Синтез речи с несколькими голосами — Полное руководство по Multispeaker (Fish Audio)

Одноголосый TTS звучит монотонно для диалогов, аудиокниг и подкастов. Это руководство покажет вам, как искать и упорядочивать голоса в Fish Audio, а затем использовать мультидикторный режим в TTS и Story Studio для создания естественного многоперсонажного аудио без использования традиционных методов записи голоса.
Март 2026 | Мультидикторный TTS от Fish Audio теперь доступен в S2 Pro
Содержание
- Что такое мультидикторный синтез речи?
- Шаг 1 — Поиск подходящих голосов в Discovery
- Шаг 2 — Мультидикторный режим в Text to Speech
- Шаг 3 — Мультидикторный режим в Story Studio
- TTS против Story Studio — что выбрать?
- Варианты использования — что можно создать?
- От сценария к аудио — за один сеанс
- Часто задаваемые вопросы о мультидикторном TTS
Большинство инструментов синтеза речи предлагают только один голос. Один диктор. Одна интонация от начала до конца. Для объясняющего видео с одним участником этого достаточно. Но как только в вашем сценарии появляются два персонажа, ведущий и гость или история с разными ролями — один голос превращает диалог в плоское, монотонное чтение. Слушатели быстро теряют интерес.
Синтез речи с несколькими голосами решает эту проблему. Назначьте отдельный ИИ-голос каждому диктору, настройте тайминг между ними, и в результате вы получите диалог, который действительно звучит как живая беседа. Fish Audio работает как полноценный генератор диалогов — от поиска голосов до экспорта многоглавных проектов. Это руководство проведет вас через весь рабочий процесс: как находить и организовывать голоса, как использовать мультидикторный режим в инструменте Text to Speech для короткого контента и как масштабироваться до полноценного производства в Story Studio.
Что такое мультидикторный синтез речи?
Мультидикторный синтез речи — это процесс в TTS, при котором различным сегментам сценария назначаются разные ИИ-голоса (каждый со своим тембром, полом, возрастом и стилем речи), которые затем генерируются как единый непрерывный аудиофайл.
Традиционные инструменты TTS построены на модели одного повествователя: один голос, одно текстовое поле, один аудиофайл. Такая схема подходит для озвучки аудиокниг одним диктором, закадрового перевода или объявлений. Однако она совершенно не годится для диалогов. Чтобы создать беседу двух персонажей с помощью устаревших инструментов, вам пришлось бы генерировать каждого диктора отдельно, а затем вручную соединять аудио в редакторе — настраивая тайминг, выравнивая громкость и надеясь, что переходы не будут звучать как две разные записи.
Проблема не только в лишних шагах. Тайминг между дикторами почти невозможно настроить правильно без специальных инструментов. У живого общения есть ритм: пауза перед ответом, небольшое наслоение, когда кто-то перебивает, или долгая пауза перед сложным ответом. Без точного контроля пауз между дикторами даже хорошо подобранный диалог звучит роботизировано.
Мультидикторные TTS-инструменты решают обе проблемы. Каждый диктор получает свой голос и свой текстовый блок. Паузы между дикторами можно настраивать. Конечный результат — единый, связный аудиофайл с уже заданным таймингом.
Мультидикторный синтез речи позволяет вам:
- Назначать отдельный ИИ-голос каждому участнику диалога в сценарии
- Контролировать тайминг и паузы между дикторами
- Генерировать весь диалог как единый непрерывный аудиофайл
- Масштабировать проект от беседы двух персонажей до целого актерского состава — без дополнительных экспортов и ручного монтажа
Шаг 1 — Поиск подходящих голосов в Discovery
Прежде чем приступить к мультидикторному проекту, вам нужны голоса. Их можно найти на странице Discovery в Fish Audio. Учитывая тысячи голосов в библиотеке, инструменты фильтрации имеют решающее значение.
Перейдите на fish.audio/app/discovery/.
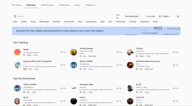
Поиск и фильтрация
На странице Discovery вы увидите строку поиска, теги быстрой фильтрации в верхнем ряду, а также элементы управления сортировкой и языком справа.
Ищите по имени, если вы уже знаете, какой голос вам нужен. Сортируйте по Рекомендованным (Recommended) или Трендовым (Trending), чтобы увидеть наиболее популярные варианты. Фильтр Language ограничивает библиотеку голосами, обученными на вашем целевом языке.
