AIボイスチェンジャーの使い方 — コンテンツクリエイターのための完全ガイド

AIボイスチェンジャーを使用して、録音した音声を数秒で新しい声に変換する方法を学びましょう。ダウンロードは不要です。クリエイター、ポッドキャスター、ビデオプロデューサー向けのステップバイステップガイドと実際の活用事例を紹介します。
AIボイスチェンジャーは、録音されたあらゆる音声をまったく別の声に変換することができます。そして、コンテンツクリエイターにとって、それはすべてを変える可能性を秘めています。
深夜に疲れ果て、声が枯れた状態でナレーションを録音し、それを朝食前にクリーンで洗練されたナレーターの声に変換することを想像してみてください。あるいは、声優を一人も雇わずに、キャラクターの声でビデオを吹き替える。あるいは、自分一人で、複数の異なる声を使ったポッドキャスト全体を構築する。
これは未来の話ではありません。今日のAIボイスチェンジャーがすでに実現していることです。このガイドでは、ブラウザ上で完全に動作し、2,000,000を超えるコミュニティボイスモデルのライブラリを利用できる Fish Audio の Voice Changer の具体的な使い方を解説します。
→ Fish Audio Voice Changer を無料で試す — ダウンロード不要、クレジットカード不要
AIボイスチェンジャーとは?
AIボイスチェンジャーは、既存のオーディオ録音を取り込み、話し手のタイミング、感情、抑揚を維持しながら、声の特性を完全に別のものに置き換えるツールです。
これは、ピッチシフターやオーディオフィルターとは根本的に異なります。ピッチシフターは機械的に周波数を上げ下げするだけですが、AIボイスチェンジャーは、入力された音声の音色、共鳴、話し方のパターンなど、音響プロファイル全体を分析し、実際の人間の声でトレーニングされたターゲットボイスモデルを使用して出力を再構築します。
その結果、言葉、リズム、感情はあなたのまま、声だけが別人のものになります。
簡単に言えば:AIボイスチェンジャーを使えば、「何を」「どのように」言ったかはそのままに、「誰の声か」だけを変えることができます。
AIボイスチェンジャー vs. ボイスクローニング:何が違うのか?
これら2つの用語はしばしば混同されますが、根本的に異なるワークフローを指します。
AIボイスチェンジャー — すでに録音された音声がある場合に使用します。何をどのように言いたいかは決まっており、単に別の声でその言葉を届けたい場合に最適です。ボイスチェンジャーは既存の録音を取り込み、ターゲットの声に変換します。
ボイスクローニング — 特定の声そのものをキャプチャして複製したい場合に使用します。声のリファレンスオーディオをアップロードすると、AIがその永続的で再利用可能なモデルを構築し、将来のプロジェクト(テキスト読み上げ生成など)でそのモデルを繰り返し使用できるようになります。
最もシンプルな考え方:
-
ボイスチェンジャー = 音声がある。その中の声を変えたい。
-
ボイスクローニング = 何度も使える声のモデルを作りたい。
ほとんどのクリエイターにとって、すでに録音があり、声を変える必要がある場合には、ボイスチェンジャーの方が高速で摩擦の少ないツールです。ボイスクローニングは、今後数十の出力にわたってその声を一貫して登場させる必要がある場合に適した選択肢です。
Fish Audio はその両方を提供しており、同じワークフロー内で連携するように設計されています。
Fish Audio Voice Changer の使い方(ステップバイステップ)
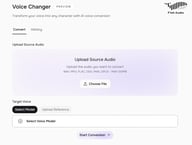
Fish Audio の Voice Changer は完全にブラウザベースです。ソフトウェアのインストール、プラグイン、複雑な設定は一切不要です。以下が完全なワークフローです:
ステップ 1: ボイスチェンジャーを開く
fish.audio/app/voice-changer にアクセスします。オーディオのアップロードエリアがある「Convert」タブが表示されます。
ステップ 2: ソースオーディオをアップロードする
Choose File をクリックし、変換したい録音ファイルをアップロードします。サポートされている形式は、WAV、MP3、FLAC、OGG、M4A、OPUS で、1ファイルあたり最大100MBまでです。
これはあなたの生の入力です。ナレーションのテイク、ポッドキャストのセグメント、ナレーションの下書きなど、一人の声によるオーディオ録音なら何でも構いません。
💡 最良の結果を得るために:BGMやリバーブ、重なった声のない、クリーンなドライオーディオを使用してください。AIは声を変換するのであって、サウンドデザインをクリーンアップするものではありません。ソースオーディオに背景ノイズがある場合は、まず Fish Audio の Audio Separation ツールで処理することを検討してください。
ステップ 3: ターゲットボイスを選択する
Target Voice の下には、2つのオプションがあります:
-
Select Model — 2,000,000を超える Fish Audio のコミュニティボイスモデルのライブラリを閲覧できます。言語、性別、スタイル、またはユースケースでフィルタリングしてください。これは、まったく別の声にするための最も速い方法です。
-
Upload Reference — 特定の声をイメージしていますか?その声のリファレンスオーディオクリップ(最大10分)をアップロードすれば、AIがそれを変換ターゲットとして使用します。これは、Fish Audio を多くの競合他社と差別化する機能です。(アップロードするリファレンスオーディオの権利を所有していることを確認してください。下記の責任ある利用に関する注記を参照してください。)
ステップ 4: 変換を開始する
Start Conversion をクリックします。AIがファイルを処理し、変換された出力を生成します。
ステップ 5: オーディオをダウンロードする
変換が完了したら、新しいオーディオを MP3 ファイルとしてダウンロードします。これで、ビデオエディター、ポッドキャストソフトウェア、またはDAWに直接取り込む準備が整いました。
変換履歴は History タブに保存されるため、最初からやり直すことなく、以前のジョブを確認したり再ダウンロードしたりできます。
→ Fish Audio Voice Changer を開いて、最初のファイルを変換する
⚠️ 責任ある利用について:「Upload Reference」オプションを使用する場合、その声の権利を所有しているか、使用するための明示的な許可を得ている必要があります。本人の同意なしに他人の録音をアップロードしないでください。 Fish Audio のプラットフォームは、自身の声や適切にライセンスされたオーディオを扱うクリエイターのために構築されています。なりすましや欺瞞的なコンテンツの作成を含む、音声変換技術の悪用は、 Fish Audio の利用規約で禁止されており、適用法に違反する可能性があります。
料金はいくらですか?
