¡Fish Audio S2! Control de voz por IA detallado a nivel de palabra

Fish Audio S2 introduce etiquetas en línea de dominio abierto, control de voz por IA a nivel de palabra y soporte para 80 idiomas para un TTS expresivo. Mira cómo funciona con ejemplos reales.
Marzo de 2026 | Fish Audio S2 ya está disponible
Tabla de contenidos
-
¿Qué es Fish Audio S2?
-
Lo que S2 puede hacer en 30 segundos
-
Etiquetas en línea en Fish Audio S2
-
Ejemplos reales
-
Rendimiento de S2 — Resultados de benchmarks
-
80 idiomas
-
Código abierto
-
Cómo empezar
-
FAQ
La mayoría de las herramientas de voz por IA te ofrecen una voz y te permiten ajustar el tono a nivel global: más calmada, con más energía, un poco más cálida. Fish Audio S2 adopta un enfoque diferente para el TTS expresivo. Tú diriges la voz a nivel de palabra, en lenguaje sencillo, directamente dentro de tu guion. Si ya conoces las etiquetas de emoción de Fish Audio en S1, S2 amplía esa idea drásticamente con un control en línea de dominio abierto.
Esto es lo que parece en la práctica:
I thought I was ready. [voice breaking] I wasn't.
[soft voice] Take your time. There's no rush.
That was the third time this week. [sigh] I really need to fix that.
Sin paneles de configuración. Sin SSML. Sin posproducción. Escribes la dirección en el texto y S2 la interpreta.
Resumen rápido
Fish Audio S2 introduce etiquetas en línea para el control del TTS expresivo a nivel de palabra.
-
Etiquetas de dominio abierto escritas en lenguaje natural; sin vocabulario fijo
-
Colocación a mitad de frase para cambios precisos en el tiempo y la entonación
-
Soporte para aproximadamente 80 idiomas
-
Pesos del modelo de código abierto, código de ajuste fino y pila de inferencia
En lugar de ajustar la configuración global de la voz, S2 te permite dirigir la interpretación directamente dentro de tu guion.
¿Qué es Fish Audio S2?
https://www.youtube.com/watch?v=NIcXTOSdOXc
Fish Audio S2 es el modelo TTS de segunda generación de Fish Audio. Está entrenado con más de 10 millones de horas de audio en aproximadamente 80 idiomas e introduce el control de etiquetas en línea: instrucciones en lenguaje natural integradas directamente en tu guion en cualquier posición, lo que te ofrece una dirección detallada sobre cómo se emite el habla a nivel de palabra o frase.
El modelo es de código abierto en GitHub y HuggingFace, y está disponible a través de la API y la APP de Fish Audio.
Lo que S2 puede hacer en 30 segundos
Las etiquetas en línea de S2 son instrucciones entre corchetes colocadas en cualquier parte del texto:
[whispering] Don't let them hear you.
She set the folder down. [long pause] Then she looked up.
[laughing] I have absolutely no idea what just happened.
Las etiquetas afectan a lo que viene después de ellas. Coloca la etiqueta en el punto exacto donde deba producirse el cambio, no al principio de la frase a menos que sea ahí donde lo quieras.
No estás eligiendo de un menú fijo. Tú escribes la descripción y S2 la interpreta:
[the calm, measured tone of someone who has done this a thousand times]
Please place your hands where I can see them.
[overly cheerful, clearly forcing it]
Everything is completely fine. Totally fine.
Si puedes describírselo a un actor de voz, S2 puede intentarlo.
Etiquetas en línea en Fish Audio S2
Las etiquetas en línea son el mecanismo de control principal en Fish Audio S2. Son instrucciones en lenguaje natural entre [corchetes] que integras directamente en tu guion para dirigir cómo se emite el habla, en cualquier palabra y en cualquier momento.
Sintaxis
Coloca una etiqueta entre [corchetes] inmediatamente antes de la palabra o frase a la que deba afectar. Las etiquetas pueden ir en cualquier lugar: al principio, en medio o al final de una frase.
[whispering] I didn't want to go inside.
I didn't want to go [whispering] inside.
Ambas funcionan. La primera susurra toda la línea. La segunda susurra a partir de "inside". La ubicación define el significado.
Escribe etiquetas en tu idioma
Las etiquetas no tienen por qué estar en inglés. S2 entiende instrucciones en lenguaje natural en 80 idiomas, por lo que puedes escribir etiquetas en el mismo idioma que tu guion.
