Text to Speech com Múltiplas Vozes — Guia Completo Multispeaker (Fish Audio)

O TTS de voz única soa monótono para diálogos, audiolivros e podcasts. Este guia mostra como encontrar e organizar vozes no Fish Audio e, em seguida, usar o recurso multispeaker no TTS e no Story Studio para produzir áudio natural com vários personagens — sem os fluxos de trabalho tradicionais de gravação de voz.
Março de 2026 | O Fish Audio Multispeaker TTS já está disponível no S2 Pro
Sumário
- O que é o Text to Speech Multispeaker?
- Passo 1 — Encontre as Vozes Certas com o Discovery
- Passo 2 — Multispeaker no Text to Speech
- Passo 3 — Multispeaker no Story Studio
- TTS vs Story Studio — Qual Você Deve Usar?
- Casos de Uso — O que Você Pode Criar com o TTS Multispeaker?
- Do Roteiro ao Áudio — Em uma Única Sessão
- Perguntas Frequentes Sobre o TTS Multispeaker
Most text-to-speech tools give you one voice. One narrator. One tone, from start to finish. For a single-speaker explainer, that works fine. But the moment your script involves two characters talking, a host and a guest, or a story with distinct roles — a single voice turns dialogue into a flat, monotonous read-through. Listeners disengage fast.
O text to speech com múltiplas vozes resolve isso. Atribua uma voz de IA diferente para cada falante, controle o tempo entre eles, e o resultado é uma conversa que realmente soa como uma. O Fish Audio funciona como um gerador completo de diálogos text to speech — cobrindo tudo, desde a descoberta de vozes até exportações de múltiplos capítulos. Este guia orienta você por todo o fluxo de trabalho: como descobrir e organizar vozes, como usar o multispeaker na ferramenta Text to Speech para conteúdos curtos e como escalar para produções completas no Story Studio.
O que é o Text to Speech Multispeaker?
O text to speech multispeaker é um fluxo de trabalho de TTS onde diferentes segmentos de um roteiro são atribuídos a diferentes vozes de IA — cada uma com seu próprio tom, gênero, idade e estilo de fala — e então gerados como uma única saída de áudio contínua.
As ferramentas tradicionais de TTS são construídas em torno de um modelo de narração única: uma voz, uma entrada de texto, um arquivo de áudio. Esse design funciona para narração de audiolivros com um único narrador, locuções ou anúncios. Ele falha totalmente para qualquer coisa que envolva diálogo. Para produzir uma conversa de dois personagens com ferramentas antigas, você teria que gerar cada falante separadamente e, em seguida, unir manualmente o áudio em um editor — ajustando o tempo, combinando os níveis de volume e esperando que as transições não pareçam duas gravações diferentes.
O problema não são apenas as etapas extras. É que o tempo entre os falantes é quase impossível de acertar sem controles dedicados. Uma conversa real tem ritmo: um compasso de silêncio antes de uma resposta, uma leve sobreposição quando alguém interrompe, uma pausa mais longa antes de uma resposta difícil. Sem o controle preciso sobre os intervalos entre os falantes, até mesmo um diálogo bem escalado soa robótico.
As ferramentas de TTS multispeaker resolvem ambos os problemas. Cada falante recebe sua própria voz e seu próprio bloco de texto. Os intervalos entre os falantes são ajustáveis. A saída final é um único arquivo de áudio coerente — com o tempo já configurado.
O text to speech multispeaker permite que você:
- Atribua uma voz de IA diferente para cada falante em um roteiro
- Controle o tempo e a pausa entre cada falante
- Gere um diálogo inteiro como um único arquivo de áudio contínuo
- Escale de uma troca de dois personagens para um elenco completo — sem exportações adicionais ou edição manual
Passo 1 — Encontre as Vozes Certas com o Discovery
Antes de construir um projeto multispeaker, você precisa de vozes. A página Discovery do Fish Audio é onde você as encontra — e com milhares de vozes na biblioteca, as ferramentas de filtragem são fundamentais.
Acesse fish.audio/app/discovery/.
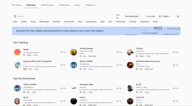
Pesquisa e Filtros
A página Discovery abre com uma barra de pesquisa, tags de filtro rápido na linha superior e controles de ordenação e idioma à direita.
Pesquise por nome se você já souber o que está procurando. Ordene por Recomendados ou Tendências para descobrir o que está funcionando para outros criadores. O filtro de Idioma filtra toda a biblioteca para vozes treinadas no seu idioma de destino.