Fish Audio Voice Changer は、無料プランを含むすべてのプランで利用可能です。
無料アカウントには、毎月のクレジット割り当てが含まれています。ボイスチェンジャーは 1分あたり3,000クレジット、1秒単位で課金 されます。つまり、30秒のクリップなら1,500クレジット、60秒のクリップなら3,000クレジットとなります。
複数のエピソードの変換、長尺のナレーション、大量のビデオ吹き替えなど、より大ボリュームのワークフローの場合は、有料プランをご利用いただくことで、大幅に多くのクレジットを利用できるようになります。現在のプランの詳細については、 Fish Audio の料金プラン をご覧ください。
コンテンツクリエイター向けの4つの実用的な活用事例

1. YouTubeのナレーション:録り直さずにミスを修正
すべてのYouTuberが知っている感覚があります。内容は完璧、テンポも良い、しっかり録音できたはずなのに、その日の声が平坦だったり、鼻声だったり、あるいは何かが違っていたりする。これまでは、別の録音セッションをスケジュールするのが解決策でした。新しい解決策はボイスチェンジャーです。
既存のオーディオを Fish Audio Voice Changer にかけ、ブランドの声に合ったモデルを選択して変換します。出力は、あなた自身の正確なタイミングと伝え方(すべての間、すべての強調)を維持したまま、よりクリーンで一貫した声になります。
これはまた、ほとんどのクリエイターが考えたことのない、意図的なプリプロダクション・ワークフローを可能にします。後で変換することを前提に、すべてのスクラッチトラック(仮録音)を素早く自由に録音するのです。声の状態を心配するのをやめ、コンテンツの中身に集中し始めることができます。ボイスチェンジャーは単なる修正ツールではなく、制作ツールになります。
特定のペルソナやキャラクターボイスを持つチャンネルの場合、ボイスチェンジャーを使用することで、録音条件に関係なく、すべてのアップロードで一貫したサウンドを維持できます。
2. ポッドキャスト制作:全エピソードで一貫したブランドボイス
ポッドキャストのリスナーはオーディオの一貫性に敏感です。第1話では洗練された声なのに、第47話では疲れた声をしているホストは、リスナーの信頼を徐々に損なう微妙な摩擦を生みます。
ボイスチェンジャーは、録音当日のあなたの声の状態に関係なく、各エピソードのオーディオを一貫したターゲットボイスモデル(あなたの「放送用ボイス」)に変換できるようにすることで、この問題を解決します。その結果、バックカタログ全体を通して均一なリスニング体験を提供できます。
物語形式のポッドキャストやオーディオドラマの場合、ユースケースはさらに広がります。一人のクリエイターが脚本のすべてのキャラクターを演じ、それぞれのキャラクターのセリフを異なるボイスモデルに変換できます。キャスティング予算ゼロで、複数のキャストを実現できるのです。
3. ビデオの吹き替え:録り直しなしで声を入れ替え
ビデオの声を別の声に入れ替える「吹き替え」は、伝統的に録音スタジオの予約、声優の雇用、そして同期作業に何時間も費やす必要がありました。AIボイスチェンジャーは、そのワークフロー全体を数分に短縮します。
ビデオに合わせて自分の声でスクラッチトラックを録音します。次に、 Fish Audio Voice Changer を使用してターゲットの声に変換します。タイミングは元の話し方に固定されたままなので、同期は自動的に維持されます。
これは特にローカライズ(多言語化)のワークフローに有用です。一度録音すれば、複数のキャラクターボイスや地域のトーンに変換できます。スクリプト用の Fish Audio Text to Speech や、既存のオーディオトラックを分離するための Audio Separation と組み合わせれば、一つのプラットフォームで完全な吹き替えパイプラインが完成します。
4. プライバシーとペルソナの構築
すべてのクリエイターが自分の本当の声をインターネットに出したいわけではありません。プライバシーのため、ペルソナ構築のため、あるいは単に自分が作り上げたキャラクターが自分とは異なる声を持っているためです。
ボイスチェンジャーは、クリエイターとペルソナのクリーンな分離をサポートします。自分の声で自然に録音し、本物の伝え方やエネルギーをキャプチャした後、ポストプロダクションでペルソナの声に変換します。あなたの本当の声が最終的なコンテンツに現れることはありません。パフォーマンスは本物のまま、アイデンティティはプライベートに保たれます。
Fish Audio Voice Changer が他と違う理由
2,000,000以上のボイスモデル vs. その他すべて
Fish Audio のボイスモデルライブラリを主要な代替サービスと比較すると以下のようになります:
