Fish Audio S2! Точный контроль ИИ-голоса на уровне отдельных слов

Fish Audio S2 внедряет внутритекстовые теги (inline tags) с открытым доменом, управление ИИ-голосом на уровне слов и поддержку 80 языков для выразительного TTS. Посмотрите, как это работает на реальных примерах.
Март 2026 | Fish Audio S2 уже доступен
Содержание
-
Что такое Fish Audio S2?
-
Что умеет S2 — за 30 секунд
-
Внутритекстовые теги в Fish Audio S2
-
Реальные примеры
-
Производительность S2 — результаты бенчмарков
-
80 языков
-
Open Source
-
Как начать работу
-
FAQ
Большинство инструментов для ИИ-озвучки позволяют выбрать голос и настроить настроение на глобальном уровне — спокойнее, энергичнее, немного теплее. Fish Audio S2 использует другой подход к выразительному TTS. Вы управляете голосом на уровне слов, используя обычный язык прямо внутри вашего сценария. Если вы знакомы с тегами эмоций Fish Audio в S1, то S2 значительно расширяет эту идею благодаря внутритекстовому управлению с открытым доменом.
Вот как это выглядит на практике:
I thought I was ready. [voice breaking] I wasn't.
[soft voice] Take your time. There's no rush.
That was the third time this week. [sigh] I really need to fix that.
Никаких панелей настроек. Никакого SSML. Никакого пост-продакшена. Вы вписываете указания прямо в текст, и S2 их исполняет.
Краткий обзор
Fish Audio S2 представляет внутритекстовые теги для выразительного управления TTS на уровне слов.
-
Теги с открытым доменом, написанные на естественном языке — без фиксированного словаря
-
Размещение в середине предложения для точного выбора времени и смены подачи
-
Поддержка около 80 языков
-
Модель с открытым исходным кодом, код для дообучения и стек для инференса
Вместо настройки глобальных параметров голоса, S2 позволяет вам управлять подачей прямо внутри сценария.
Что такое Fish Audio S2?
https://www.youtube.com/watch?v=NIcXTOSdOXc
Fish Audio S2 — это модель TTS второго поколения от Fish Audio. Она обучена на более чем 10 миллионах часов аудио на примерно 80 языках и представляет внутритекстовое управление тегами: инструкции на естественном языке, встроенные прямо в ваш сценарий в любом месте, что дает вам возможность детально управлять тем, как произносятся слова или фразы.
Модель имеет открытый исходный код на GitHub и HuggingFace, а также доступна через Fish Audio API и приложение.
Что умеет S2 — за 30 секунд
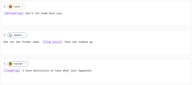
Внутритекстовые теги S2 — это инструкции в квадратных скобках, размещенные в любом месте вашего текста:
[whispering] Don't let them hear you.
She set the folder down. [long pause] Then she looked up.
[laughing] I have absolutely no idea what just happened.
Теги влияют на то, что идет после них. Размещайте тег именно в тот момент, когда должна произойти смена подачи — не обязательно в начале предложения, если вы этого не хотите.
Вы не выбираете из фиксированного меню. Вы пишете описание, а S2 его интерпретирует:
[the calm, measured tone of someone who has done this a thousand times]
Please place your hands where I can see them.
[overly cheerful, clearly forcing it]
Everything is completely fine. Totally fine.
Если вы можете описать это актеру озвучки, S2 сможет попытаться это исполнить.
Внутритекстовые теги в Fish Audio S2
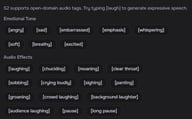
Внутритекстовые теги — это основной механизм управления в Fish Audio S2. Это инструкции на естественном языке в [квадратных скобках], которые вы встраиваете прямо в свой сценарий, чтобы направлять подачу речи — на любом слове, в любой момент.
Синтаксис
Поместите тег в [квадратные скобки] непосредственно перед словом или фразой, на которые он должен повлиять. Теги могут располагаться где угодно — в начале, середине или конце предложения.
[whispering] I didn't want to go inside.
I didn't want to go [whispering] inside.
Оба варианта работают. В первом шепотом произносится вся строка. Во втором — шепотом произносится только слово «inside» и далее. Расположение имеет значение.