As tags de filtro rápido na linha superior cobrem os atributos mais comuns — Masculino, Feminino, Jovem, Meia-idade, Narração, Redes Sociais, Profundo, Suave, Profissional, Dramático, Misterioso, Anime — e você pode combiná-las. Selecionar Feminino + Jovem + Narração estreitará imediatamente os resultados para vozes que se encaixam nesse perfil.

Para mais controle, abra o Painel de filtros (o ícone de controles deslizantes no canto superior direito). Isso oferece:
- Idiomas — restringir a um idioma específico, com correspondência multilíngue
- Tags — tags de formato livre adicionadas pelos criadores das vozes
- Gênero — Masculino, Feminino, Neutro
- Idade — Jovem, Meia-idade, Idoso
- Caso de Uso — Conversacional, Narração, Voz de Personagem, Redes Sociais, Educacional, Anúncio e mais
- Qualidades da Voz — Profunda, Baixa, Média, Alta, Suave, Brilhante e mais de 48 descritores adicionais
Para um projeto multispeaker, os filtros de Caso de Uso e Qualidades da Voz são especialmente úteis. Se você estiver construindo um diálogo estilo podcast, pode querer uma voz Conversacional + Suave e uma voz de Narração + Profunda — distintas o suficiente para que os ouvintes possam diferenciá-las sem precisar ver a transcrição.
Curtir, Favoritar e Salvar em uma Coleção
Quando você encontra uma voz que deseja revisitar, tem algumas maneiras de salvá-la. O ícone de coração em cada cartão de voz nos resultados da pesquisa é um Curtir rápido — ele adiciona a voz à sua aba Curtidas para referência posterior.
Para um salvamento mais definitivo, abra a página de detalhes da voz e clique em Favoritar. As vozes Favoritadas aparecem na aba Favoritos, separadas das suas curtidas, e são acessíveis diretamente do seletor de voz tanto no TTS quanto no Story Studio.
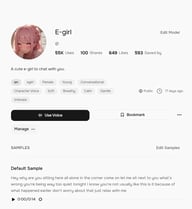
Para organização em nível de projeto, as Coleções são a opção mais poderosa. Clique em Coleções na navegação superior e depois em Criar Coleção para configurar um grupo nomeado — por exemplo, "Uso em Podcast" ou "Projeto de Audiolivro A". Dê um título e descrição e clique em Criar.

Para adicionar uma voz a uma coleção, abra a página de detalhes da voz, clique no menu de três pontos (⋯) ao lado do botão Favoritar e selecione Adicionar à Coleção. Se você já criou uma coleção, ela aparecerá no menu suspenso — um clique adiciona a voz.
O benefício vem quando você está dentro do TTS ou do Story Studio. Quando você abre o painel Selecionar Voz, suas coleções aparecem como abas no topo — logo ao lado de Usadas Recentemente, Explorar, Vozes Padrão, Minhas Vozes e Favoritos. Em vez de pesquisar do zero a cada sessão, as vozes do seu projeto já estão agrupadas e prontas.
Passo 2 — Multispeaker no Text to Speech
A ferramenta Text to Speech do Fish Audio suporta múltiplos falantes em uma única geração. É a ferramenta certa para conteúdos de curta a média duração — trechos de diálogo, anúncios, introduções curtas de podcast, roteiros de demonstração e qualquer coisa onde você precise de uma saída rápida e polida sem gerenciamento de capítulos. Se você ainda não encontrou suas vozes, comece navegando na biblioteca Discovery primeiro.
Acesse fish.audio/app/text-to-speech/.
Configure seu Primeiro Falante
Ao abrir o TTS, você verá um único bloco de texto com um seletor de voz no topo. Clique no nome da voz para abrir o painel Selecionar Voz e escolha seu primeiro falante. Digite ou cole as falas do primeiro falante no bloco de texto.
Você também pode usar tags de emoção inline para moldar a entrega — [triste], [ênfase], [animado] — colocadas diretamente no texto antes das palavras que elas devem afetar.
Adicione Mais Falantes
Clique em + Adicionar Falante abaixo do primeiro bloco de texto. Um novo bloco aparecerá, com seu próprio seletor de voz independente. Escolha uma voz diferente para este falante, insira suas falas, e os dois blocos serão gerados como um único arquivo de áudio contínuo — na ordem em que aparecem na tela.