Теги быстрой фильтрации охватывают наиболее распространенные атрибуты — Male (Мужской), Female (Женский), Young (Молодой), Middle Aged (Среднего возраста), Narration (Повествование), Social Media (Соцсети), Deep (Глубокий), Soft (Мягкий), Professional (Профессиональный), Dramatic (Драматичный), Mysterious (Таинственный), Anime (Аниме). Их можно комбинировать. Выбор Female + Young + Narration мгновенно сузит результаты до голосов, соответствующих этому профилю.

Для более точного контроля откройте панель фильтров (иконка ползунков справа вверху). Она включает:
- Languages — выбор конкретного языка с поддержкой многоязычного соответствия
- Tags — произвольные теги, добавленные создателями голосов
- Gender — Male, Female, Neutral
- Age — Young, Middle Aged, Old
- Use Case — Conversational (Разговорный), Narration (Повествование), Character Voice (Голос персонажа), Social Media, Educational, Advertisement и другие
- Voice Qualities — Deep (Глубокий), Low (Низкий), Medium (Средний), High (Высокий), Soft (Мягкий), Bright (Яркий) и еще более 48 дескрипторов
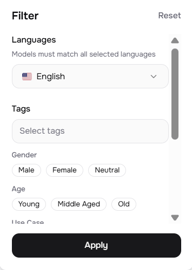
Для мультидикторного проекта фильтры Use Case и Voice Qualities особенно полезны. Если вы создаете диалог в стиле подкаста, вам может понадобиться один голос Conversational + Soft и один Narration + Deep — они достаточно разные, чтобы слушатели могли различать дикторов на слух.
Лайки, закладки и сохранение в коллекции
Когда вы найдете голос, который захотите использовать позже, у вас есть несколько способов его сохранить. Иконка сердечка на каждой карточке голоса — это быстрый лайк; голос добавится во вкладку Likes для последующего ознакомления.
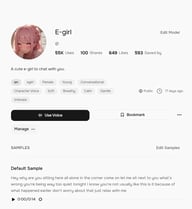
Для надежного сохранения откройте страницу с описанием голоса и нажмите Bookmark. Закладки (Bookmarked) отображаются во вкладке Bookmarks отдельно от лайков и доступны напрямую из селектора голоса как в TTS, так и в Story Studio.
Для организации на уровне проекта лучше всего использовать Коллекции (Collections). Нажмите Collections в верхней навигации, затем Create Collection, чтобы создать именованную группу — например, "Для подкаста" или "Аудиокнига Проект А". Дайте ей название и описание, затем нажмите Create.

Чтобы добавить голос в коллекцию, откройте страницу голоса, нажмите на меню из трех точек (⋯) рядом с кнопкой Bookmark и выберите Add to Collection. Если коллекция уже создана, она появится в списке.
Преимущество коллекций становится очевидным в TTS или Story Studio. Когда вы открываете панель Select Voice, ваши коллекции отображаются в виде вкладок сверху — рядом с Recently Used, Explore, Default Voices, My Voices и Bookmarked. Вам не нужно каждый раз искать голоса с нуля.
Шаг 2 — Мультидикторный режим в Text to Speech
Инструмент Text to Speech от Fish Audio поддерживает несколько дикторов в одной генерации. Это идеальное решение для короткого и среднего контента: фрагментов диалогов, рекламы, коротких интро для подкастов, демо-сценариев и всего, где нужен быстрый результат без управления главами. Если вы еще не выбрали голоса, начните с библиотеки Discovery.
Перейдите на fish.audio/app/text-to-speech/.
Настройка первого диктора
При открытии TTS вы увидите текстовый блок с селектором голоса наверху. Нажмите на имя голоса, чтобы открыть панель Select Voice и выбрать первого диктора. Введите или вставьте реплики первого диктора в текстовый блок.
Вы также можете использовать инлайновые теги эмоций, чтобы задать характер озвучки — [sad], [emphasis], [excited] — ставя их в тексте непосредственно перед словами, на которые они должны повлиять.
Добавление новых дикторов
Нажмите + Add Speaker под первым текстовым блоком. Появится новый блок со своим независимым селектором голоса. Выберите другой голос, введите текст, и оба блока будут сгенерированы в виде единого аудиофайла в том порядке, в котором они расположены на экране.
