Мы провели слепое тестирование нашей TTS против всех основных конкурентов. Вот результаты.

Мы провели слепое тестирование нашей TTS против всех основных конкурентов. Вот результаты.
Fish Audio провела 10-дневное слепое A/B-тестирование на реальном трафике, столкнув Fish Audio S2 Pro и S1 с ElevenLabs, Inworld и MiniMax. Было собрано более 5000 пар предпочтений от реальных пользователей, которые не знали, какой провайдер сгенерировал то или иное аудио.
Кратко: Результаты
Fish Audio S2 Pro заняла первое место в общем зачете с показателем Брэдли-Терри (BT) 3.07, что почти в 1.7 раза выше, чем у следующей лучшей модели. Наша более ранняя модель, Fish Audio S1 (BT 1.86), также превзошла всех сторонних провайдеров в совокупности.
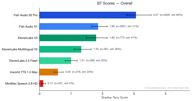
| Ранг | Модель | Показатель BT | Процент побед | Выборка |
|---|---|---|---|---|
| 1 | Fish Audio S2 Pro | 3.07 | 65.7% | 4,573 |
| 2 | Fish Audio S1 | 1.86 | 41.0% | 3,560 |
| 3 | ElevenLabs V3 | 1.80 | 40.6% | 766 |
| 4 | ElevenLabs Multilingual V2 | 1.35 | 36.2% | 359 |
| 5 | ElevenLabs 2.5 Flash | 1.00 | 29.8% | 364 |
| 6 | Inworld TTS 1.5 Max | 0.59 | 20.1% | 373 |
| 7 | MiniMax Speech 2.8 HD | 0.12 | 5.0% | 201 |
Ключевые результаты очных поединков:
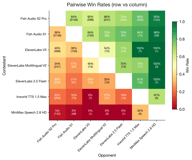
- Fish S2 Pro побеждает ElevenLabs V3 в 60% против 40% случаев (581 пара)
- Fish S2 Pro побеждает Inworld в 80% против 20% случаев (261 пара)
- Fish S2 Pro побеждает MiniMax в 95% против 5% случаев (142 пара)
- Fish S1 побеждает ElevenLabs V3 в 64% против 36% случаев (150 пар)
Почему мы это сделали
Проблема традиционных метрик
MOS (Mean Opinion Score) остается стандартом де-факто для оценки TTS, но у него есть серьезные недостатки. Условия тестирования редко раскрываются — длина образцов, демография слушателей, среда воспроизведения и инструкции по оценке варьируются от исследования к исследованию, что делает сравнение статей бессмысленным. В то же время WER/CER (частота ошибок в словах/символах) могут быть контрпродуктивными в качестве цели оптимизации: стремление к чрезмерно низкому WER часто заставляет модель генерировать гипер-артикулированную, роботизированную речь, которая приносит естественность и просодию в жертву разборчивости. Модель, которая иногда бормочет, как настоящий человек, на самом деле может звучать лучше, чем та, которая идеально произносит каждый слог.
Проблема существующих таблиц лидеров
Публичные лидерборды, такие как TTS-Arena-V2 и Artificial Analysis, оценивают модели на коротких, простых предложениях — обычно это одна строка диалога или краткое повествование. Это не позволяет уловить сложность реального использования TTS: длинный контент, диалоги с несколькими участниками, экспрессивные теги просодии и многоязычный текст.
Помимо методологии, существуют опасения относительно честности. В TTS-Arena-V2 наблюдались проблемы с утечкой аудио-заголовков, когда метаданные в аудиофайле могли раскрыть личность провайдера, нарушая принцип слепой оценки. Мы также знаем, что широко распространена манипуляция рейтингами (gaming): провайдеры оптимизируют модели специально под предложения из бенчмарков, отправляют отобранные вручную чекпоинты моделей или искусственно завышают рейтинги через скоординированное голосование. Эти таблицы лидеров стали маркетинговыми инструментами, а не надежными индикаторами качества.