Não há limite superior para o número de falantes que você pode adicionar. Cada bloco é independente: voz diferente, texto diferente, tags de emoção diferentes, se necessário. Na prática, a maioria dos projetos de diálogo funciona bem com 2 a 4 vozes distintas — variedade suficiente para ser claro, sem se tornar difícil de acompanhar. No painel direito, você pode ajustar Volume, Velocidade, Normalização de Loudness e Normalização de Texto (que melhora a precisão de leitura para números, moedas e textos formatados similares) antes de gerar.
Limite de Caracteres e Quando Mudar para o Story Studio
Fique de olho no contador de caracteres na parte inferior da tela. O limite depende do seu plano — verifique os limites de preços e planos do Fish Audio para a franquia específica do seu nível. Para conteúdos curtos e médios, o TTS é o fluxo de trabalho mais rápido e simples. Mas se você estiver trabalhando em algo mais longo — um capítulo inteiro de audiolivro, um podcast de vários segmentos, um roteiro de diálogo de jogo — é aí que o Story Studio oferece as ferramentas que você realmente precisa.
Passo 3 — Multispeaker no Story Studio
O Story Studio foi construído para produção de áudio de formato longo. Enquanto o TTS é otimizado para geração rápida, o Story Studio oferece um ambiente estruturado para sequenciar múltiplas vozes bloco por bloco — com controle preciso sobre o tempo entre falantes e organização de capítulos para projetos complexos. Cada bloco gera independentemente com sua própria voz atribuída, e a exportação final os une em um único arquivo contínuo. Acesse fish.audio/app/story-studio/.
Crie um Novo Projeto
Clique em + Projeto na tela inicial do Story Studio. O diálogo Criar projeto abre com estas configurações:
- Nome do Projeto — dê um nome ao seu projeto
- Voz Padrão — a voz atribuída aos novos blocos por padrão (você pode alterá-la por bloco)
- Modelo de Fala — atualmente S2 Pro (mais recente)
- Normalização de Texto — quando ativada, melhora a precisão da leitura para números, moedas, datas e textos similares
- Normalização de Loudness — normaliza os níveis de volume entre os blocos para uma saída consistente
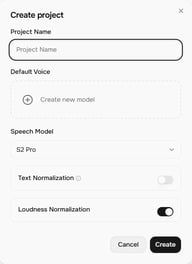
Clique em Criar para abrir o editor de projeto.
Adicione Blocos e Troque de Vozes
Seu projeto abre com um capítulo padrão e um primeiro bloco de texto já no lugar. A voz do primeiro falante é mostrada como um avatar colorido à esquerda de cada bloco.
Para adicionar a fala de um novo falante, clique no botão + abaixo de qualquer bloco existente. Um novo bloco aparecerá. Clique no avatar de voz colorido no lado esquerdo do novo bloco para abrir o painel Selecionar Voz e atribuir uma voz diferente. Digite a fala do segundo falante no bloco.
Repita isso para cada interação no seu roteiro. Cada bloco é a vez de um único falante. O painel do lado direito mostra as Vozes usadas no projeto — uma lista em tempo real de cada voz atualmente atribuída em todos os blocos, para que você possa acompanhar seu elenco rapidamente.
Ajuste Fino da Pausa Entre os Falantes
Entre cada par de blocos, você verá uma pequena bolha de tempo mostrando o intervalo atual — por exemplo, 0.35s. Clique nela para ajustar a duração da pausa entre esse par específico de falantes.
Este é um dos recursos mais importantes do Story Studio para o realismo do diálogo. Uma conversa humana não é uma série de falas perfeitamente seguidas. Um compasso de silêncio antes de uma resposta sinaliza tempo de processamento. Uma pausa mais longa antes de uma resposta emocional adiciona peso. Acertar esses intervalos é a diferença entre um áudio que soa produzido e um áudio que soa real. Mesmo um ajuste de 0,2–0,5s pode mudar notavelmente o quão natural uma conversa parece — vale a pena ajustar cada troca individualmente em vez de deixar todos os intervalos no padrão. Ajuste cada pausa entre blocos individualmente para combinar com o ritmo da cena.
Adicione Capítulos para Projetos Longos
No lado esquerdo do editor, você verá o painel de Capítulos. Por padrão, todo projeto começa com um único "Capítulo Padrão". Clique em + para adicionar um novo capítulo.
Os capítulos permitem que você divida projetos longos em seções navegáveis — um capítulo por seção de audiolivro, um por segmento de podcast ou um por cena em um roteiro de jogo. Cada capítulo tem sua própria sequência de blocos e pode ser trabalhado de forma independente. A exportação final combina todos os capítulos em uma única saída, em ordem.