Пишите теги на своем языке
Теги не обязательно должны быть на английском языке. S2 понимает инструкции на естественном языке на 80 языках — так что вы можете писать теги на том же языке, что и ваш сценарий.
日本語 (Японский)
[囁き声で] 誰にも聞かせないで。
[ため息をついて] もう一度やり直そう。
中文 (Китайский)
[低声说] 不要让他们听见。
[叹气] 我真的不知道该怎么办了。
español (Испанский)
[susurrando] No dejes que te escuchen.
[enojado] ¿Cómo pudiste hacer eso?
한국어 (Корейский)
[속삭이며] 아무도 모르게 해줘.
[화나서] 어떻게 그럴 수가 있어.
Логика та же: поместите тег непосредственно перед словом или фразой, на которые он должен повлиять, на любом языке, который кажется вам естественным для вашего сценария.
Проверенные теги
S2 принимает любое описание на естественном языке, но эти теги стабильно дают хорошие результаты. Теги действуют с момента их появления до следующего тега или конца предложения.
Дыхание и реакции
Вокальные звуки
Темп
Стиль голоса
Эмоции
Другое
Описания в свободной форме
Помимо списка тегов выше, S2 принимает описания в свободной форме. Пишите то, что вы сказали бы актеру озвучки:
[speaking slowly, almost hesitant]
[professional broadcast tone]
[dead tired, end of a very long shift]
[pitch up]
[voice rough from crying, trying to sound normal]
Поскольку S2 обучена на открытых описаниях, новые теги хорошо обобщаются — вы не ограничены примерами, виденными во время обучения.
Комбинирование тегов
Выстраивайте цепочки тегов в тексте, чтобы создавать переходы в подаче:
[soft voice] I wasn't sure what to say. [long pause] [loud voice] But then it hit me.
Используйте теги реакций между предложениями для естественных переходов:
That was the third time this week. [sigh] I really need to fix that.
Сочетание реакции с тегом эмоции придает чувству физическую основу:
[sigh] [sad] I just don't know anymore.
Реальные примеры
Озвучка аудиокниг
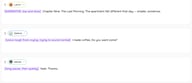
[NARRATOR, low and slow] Chapter Nine. The Last Morning. The apartment felt different that day — smaller, somehow.
SARAH: [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
DANIEL: [long pause, then quietly] Yeah. Thanks.
Подкаст

Today we're looking at something I've spent three months trying to understand.
[chuckling] I kept getting it wrong. My producer will confirm this.
Диалоги в играх
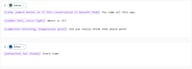
VILLAIN: [calm, almost bored, as if this conversation is beneath them] You came all this way.
VILLAIN: [sudden fury, voice tight] Where is it?
VILLAIN: [composure returning, dangerously quiet] Did you really think that would work?
HERO: [exhausted, but steady] Every time.
Голосовой агент

[friendly, warm] Hi — thanks for calling. How can I help you today?
[empathetic, unhurried] I'm sorry to hear that. Let me pull this up.
[confident] Good news — I can see exactly what happened, and I'm going to get this sorted for you right now.
Советы по получению лучших результатов
Внутритекстовые теги S2 выразительны, но то, насколько сильно они проявляются, зависит от того, как вы их используете — и с каким голосом работаете. Эти советы основаны на практическом тестировании.

Сочетайте физические теги с тегами эмоций. Теги вроде [panting] (прерывистое дыхание), [whispering] (шепот) и [shouting] (крик) сработают и сами по себе, но эффект может показаться плоским без эмоционального контекста. Сочетание их с тегом эмоции дает более стабильные и естественные результаты:
[panting] [tired] I've been running for twenty minutes.
[whispering] [scared] Don't move. Don't make a sound.
[shouting] [angry] I told you this would happen!

Всегда добавляйте текст после описательного тега. Описательному тегу, такому как [voice rough from crying, trying to sound normal], нужна строка для произнесения — не оставляйте его одного. Тег направляет подачу того, что следует за ним; без последующего текста результат может быть непредсказуемым.
✅ [voice rough from crying, trying to sound normal] I made coffee. Do you want some?