Что нам было нужно на самом деле
Нам требовался надежный внутренний сигнал вознаграждения — объективная мера того, «какой результат TTS на самом деле предпочитают реальные пользователи», которой мы могли бы доверять при принятии решений по разработке моделей. Не цифра из научной статьи, не место в манипулируемом рейтинге, а непрерывный поток честных данных о предпочтениях пользователей, совершающих реальный выбор.
Поэтому мы встроили конвейер слепой оценки непосредственно в нашу рабочую платформу.
Дизайн эксперимента
Слепое парное сравнение
Студия Fish Audio предлагает пользователям две аудиоверсии рядом для каждой задачи TTS. Каждая версия независимо имеет 10% шанс быть незаметно направленной стороннему конкуренту вместо стандартного бэкенда Fish Audio. Тот же текст, тот же референсный голос, тот же интерфейс — пользователь понятия не имеет, какой провайдер сгенерировал аудио.
Эксперимент проводился в течение 10 дней (с 26 марта по 5 апреля 2026 года). Было собрано более 71 000 парных групп, из которых 5 098 содержали сравнения между разными провайдерами, соответствующие нашим критериям качества.
Что считается «победой»
Мы используем строгий поведенческий сигнал, а не субъективную оценку:
- Пользователь должен воспроизвести обе версии как минимум по 2 раза каждую — подтверждая, что он действительно сравнил обе.
- Скачивается ровно одна версия — она и становится победителем.
Этот сигнал «послушал-затем-скачал» гораздо надежнее, чем звездные рейтинги или опросы с принудительным выбором. Пользователи принимают реальные решения относительно аудио, которое они действительно будут использовать.
Состав пользователей
В эксперименте участвовало примерно 70% новых пользователей и 30% вернувшихся. Такой состав может вносить небольшое смещение в пользу Fish Audio (вернувшиеся пользователи уже знакомы с нашей платформой), но также гарантирует, что мы фиксируем подлинные предпочтения от первого впечатления большинства участников.
Выбор голосов
Для эксперимента мы использовали 500 самых популярных публичных голосов платформы. Каждый голос был заранее клонирован в системы сторонних провайдеров, что гарантировало идентичность референсного голоса с обеих сторон. Соответствия ID голосов хранятся в специальных JSON-файлах, которые служат единственным источником истины для маршрутизации.
Протестированные провайдеры и модели
| Провайдер | Модель | Цель маршрутизации |
|---|---|---|
| Fish Audio | S2 Pro (последняя) | fish:s2-pro |
| Fish Audio | S1 (предыдущее поколение) | fish:s1 |
| ElevenLabs | V3 | elevenlabs:v3 |
| ElevenLabs | 2.5 Flash | elevenlabs:2.5-flash |
| ElevenLabs | Multilingual V2 | elevenlabs:2-multilingual |
| Inworld | TTS 1.5 Max | inworld:inworld-tts-1.5-max |
| MiniMax | Speech 2.8 HD | minimax:speech-2.8-hd |
Охват оценки и поддержка тегов
Не все провайдеры поддерживают одинаковый набор функций. Fish Audio S2 Pro поддерживает богатые теги просодии (например, [laughs], [sighs]) и теги диктора (<|speaker:N|>) для многопользовательского контента. Это важно, так как наш реальный трафик естественным образом включает размеченный текст.
- ElevenLabs V3 получила наиболее полную оценку — модель поддерживает произвольные теги после нормализации в форму со скобками, поэтому она подходила практически для всех запросов независимо от содержания.
- ElevenLabs 2.5 Flash и Multilingual V2 — мы отправляли в эти модели только текстовые запросы (без тегов).
- Inworld — только простой текст и ограничение форматом вывода
mp3, что еще больше сузило объем подходящего трафика. - MiniMax — принимала теги междометий (
(laughs),(sighs)и т. д.), но отклоняла другие типы тегов. Из-за стабильно плохих результатов предпочтений пользователей эксперимент был остановлен досрочно, чтобы избежать дальнейшего ухудшения пользовательского опыта.
