
Fish Audio открывает исходный код S2: тонкое управление сочетается с промышленным стримингом
S2 Pro доступен в Fish Audio App, а его исходный код — в GitHub-репозитории проекта и на HuggingFace.
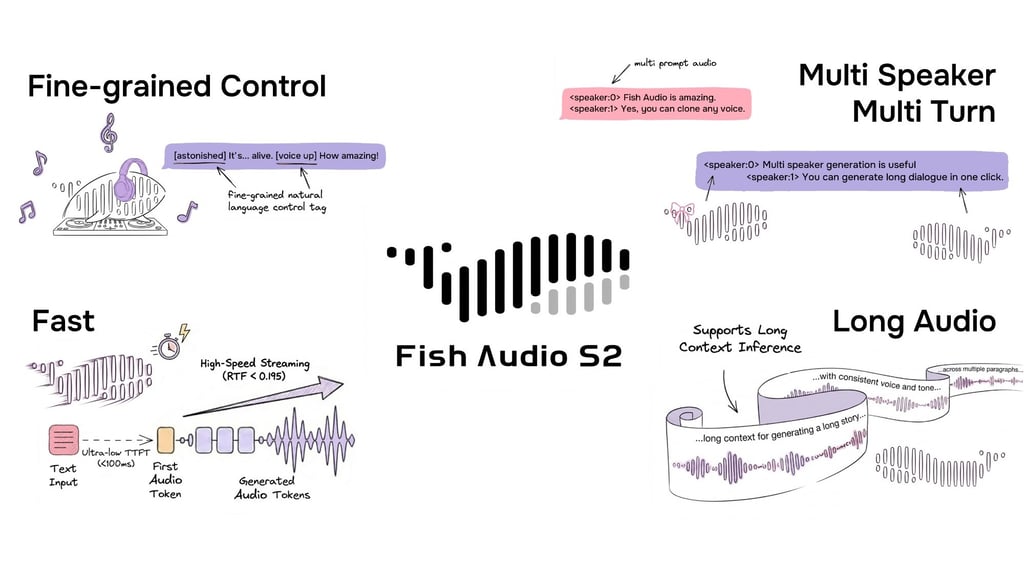
Fish Audio открыла исходный код S2 — модели преобразования текста в речь (TTS), которая поддерживает тонкое внутристрочное управление просодией и эмоциями с помощью тегов на естественном языке, таких как [laugh], [whispers] и [super happy]. Обученная на более чем 10 миллионах часов аудио на примерно 50 языках, система сочетает выравнивание с помощью обучения с подкреплением (RL) с двойной авторегрессионной архитектурой. Релиз включает веса модели, код для тонкой настройки и движок для потокового вывода на базе SGLang.
Тонкое внутристрочное управление через естественный язык
S2 обеспечивает внутристрочное управление генерацией речи путем встраивания инструкций на естественном языке непосредственно в определенные позиции слов или фраз внутри текста. Вместо того чтобы полагаться на фиксированный набор предопределенных тегов, S2 принимает текстовые описания в свободной форме — например, [whisper in small voice], [professional broadcast tone] или [pitch up], — что позволяет осуществлять неограниченное управление экспрессией на уровне слов.
В тесте Audio Turing Test модель S2 достигает апостериорного среднего значения 0,515 с переписыванием инструкций по сравнению с 0,417 у Seed-TTS и 0,387 у MiniMax-Speech. В EmergentTTS-Eval она достигает общего показателя побед 81,88% против базовой модели gpt-4o-mini-tts — самого высокого среди всех оцениваемых моделей, включая закрытые системы от Google и OpenAI.
 Пример формата ввода S2, демонстрирующий диалог нескольких дикторов с внутристрочными тегами на естественном языке в свободной форме для тонкого управления.
Пример формата ввода S2, демонстрирующий диалог нескольких дикторов с внутристрочными тегами на естественном языке в свободной форме для тонкого управления.
Единая методика: подготовка данных и RL-вознаграждения от одних и тех же моделей
Ключевым архитектурным решением в S2 является то, что одни и те же модели, используемые для фильтрации и аннотирования обучающих данных, напрямую повторно используются в качестве моделей вознаграждения во время обучения с подкреплением:
- Модель качества речи оценивает аудио по таким параметрам, как SNR (отношение сигнал/шум), консистентность диктора и разборчивость во время фильтрации данных, а затем служит в качестве награды за акустические предпочтения во время RL.
- Модель ASR с расширенной транскрипцией (дообученная на базе Qwen3-Omni-30B-A3B) генерирует транскрипты, дополненные описаниями с внутристрочными паралингвистическими аннотациями во время подготовки данных, а затем обеспечивает вознаграждение за разборчивость и следование инструкциям, повторно транскрибируя сгенерированное аудио и сравнивая его с исходным промптом.
Такая двойная архитектура устраняет несоответствие распределения между данными для предварительного обучения и целями постобучения — проблему, которая остается нерешенной в других TTS-системах, где модели вознаграждения обучаются отдельно от конвейеров подготовки данных.