日本語 (Japonés)
[囁き声で] 誰にも聞かせないで。
[ため息をついて] もう一度やり直そう。
中文 (Chino)
[低声说] 不要让他们听见。
[叹气] 我真的不知道该怎么办了。
español (Español)
[susurrando] No dejes que te escuchen.
[enojado] ¿Cómo pudiste hacer eso?
한국어 (Coreano)
[속삭이며] 아무도 모르게 해줘。
[화나서] 어떻게 그럴 수가 있어。
Se aplica la misma lógica: coloca la etiqueta inmediatamente antes de la palabra o frase a la que deba afectar, en el idioma que te resulte más natural para tu guion.
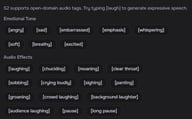
Etiquetas probadas
S2 acepta cualquier descripción en lenguaje natural, pero estas etiquetas producen resultados sólidos de forma constante. Las etiquetas se aplican desde el punto en que aparecen hasta la siguiente etiqueta o el final de la frase.
Respiración y reacciones
Sonidos vocales
Ritmo
Estilo de voz
Emoción
Otros
Descripciones libres
Más allá de la lista de etiquetas anterior, S2 acepta descripciones abiertas. Escribe lo que le dirías a un actor de voz:
[speaking slowly, almost hesitant]
[professional broadcast tone]
[dead tired, end of a very long shift]
[pitch up]
[voice rough from crying, trying to sound normal]
Debido a que S2 está entrenado con descripciones abiertas, las etiquetas nuevas se generalizan bien; no estás limitado a los ejemplos vistos durante el entrenamiento.
Combinación de etiquetas
Encadena etiquetas a lo largo de un pasaje para crear cambios en la interpretación:
[soft voice] I wasn't sure what to say. [long pause] [loud voice] But then it hit me.
Usa etiquetas de reacción entre frases para transiciones naturales:
That was the third time this week. [sigh] I really need to fix that.
Combinar una reacción con una etiqueta de emoción refuerza el sentimiento físicamente:
[sigh] [sad] I just don't know anymore.
Ejemplos reales
Narración de audiolibros
[NARRATOR, low and slow] Chapter Nine. The Last Morning. The apartment felt different that day — smaller, somehow.
SARAH: [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
DANIEL: [long pause, then quietly] Yeah. Thanks.
Pódcast

Today we're looking at something I've spent three months trying to understand.
[chuckling] I kept getting it wrong. My producer will confirm this.
Diálogo de videojuegos
VILLAIN: [calm, almost bored, as if this conversation is beneath them] You came all this way.
VILLAIN: [sudden fury, voice tight] Where is it?
VILLAIN: [composure returning, dangerously quiet] Did you really think that would work?
HERO: [exhausted, but steady] Every time.
Agente de voz

[friendly, warm] Hi — thanks for calling. How can I help you today?
[empathetic, unhurried] I'm sorry to hear that. Let me pull this up.
[confident] Good news — I can see exactly what happened, and I'm going to get this sorted for you right now.
Consejos para obtener los mejores resultados
Las etiquetas en línea de S2 son expresivas, pero cuánto se nota depende de cómo las uses y de con qué voz estés trabajando. Estos consejos se basan en pruebas prácticas.

Combina etiquetas físicas con una etiqueta de emoción. Etiquetas como [panting], [whispering] y [shouting] se registrarán por sí solas, pero el efecto puede parecer plano sin un contexto emocional. Combinarlas con una etiqueta de emoción produce resultados más consistentes y naturales:
[panting] [tired] I've been running for twenty minutes.
[whispering] [scared] Don't move. Don't make a sound.
[shouting] [angry] I told you this would happen!

Sigue siempre una etiqueta descriptiva con texto. Una etiqueta descriptiva como [voice rough from crying, trying to sound normal] necesita una frase para decir; no la dejes sola. La etiqueta dirige la interpretación de lo que sigue; sin texto después, el resultado puede ser impredecible.
✅ [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
❌ [voice rough from crying, trying to sound normal]
Prueba tu voz antes de escribir el guion. Diferentes voces responden a la misma etiqueta con diferente intensidad. Una voz con un registro naturalmente tranquilo mostrará cambios más sutiles que una expresiva. Si una etiqueta no funciona como esperas, prueba con una voz diferente antes de ajustar la etiqueta; a menudo el problema es la voz, no la instrucción.