Система маршрутизации оценивает каждого альтернативного провайдера на соответствие характеристикам текущего запроса (язык, теги, формат, несколько референсных голосов). Только поддерживаемые альтернативы становятся кандидатами, и одна из них выбирается путем взвешенного случайного выбора. Если единственной подходящей альтернативой является сравнение Fish-vs-Fish (S1 против S2 Pro), эффективная вероятность выборки снижается до 1/10 от базовой ставки, чтобы приоритизировать сбор данных между разными провайдерами.
Во что нам это обошлось
Такие эксперименты не бесплатны. API сторонних TTS обходятся дорого при больших масштабах:
- ElevenLabs: потрачено более $1,500 на вызовы API.
- MiniMax: потрачено $330 (остановлено досрочно из-за плохой производительности).
- Inworld: потрачено $170.

Статистическая методология
Модель Брэдли-Терри
Чистые показатели побед могут вводить в заблуждение, когда разные модели сталкиваются с разными противниками с разной частотой. Модель Брэдли-Терри решает эту проблему, вычисляя глобальный показатель силы на основе данных парных сравнений. Она итеративно оценивает латентный параметр «силы» каждой модели так, чтобы предсказанная вероятность победы между любыми двумя моделями соответствовала наблюдаемым данным.
Для двух моделей и с показателями BT и :
Наша реализация выполняет до 500 итераций с допуском сходимости , нормализуя показатели с использованием среднего геометрического на каждом шаге.
Доверительные интервалы
Мы приводим 95% бутстрап-доверительные интервалы, вычисленные на основе 200 повторных выборок данных о парах предпочтений. Каждая выборка извлекает пар с возвращением из исходных пар, после чего заново запускается полный расчет BT. 2.5-й и 97.5-й процентили бутстрап-показателей формируют границы доверительного интервала.
Для показателей побед по каждому бэкенду мы используем интервалы Вилсона, которые обеспечивают лучшее покрытие, чем интервалы нормальной аппроксимации при экстремальных значениях побед.
Результаты по языкам
Языки на основе латиницы (английский, испанский, французский, немецкий и др.)
Языки с латинским алфавитом представляют собой крупнейший сегмент — 4 173 пары предпочтений.
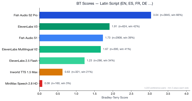
Fish S2 Pro лидирует с показателем 3.05. Примечательно, что ElevenLabs V3 (1.90) немного превосходит Fish Audio S1 (1.72) в этой категории — это единственная языковая группа, где конкурент опередил нашу старую модель. ElevenLabs Multilingual V2 также показывает хорошие результаты (1.70), вплотную приближаясь к S1.
Это объяснимо: ElevenLabs исторически фокусировалась на английском и европейских языках, и их модель V3 сильна в этой области. Тем не менее, Fish S2 Pro сохраняет преимущество в 1.6 раза над ElevenLabs V3.
Китайский язык
В китайском языке было собрано 329 пар предпочтений, и здесь наблюдается самое резкое доминирование Fish Audio.
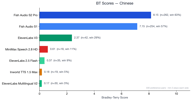
Обе модели Fish Audio (S2 Pro — 8.11, S1 — 7.11) значительно превосходят всех конкурентов. ElevenLabs V3 набрала 2.36 — достойно, но далеко позади. Все остальные конкуренты набрали менее 1.0.
Японский язык
Для японского языка собрано 354 пары предпочтений.
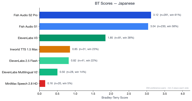
Fish S2 Pro (3.12) и Fish S1 (3.02) идут очень близко, обе далеко впереди ElevenLabs V3 (1.88). Разрыв между моделями Fish и конкурентами наиболее заметен в CJK-языках.
Сводка по языкам
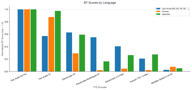
Fish Audio S2 Pro занимает первое место в каждой языковой категории. Конкурентный разрыв варьируется:
- Латиница: Конкуренты ближе всего, ElevenLabs V3 действительно конкурентоспособна (относительный балл 0.62).
- Китайский: Доминирование Fish Audio подавляющее, конкуренты почти не заметны.