Внутри модели: архитектура Dual-AR
S2 построена на базе трансформера (decoder-only) в сочетании с аудиокодеком на основе RVQ (10 кодовых книг, частота кадров ~21 Гц). Развертывание всех кодовых книг вдоль временной оси привело бы к 10-кратному взрывному росту длины последовательности. S2 решает эту проблему с помощью двойной авторегрессионной архитектуры (Dual-AR):
- Slow AR (медленная) работает вдоль временной оси и предсказывает основную семантическую кодовую книгу.
- Fast AR (быстрая) генерирует остальные 9 остаточных кодовых книг на каждом временном шаге, восстанавливая тонкие акустические детали.
Этот асимметричный дизайн — 4 млрд параметров вдоль временной оси и 400 млн параметров вдоль оси глубины — обеспечивает эффективность инференса при сохранении высокой точности звука.
Выравнивание методом обучения с подкреплением для речи
Для постобучения S2 использует метод Group Relative Policy Optimization (GRPO), выбранный для того, чтобы избежать накладных расходов памяти, характерных для моделей ценности типа PPO в контексте длинных аудиофрагментов. Сигнал вознаграждения объединяет несколько измерений, включая:
- Семантическую точность и соблюдение инструкций
- Оценку акустических предпочтений
- Сходство тембра
Результаты бенчмарков
S2 достигает лидирующих результатов в нескольких публичных бенчмарках:
| Бенчмарк | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Китайский) | 0.54% (лучший результат) |
| Seed-TTS Eval — WER (Английский) | 0.99% (лучший результат) |
| Audio Turing Test (с инструкцией) | 0.515 (апостериорное среднее) |
| EmergentTTS-Eval — Win Rate | 81.88% (самый высокий результат) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — Качество | 4.51 / 5.0 |
| Multilingual (MiniMax Testset) — Лучший WER | 11 из 24 языков |
| Multilingual (MiniMax Testset) — Лучшее сходство (SIM) | 17 из 24 языков |
В Seed-TTS Eval S2 демонстрирует самый низкий уровень WER среди всех оцениваемых моделей, включая закрытые системы: Qwen3-TTS (0.77/1.24), MiniMax Speech-02 (0.99/1.90), Seed-TTS (1.12/2.25). В тесте Audio Turing Test результат 0.515 превосходит Seed-TTS (0.417) на 24% и MiniMax-Speech (0.387) на 33%. В EmergentTTS-Eval S2 показывает особенно сильные результаты в паралингвистике (доля побед 91,61%), вопросах (84,41%) и синтаксической сложности (83,39%).
Для более широкого ознакомления с тем, как различные решения оцениваются по уровню контроля эмоций, задержке и поддержке языков, вы можете обратиться к этому независимому сравнению инструментов для работы с ИИ-голосом и аудио.
Промышленный стриминг через SGLang
Поскольку архитектура Dual-AR в S2 структурно изоморфна стандартным авторегрессионным LLM, она может напрямую наследовать все нативные оптимизации обслуживания LLM из SGLang с минимальными изменениями — включая непрерывный батчинг (continuous batching), постраничный KV-кэш, CUDA graph replay и кэширование префиксов на базе RadixAttention.
Для клонирования голоса S2 помещает токены эталонного аудио в системный промпт. RadixAttention в SGLang автоматически кэширует эти состояния KV, достигая среднего показателя попадания в кэш префиксов 86,4% (более 90% на пике) при повторном использовании того же голоса в разных запросах, что делает накладные расходы на предварительную обработку эталонного аудио практически незначительными.
На одном GPU NVIDIA H200:
- Коэффициент реального времени (RTF): 0.195
- Время до начала воспроизведения (TTFA): около 100 мс
- Пропускная способность: 3 000+ акустических токенов/с при сохранении RTF ниже 0.5
Для получения пошагового руководства по запуску S2 на облачных GPU H100/H200 см. руководство Spheron по развертыванию open-source TTS на облачных GPU.
Почему этот релиз важен
S2 выпускается не просто как контрольная точка модели, а как полноценная система: веса модели, код для тонкой настройки и готовый к промышленному использованию стек для инференса.
Выделяются два проектных решения. Во-первых, унифицированный конвейер данных и вознаграждений устраняет структурную проблему — несоответствие распределения между предварительным обучением и RL, — которую другие TTS-системы не решали на архитектурном уровне. Во-вторых, структурный изоморфизм между архитектурой Dual-AR и стандартными LLM означает, что S2 может использовать всю экосистему оптимизаций обслуживания LLM, не требуя кастомной инфраструктуры для вывода.
S2 доступен через GitHub-репозиторий проекта, SGLang-Omni, HuggingFace и в виде интерактивного демо на fish.audio.
Часто задаваемые вопросы
Как работает генерация диалогов с несколькими дикторами?
Доступно ли это через API?
Какие аудио-теги поддерживаются?
Какие языки поддерживаются?