Para qualquer coisa além de algumas centenas de palavras de diálogo, os capítulos são a forma de manter um projeto no Story Studio organizado e editável.
TTS vs Story Studio — Qual Você Deve Usar?
| Text to Speech | Story Studio | |
|---|---|---|
| Método Multispeaker | Nativo (nível de modelo S2 Pro) | Geração sequencial de blocos |
| Limite de caracteres | Dependente do plano | Sem limite (multi-capítulo) |
| Número de falantes | Até 5 | Ilimitado |
| Controle de pausa entre falantes | ❌ | ✅ Preciso, por bloco |
| Gerenciamento de capítulos | ❌ | ✅ |
| Visualização de linha do tempo | ❌ | ✅ |
| Melhor para | Diálogos curtos, anúncios, demos | Audiolivros, podcasts, roteiros de jogos, produções longas |
A principal diferença técnica: O TTS usa a capacidade nativa multispeaker do S2 Pro — múltiplos falantes são lidados no nível do modelo em uma única geração. O Story Studio atinge a saída multispeaker sequenciando blocos gerados separadamente, cada um com sua própria voz atribuída, em um arquivo contínuo.
Se você estiver gerando um anúncio de 30 segundos com dois falantes ou um clipe curto de diálogo, comece no TTS — é mais rápido e não requer configuração de projeto. Se o seu roteiro for mais longo, envolver mais do que algumas trocas ou precisar de tempo preciso entre os falantes, abra o Story Studio.
Casos de Uso — O que Você Pode Criar com o TTS Multispeaker?
Audiolivros com Múltiplos Personagens
Audiolivros com um único narrador funcionam bem para não-ficção. Para ficção com diálogos, uma única voz lendo todos os personagens torna-se difícil de acompanhar. Com o TTS multispeaker, cada personagem em uma cena recebe sua própria voz — uma voz mais profunda e velha para um personagem, uma voz mais jovem e energética para outro. A estrutura de capítulos do Story Studio mapeia diretamente os capítulos do livro, tornando prático produzir títulos de longa duração sem os fluxos de trabalho tradicionais de elenco e gravação.
Diálogo Estilo Podcast
Formatos de podcast com dois apresentadores são uma das estruturas de áudio mais reconhecidas que existem. Com um gerador de voz de IA multispeaker para diálogos, você pode produzir esse formato a partir de um roteiro escrito — uma voz para cada apresentador, com pausas controladas que simulam a alternância natural de falas. Isso é particularmente útil para criadores de conteúdo que desejam produzir conteúdo de áudio regular sem agendar sessões de gravação.
E-Learning e Conteúdo de Treinamento
O conteúdo instrucional torna-se significativamente mais envolvente quando entregue como uma conversa em vez de um monólogo. Uma troca professor-aluno, um cenário guiado ou um formato de perguntas e respostas podem ser roteirizados e produzidos com duas ou mais vozes — ajudando os alunos a processar informações através do diálogo em vez da narração passiva.
Diálogos de Jogos e Vozes de Personagens
Roteiros de jogos geralmente têm centenas ou milhares de linhas distribuídas entre vários personagens. Usando o Story Studio como um gerador de voz para múltiplos personagens, desenvolvedores de jogos e designers narrativos podem produzir diálogos dublados para prototipagem, demos ou produção total — com cada NPC recebendo uma voz consistente em cada linha que fala, sem os fluxos de trabalho tradicionais de gravação de voz.
Do Roteiro ao Áudio — Em uma Única Sessão
Produzir áudio com vários personagens costumava significar contratar dubladores, coordenar sessões de gravação e passar horas na pós-produção para unir os takes. Com o TTS multispeaker, todo esse fluxo de trabalho se resume a uma única sessão: encontre suas vozes no Discovery, organize-as em uma Coleção, construa seu roteiro bloco por bloco e exporte.
Para conteúdos curtos, o Text to Speech resolve em minutos. Para produções mais longas — audiolivros, séries de podcasts, diálogos de jogos — o Story Studio oferece a estrutura e o controle de tempo para produzir algo que realmente pareça ter sido interpretado.
🎧 Crie seu primeiro diálogo de 2 falantes em menos de 2 minutos →
🎙 Transforme seu roteiro em um audiolivro com elenco completo usando vozes de IA →

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






