zum Audio — In einer Sitzung
Die Produktion von Audioinhalten mit mehreren Charakteren bedeutete früher, Synchronsprecher zu buchen, Aufnahmesitzungen zu koordinieren und Stunden in der Postproduktion zu verbringen, um die Aufnahmen zusammenzufügen. Mit Multispeaker TTS reduziert sich dieser gesamte Workflow auf eine einzige Sitzung: Stimmen in Discovery finden, in einer Collection organisieren, das Skript Block für Block aufbauen und exportieren.
Für kurze Inhalte bringt Sie Text-to-Speech in wenigen Minuten ans Ziel. Für längere Produktionen — Hörbücher, Podcast-Serien, Spiele-Dialoge — bietet Ihnen Story Studio die Struktur und die Timing-Kontrolle, um etwas zu erschaffen, das wirklich wie eine echte Performance klingt.
🎧 Erstellen Sie Ihren ersten 2-Sprecher-Dialog in unter 2 Minuten →
🎙 Verwandeln Sie Ihr Skript mit AI-Stimmen in ein Hörbuch mit komplettem Ensemble →

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