- Японский: Ситуация аналогична китайскому — модели Fish далеко впереди.
Ограничения
Исключение пользователей API
Чтобы обеспечить стабильность платформы, пользователи API не участвовали в эксперименте. 10% частота выборки применялась только к пользователям веб-платформы. Это означает, что наши результаты отражают паттерны использования веб-интерфейса, которые могут отличаться от рабочих нагрузок API.
Неравномерный охват из-за поддержки тегов
Поскольку сторонние провайдеры по-разному поддерживают теги, они получали разные подмножества трафика:
- ElevenLabs V3 подходила почти для всех запросов (поддерживает теги).
- ElevenLabs Flash/Multilingual получали только запросы без тегов.
- Inworld получала только запросы без тегов в формате mp3.
Это означает, что конкурентное поле не было идеально ровным. Результаты ElevenLabs V3 наиболее сопоставимы с Fish Audio, так как эта модель получила наиболее репрезентативную выборку трафика. Другие модели оценивались на подмножестве, смещенном в сторону более простых текстовых запросов, что, по идее, должно было быть им на руку.
Результаты MiniMax могут быть недостоверными
MiniMax Speech 2.8 HD набрала чрезвычайно низкий балл (BT 0.12, 5% побед — даже против Inworld). Мы подозреваем, что наша интеграция MiniMax API может быть не оптимальной. Прослушав несколько образцов, сгенерированных MiniMax, мы не смогли выявить конкретную техническую проблему — аудио было разборчивым, но демонстрировало заметно худшую просодию и естественность по сравнению со всеми остальными провайдерами. Мы расширили критерии маршрутизации для MiniMax в середине эксперимента, чтобы увеличить выборку, но результаты не улучшились. Эксперимент был остановлен досрочно после накопления $330 затрат на API без признаков конкурентоспособных результатов.
Если в MiniMax считают, что эти результаты не отражают истинные возможности их модели, мы будем рады совместному аудиту нашей интеграции.
Ограничения клонирования голосов
Маршрутизация была возможна только для голосов, успешно клонированных на сторонних платформах. Если клон голоса не удавался, этот голос исключался из пула доступных для данного провайдера. Это означает, что каждый провайдер тестировался на немного отличающемся (хотя и в значительной степени пересекающемся) подмножестве из топ-500 голосов.
Возможная предвзятость из-за привычки к платформе
Хотя ~70% участников были новыми пользователями, у оставшихся ~30% вернувшихся пользователей могли сформироваться предпочтения, соответствующие характеристикам звучания Fish Audio. Мы считаем этот эффект незначительным, учитывая преобладание новых пользователей, но его нельзя полностью исключать.
Заключение
Мы считаем, что это одна из самых строгих публичных оценок качества TTS, когда-либо проводившихся:
- Реальные пользователи, а не платные аннотаторы.
- Слепое сравнение — пользователи никогда не знали, какой провайдер сгенерировал аудио.
- Поведенческий сигнал (скачивание) вместо субъективных оценок.
- Реальный трафик со сложностью текста из реального мира, включая длинный контент, теги просодии и многоязычность.
- Более 5 000 пар предпочтений на нескольких языках, собранных за 10 дней.
- Более $2,000, потраченных только на вызовы сторонних API.
Результаты очевидны: Fish Audio S2 Pro является наиболее предпочтительной модельй TTS во всех протестированных языках, с особенно сильным преимуществом в китайском и японском. Даже наша модель предыдущего поколения S1 превосходит любого конкурента в совокупности.
Эти результаты подтверждают правильность нашего пути к сквозному (end-to-end) моделированию и использованию RLHF (обучение с подкреплением на основе отзывов людей). Мы стремимся к прозрачности. Методология, логика маршрутизации и код анализа являются частью инфраструктуры нашей платформы. Мы приглашаем сообщество TTS изучить наш подход и предложить улучшения для будущих оценок.
Эта оценка была проведена командой Fish Audio в период с 26 марта по 5 апреля 2026 года. По вопросам или для обсуждения методологии обращайтесь на fish.audio.