❌ [voice rough from crying, trying to sound normal]
Протестируйте голос перед написанием сценария. Разные голоса реагируют на один и тот же тег с разной интенсивностью. Голос с естественно спокойным регистром покажет более тонкие изменения, чем экспрессивный. Если тег не работает так, как вы ожидаете, попробуйте другой голос, прежде чем менять сам тег — часто проблема в голосе, а не в инструкции.
Начните с простого, затем добавляйте слои. Один удачно расположенный [sigh] или [long pause] может полностью изменить строку. Добавляйте больше тегов только тогда, когда простого варианта недостаточно. Избыточность тегов может привести к конфликту эффектов.
Скоро: выбирайте лучший вариант из нескольких генераций. S2 будет поддерживать одновременную генерацию нескольких версий одной и той же строки, чтобы вы могли сравнить и выбрать ту подачу, которая подходит лучше всего — аналогично тому, как инструменты генерации изображений позволяют выбирать из пачки вариантов. Это значительно упростит достижение нужного исполнения без необходимости вручную подправлять теги каждый раз.
Производительность S2 — результаты бенчмарков
Внутритекстовое управление S2 — это не просто удобная функция интерфейса, она также коррелирует с высокими результатами в публичных бенчмарках речи. Эти бенчмарки измеряют естественность речи, точность произношения и способность следовать инструкциям в современных системах TTS.
В Audio Turing Test S2 набрала 0,515 балла, превзойдя Seed-TTS на 24% и MiniMax-Speech на 33%. В EmergentTTS-Eval она достигла особенно высоких результатов в паралингвистике (91,61% винрейт), что напрямую отражает качество исполнения внутритекстовых тегов.
В Seed-TTS Eval S2 достигла самого низкого уровня ошибок в словах (WER) среди всех протестированных моделей, включая системы с закрытым исходным кодом: Qwen3-TTS (0,77% / 1,24%), MiniMax Speech-02 (0,99% / 1,90%) и Seed-TTS (1,12% / 2,25%).
Источник: Пост о запуске Fish Audio S2 от Шицзя Ляо, главного научного сотрудника
80 языков
S2 обучена на более чем 10 миллионах часов аудио на примерно 80 языках. В многоязычном тестовом наборе MiniMax, охватывающем 24 языка, S2 достигла лучшего уровня ошибок в словах на 11 языках и лучшей схожести дикторов на 17 — превзойдя как MiniMax, так и ElevenLabs в большинстве тестов бенчмарка.
Языки с подтвержденной высокой производительностью включают: арабский, кантонский диалект, китайский, чешский, голландский, английский, финский, французский, немецкий, греческий, хинди, индонезийский, итальянский, японский, корейский, польский, португальский, румынский, русский, испанский, тайский, турецкий, украинский, вьетнамский.
Open Source
В отличие от большинства коммерческих систем TTS, Fish Audio S2 является полностью открытой — веса моделей, код для дообучения и готовый к продакшену движок инференса на базе SGLang — что позволяет разработчикам самостоятельно хостить, дообучать и развертывать систему в любом масштабе.
-
GitHub: github.com/fishaudio/fish-speech
-
HuggingFace: huggingface.co/fishaudio/s2-pro
-
Инференс SGLang: SGLang-Omni
Производительность в продакшене на одном GPU H200:
-
Фактор реального времени (RTF): 0,195
-
Время до первого аудио (TTFA): ~100 мс
-
Пропускная способность: 3,000+ акустических токенов/с
Для клонирования голоса в масштабе S2 помещает токены эталонного аудио в системный промпт. KV-кэш SGLang достигает среднего коэффициента попадания в префикс-кэш 86,4% при повторном использовании одного и того же голоса в разных запросах, что делает накладные расходы на повторное клонирование голоса почти незначительными.
Как начать работу
-
Попробуйте в приложении
playground— fish.audio поддерживает внутритекстовые теги S2 напрямую. Поместите[квадратные скобки]в любое место вашего сценария и запустите генерацию. -
Интегрируйте через API — Доступно через Fish Audio API. См. справочник API для получения информации о эндпоинтах и аутентификации.
-
Самостоятельный хостинг модели — Веса и стек инференса открыты на GitHub и HuggingFace.
-
Скоро: Генерация диалогов с несколькими дикторами в приложении и API Fish Audio.