| Fish Audio | ElevenLabs | Kits.AI | |
|---|---|---|---|
| ボイスモデルライブラリ | 2,000,000以上 | 10,000以上 | 数百(音楽特化) |
| ターゲットとして参照音声をアップロード | ✅ | ✅ | ❌ |
| 主なユースケース | 一般的なコンテンツ制作 | 一般的なコンテンツ制作 | 音楽制作 |
| ダウンロード不要 | ✅ | ✅ | ✅ |
| モデル品質ベンチマーク | S2 Pro (公開データ) | 利用可能 | 未公表 |
データは2026年4月現在のものです。変更される可能性があるため、各プロバイダーのウェブサイトで現在のプランを確認してください。
Fish Audio のコミュニティモデルライブラリの規模は、単なるわずかな差ではありません。それは別カテゴリーの存在です。何百もの言語、アクセント、スタイル、キャラクターにわたる200万の声があれば、厳選された短いリストから選ぶのではなく、真のカタログから検索していることになります。
あらゆる音声をターゲットとしてアップロード可能
ほとんどのAIボイスチェンジャーは固定されたライブラリを提供し、そこから選ぶよう求めてきます。 Fish Audio の Upload Reference 機能はそのモデルを逆転させます。あなたが声を持ち込み、AIがそれに変換します。
つまり、ブランドに合うトーン、開発中のキャラクター、どこかで聞いた真似したいスタイルなど、特定の声をイメージしている場合、ライブラリにあるものに制限されることはありません。あなたがターゲットを設定するのです。
Fish Audio S2 Pro による強力なパフォーマンス
内部で動作しているモデルは Fish Audio S2 Pro です。これは、Seed-TTS ベンチマーク評価において、クローズドソースの競合他社を含むすべてのテスト済みシステムを上回り、最低の単語誤り率(Word Error Rate)を達成したのと同じモデルです。オーディオ・チューリング・テストでは、S2 Pro は 0.515 を記録し、Seed-TTS を 24%、MiniMax-Speech を 33% 上回りました。
技術的な詳細については、 Fish Audio S2 技術レポート が arXiv で公開されています。
これが実際に何を意味するかというと、変換されたオーディオが自然に聞こえるということです。この変換では、感情のニュアンス(緊急性を持って伝えられた文章と、落ち着いて伝えられた同じ文章の違いなど)が維持されます。これは、低品質なモデルでは完全に平坦化されてしまう部分です。
完全なオーディオワークフローの一部として
Voice Changer は単独で存在しているのではありません。 Fish Audio のフルプラットフォームには以下が含まれます:
-
Voice Cloning — 短いサンプルから再利用可能なボイスモデルを構築
-
Text to Speech — 任意のスクリプトから任意の声で音声を生成
-
Story Studio — 複数の声を使用した物語形式のオーディオ制作
-
Audio Separation — 任意のオーディオファイルからボーカルを分離
-
Speech to Text — 高精度な音声文字起こし
スイート内のすべてのツールは互いに連携しています。一般的な制作ワークフローは次のようになります: Audio Separation(ボーカルを分離) → Voice Changer(声を変換) → ダウンロードして同期。プラットフォームを切り替えたり、ファイル形式をいじくり回したりする必要はありません。
今後の展望
Fish Audio Voice Changer はすでに公開されていますが、さらに拡張を続けています。Voice Changer の API アクセスが開発中であり、これにより開発者や制作チームは音声変換を自社のツール、パイプライン、アプリケーションに直接統合できるようになります。
自動吹き替えパイプライン、コンテンツローカライゼーションツール、音声駆動型アプリケーションなど、プログラムによる音声変換を利用できるものを構築している場合は、 Fish Audio のウィークリーアップデート で情報をチェックしてください。
よくある質問
Fish Audio Voice Changerは無料で利用できますか?
ソフトウェアをダウンロードする必要がありますか?
どのようなオーディオ形式をアップロードできますか?
変換後のオーディオ出力の形式は何ですか?
Voice ChangerとVoice Cloningの違いは何ですか?
自分の声をターゲットとしてアップロードできますか?
試してみる準備はできましたか?

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
Sabrina Shuの他の記事を読む