Empieza por lo sencillo y luego añade capas. Un solo [sigh] o [long pause] bien colocado puede cambiar una frase por completo. Añade más etiquetas solo cuando la versión más sencilla no sea suficiente. El exceso de etiquetas compite entre sí.
Próximamente: elige tu favorito entre múltiples generaciones. S2 permitirá generar varias versiones de la misma frase a la vez, para que puedas comparar y elegir la interpretación que mejor encaje, de forma similar a cómo las herramientas de generación de imágenes permiten seleccionar de un lote. Esto facilitará significativamente el ajuste de la interpretación adecuada sin tener que retocar manualmente las etiquetas cada vez.
Rendimiento de S2 — Resultados de benchmarks
El control en línea de S2 no es solo una característica de experiencia de usuario (UX); también se correlaciona con un sólido rendimiento en benchmarks de voz públicos. Estos benchmarks miden la naturalidad del habla, la precisión de la pronunciación y la capacidad de seguimiento de instrucciones en los sistemas TTS modernos.
En el Audio Turing Test, S2 obtiene una puntuación de 0,515, superando a Seed-TTS en un 24% y a MiniMax-Speech en un 33%. En EmergentTTS-Eval, logra resultados especialmente sólidos en paralingüística (tasa de victoria del 91,61%), lo que refleja directamente la calidad de la ejecución de las etiquetas en línea.
En Seed-TTS Eval, S2 logra la tasa de error de palabras más baja entre todos los modelos evaluados, incluidos los sistemas de código cerrado: Qwen3-TTS (0,77% / 1,24%), MiniMax Speech-02 (0,99% / 1,90%) y Seed-TTS (1,12% / 2,25%).
Fuente: Publicación de lanzamiento de Fish Audio S2 de Shijia Liao, Científico Jefe
80 idiomas
S2 está entrenado con más de 10 millones de horas de audio que abarcan aproximadamente 80 idiomas. En el conjunto de pruebas multilingües de MiniMax que cubre 24 idiomas, S2 logra la mejor tasa de error de palabras en 11 idiomas y la mejor similitud de hablante en 17, superando tanto a MiniMax como a ElevenLabs en la mayor parte del benchmark.
Los idiomas con un sólido rendimiento confirmado incluyen: árabe, cantonés, chino, checo, holandés, inglés, finlandés, francés, alemán, griego, hindi, indonesio, italiano, japonés, coreano, polaco, portugués, rumano, ruso, español, tailandés, turco, ucraniano, vietnamita.
Código abierto
A diferencia de la mayoría de los sistemas comerciales de TTS, Fish Audio S2 es totalmente de código abierto (pesos del modelo, código de ajuste fino y un motor de inferencia basado en SGLang listo para producción), lo que permite a los desarrolladores realizar autohospedaje, ajuste fino y despliegue a escala.
-
GitHub: github.com/fishaudio/fish-speech
-
HuggingFace: huggingface.co/fishaudio/s2-pro
-
Inferencia SGLang: SGLang-Omni
Rendimiento en producción en una sola GPU H200:
-
Factor de tiempo real: 0,195
-
Tiempo hasta el primer audio: ~100ms
-
Rendimiento (throughput): más de 3.000 tokens acústicos/s
Para la clonación de voz a escala, S2 coloca tokens de audio de referencia en el prompt del sistema. La caché KV de SGLang logra una tasa media de aciertos de caché de prefijo del 86,4% cuando se reutiliza la misma voz en varias solicitudes, lo que hace que la sobrecarga de la clonación de voz repetida sea casi insignificante.
Cómo empezar
-
Pruébalo en la APP
playground— fish.audio admite etiquetas en línea de S2 directamente. Coloca[corchetes]en cualquier parte de tu guion y genera. -
Integración a través de la API — Disponible a través de la API de Fish Audio. Consulta la referencia de la API para conocer los endpoints y la autenticación.
-
Autohospeda el modelo — Los pesos y la pila de inferencia son de código abierto en GitHub y HuggingFace.
-
Próximamente: Generación de diálogos con varios hablantes en la APP y la API de Fish Audio.