-
Полное руководство по синтаксису внутритекстовых тегов, правилам их размещения и советам: → Как использовать внутритекстовые теги Fish Audio S2
-
Если вы переходите с S1 и хотите понять, как связаны эти две системы: → Теги эмоций Fish Audio S1 — Полное руководство
FAQ
Что такое внутритекстовые теги в TTS?
Внутритекстовые теги (inline tags) — это короткие инструкции, встроенные прямо в сценарий преобразования текста в речь, чтобы управлять тем, как произносится конкретное слово или фраза: подачей, эмоциями, темпом или качеством голоса в этой конкретной точке. В отличие от глобальных настроек голоса, которые применяются ко всей генерации, внутритекстовые теги позволяют управлять отдельными моментами внутри строки. Fish Audio S2 использует [квадратные скобки] для внутритекстовых тегов и принимает описания на естественном языке в свободной форме.
Что такое Fish Audio S2?
Fish Audio S2 — это модель TTS второго поколения от Fish Audio. Она поддерживает детальное внутритекстовое управление с помощью тегов на естественном языке в [квадратных скобках], расположенных в любом месте сценария. Модель обучена на более чем 10 миллионах часов аудио на примерно 80 языках. Она имеет открытый исходный код на GitHub и HuggingFace, а также доступна через Fish Audio API и приложение~~ playground~~.
Как работают внутритекстовые теги в S2?
Поместите тег в [квадратные скобки] непосредственно перед словом или фразой, на которые он должен повлиять. Вы можете использовать проверенные теги, такие как [whispering], [sigh] или [long pause], или написать любое описание на естественном языке в свободной форме. Теги применяются ко всему последующему тексту до следующего тега или конца предложения.
Является ли Fish Audio S2 открытым исходным кодом?
Да. Веса моделей, код для дообучения и движок инференса на базе SGLang открыты на github.com/fishaudio/fish-speech и huggingface.co/fishaudio/s2-pro
Сколько языков поддерживает S2?
S2 обучена примерно на 80 языках. В многоязычном бенчмарке из 24 языков S2 достигла лучшего уровня ошибок в словах на 11 языках и лучшей схожести дикторов на 17, превзойдя MiniMax и ElevenLabs.
Поддерживает ли S2 синтаксис S1 с круглыми скобками ()?
Нет. S2 нативно использует [квадратные скобки]. Веб-интерфейс Fish Audio автоматически преобразует () в [] при выборе S2, но если вы используете API напрямую, используйте квадратные скобки.
Поддерживает ли S2 диалоги с несколькими дикторами?
Генерация с несколькими дикторами скоро появится в приложении и API Fish Audio. Модель поддерживает это нативно — следите за обновлениями.
В чем разница между Fish Audio S1 и S2?
S1 использует фиксированный словарь предустановленных тегов эмоций в (круглых скобках), размещаемых в начале предложений. S2 использует теги на естественном языке с открытым доменом в [квадратных скобках], которые могут появляться в любом месте сценария — в середине предложения, между словами или в начале. S2 также принимает описания в свободной форме, а не только закрытый список ключевых слов, поэтому вы не ограничены заранее определенными эмоциями. Для подробного разбора см. Руководство по тегам эмоций Fish Audio S1.
Может ли Fish Audio S2 заменить SSML?
Для большинства сценариев использования выразительной речи — да. Fish Audio S2 может воспроизводить многие элементы управления в стиле SSML с помощью внутритекстовых тегов на естественном языке: вместо XML-разметки вроде <prosody rate="slow"> вы пишете [speaking slowly] прямо в сценарии. Теги вроде [whispering], [long pause] и [angry] охватывают наиболее распространенные выразительные функции SSML, не требуя знаний специализированной разметки.
Совместимы ли внутритекстовые теги Fish Audio S2 с другими системами TTS?
Нет. Синтаксис внутритекстовых тегов в Fish Audio S2 специфичен для этой модели. Другие системы TTS используют SSML или свои собственные проприетарные форматы. Однако базовые концепции выразительности — паузы, смена тона, вокальные сигналы — концептуально переносятся при переходе между системами, даже если синтаксис отличается.
Связанные ресурсы:

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
Читать больше от Sabrina Shu