-
Para una guía completa sobre la sintaxis de las etiquetas en línea, las reglas de colocación y consejos: → Cómo usar las etiquetas en línea de Fish Audio S2
-
Si vienes de S1 y quieres entender cómo se relacionan los dos sistemas: → Etiquetas de emoción de Fish Audio S1 — Guía completa
FAQ
¿Qué son las etiquetas en línea en TTS?
Las etiquetas en línea son instrucciones cortas integradas directamente en un guion de texto a voz para controlar cómo se pronuncia una palabra o frase específica: la entonación, la emoción, el ritmo o la calidad vocal en ese punto exacto. A diferencia de los ajustes de voz globales que se aplican a toda una generación, las etiquetas en línea permiten dirigir momentos individuales dentro de una frase. Fish Audio S2 utiliza [corchetes] para las etiquetas en línea y acepta descripciones en lenguaje natural de forma libre.
¿Qué es Fish Audio S2?
Fish Audio S2 es el modelo TTS de segunda generación de Fish Audio. Admite un control detallado en línea mediante etiquetas de lenguaje natural entre [corchetes] colocadas en cualquier lugar de un guion, y ha sido entrenado con más de 10 millones de horas de audio en aproximadamente 80 idiomas. Es de código abierto en GitHub y HuggingFace, y está disponible a través de la API y la APP~~ playground~~ de Fish Audio.
¿Cómo funcionan las etiquetas en línea en S2?
Coloca una etiqueta entre [corchetes] inmediatamente antes de la palabra o frase a la que deba afectar. Puedes usar etiquetas probadas como [whispering], [sigh] o [long pause], o escribir cualquier descripción en lenguaje natural de forma libre. Las etiquetas se aplican a todo lo que sigue hasta la siguiente etiqueta o el final de la frase.
¿Es Fish Audio S2 de código abierto?
Sí. Los pesos del modelo, el código de ajuste fino y el motor de inferencia basado en SGLang son de código abierto en github.com/fishaudio/fish-speech y huggingface.co/fishaudio/s2-pro
¿Cuántos idiomas admite S2?
S2 está entrenado en aproximadamente 80 idiomas. En un benchmark multilingüe de 24 idiomas, S2 logra la mejor tasa de error de palabras en 11 idiomas y la mejor similitud de hablante en 17, superando a MiniMax y ElevenLabs.
¿Admite S2 la sintaxis de paréntesis () de S1?
No. S2 utiliza [corchetes] de forma nativa. La interfaz web de Fish Audio traduce automáticamente () a [] cuando se selecciona S2, pero si estás usando la API directamente, usa corchetes.
¿Admite S2 diálogos con varios hablantes?
La generación multihablante llegará pronto a la APP y la API de Fish Audio. El modelo lo admite de forma nativa; mantente atento al lanzamiento.
¿Cuál es la diferencia entre Fish Audio S1 y S2?
S1 utiliza un vocabulario fijo de etiquetas de emoción preestablecidas entre (parentheses), colocadas al inicio de las frases. S2 utiliza etiquetas de lenguaje natural de dominio abierto entre [corchetes] que pueden aparecer en cualquier lugar del guion: a mitad de frase, entre palabras o al principio. S2 también acepta descripciones libres en lugar de una lista cerrada de palabras clave, por lo que no estás limitado a emociones predefinidas. Para un desglose completo, consulta la Guía de etiquetas de emoción de Fish Audio S1.
¿Puede Fish Audio S2 reemplazar a SSML?
Para la mayoría de los casos de uso expresivo, sí. Fish Audio S2 puede replicar muchos controles de estilo SSML a través de etiquetas en línea de lenguaje natural; en lugar de marcado XML como <prosody rate=\"slow\">, escribes [speaking slowly] directamente en el guion. Etiquetas como [whispering], [long pause] y [angry] cubren las funciones expresivas de SSML más comunes sin requerir conocimientos de marcado especializado.
¿Son compatibles las etiquetas en línea de Fish Audio S2 con otros sistemas TTS?
No. La sintaxis de las etiquetas en línea en Fish Audio S2 es específica del modelo. Otros sistemas TTS utilizan SSML o sus propios formatos propietarios. Sin embargo, los conceptos expresivos subyacentes (pausas, cambios de tono, señales vocales) se traducen conceptualmente al cambiar de sistema, aunque la sintaxis sea diferente.
Recursos relacionados:

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
Leer más de Sabrina Shu