Верхнего предела количества дикторов нет. Каждый блок независим: свой голос, свой текст, свои теги эмоций. На практике для большинства диалогов достаточно 2–4 различных голосов — этого хватает для разнообразия, при этом слушатель не путается в персонажах. На правой панели перед генерацией можно настроить Volume (Громкость), Speed (Скорость), Loudness Normalization (Нормализация громкости) и Text Normalization (улучшает точность чтения чисел, валют и форматов).
Лимит символов и переход в Story Studio
Следите за счетчиком символов в нижней части экрана. Лимит зависит от вашего тарифного плана — ознакомьтесь с ценами и планами Fish Audio, чтобы узнать ограничения вашего уровня. Для короткого контента TTS — это самый быстрый способ. Но если вы работаете над чем-то более масштабным (целая глава аудиокниги, подкаст из нескольких сегментов, сценарий игры), вам понадобятся инструменты Story Studio.
Шаг 3 — Мультидикторный режим в Story Studio
Story Studio создана для производства длинного аудиоконтента. Если TTS оптимизирован для быстрой генерации, то Story Studio предоставляет структурированную среду для последовательного выстраивания блоков с разными голосами, точного контроля тайминга и организации сложных проектов по главам. Каждый блок генерируется независимо с назначенным голосом, а при экспорте они сшиваются в один непрерывный файл. Перейдите на fish.audio/app/story-studio/.
Создание нового проекта
Нажмите + Project на главном экране Story Studio. В окне Create project доступны следующие настройки:
- Project Name — название проекта
- Default Voice — голос, который будет назначаться новым блокам по умолчанию (можно изменить для каждого блока)
- Speech Model — на данный момент S2 Pro (новейшая)
- Text Normalization — улучшает точность чтения чисел, дат и валют
- Loudness Normalization — выравнивает уровень громкости во всех блоках для однородного звучания
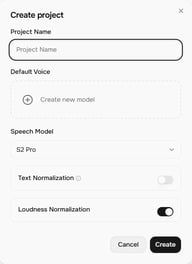
Нажмите Create, чтобы открыть редактор проекта.
Добавление блоков и переключение голосов
Ваш проект откроется с главой по умолчанию и первым текстовым блоком. Голос первого диктора отображается в виде цветного аватара слева от блока.
Чтобы добавить реплику нового диктора, нажмите кнопку + под любым существующим блоком. Появится новый блок. Нажмите на цветной аватар голоса слева от нового блока, чтобы открыть панель Select Voice и назначить другой голос. Введите текст реплики.
Повторяйте это для каждой реплики вашего сценария. Каждый блок — это очередь одного диктора. На панели справа отображается список Voices used in the project (Голоса, используемые в проекте), что позволяет быстро отслеживать весь ваш актерский состав.
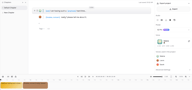
Настройка пауз между дикторами
Между каждой парой блоков вы увидите небольшой индикатор тайминга, показывающий текущую паузу — например, 0.35s. Нажмите на него, чтобы изменить длительность паузы между этими конкретными дикторами.
Это одна из важнейших функций Story Studio для создания реалистичных диалогов. Человеческая беседа — это не просто череда фраз без пауз. Короткая пауза перед ответом сигнализирует о раздумье. Более долгая пауза перед эмоциональной репликой добавляет веса сказанному. Правильная настройка этих пауз — это то, что отличает искусственное аудио от по-настоящему живого звучания. Даже изменение на 0.2–0.5 сек. может заметно сделать диалог более естественным. Настраивайте каждую паузу индивидуально, чтобы соответствовать ритму сцены.
Добавление глав для крупных проектов
С левой стороны редактора находится панель глав (Chapters). По умолчанию каждый проект начинается с "Default Chapter". Нажмите +, чтобы добавить новую главу.
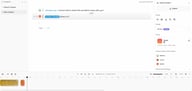
Главы позволяют разбивать длинные проекты на удобные разделы: по главе для каждой части аудиокниги, сегмента подкаста или сцены в игровом сценарии. Каждая глава имеет свою последовательность блоков и может редактироваться независимо. При финальном экспорте все главы объединяются в один файл по порядку.
Для любого диалога длиннее нескольких сотен слов главы — это лучший способ организовать проект в Story Studio.
TTS против Story Studio — что выбрать?
| Text to Speech | Story Studio | |
|---|---|---|
| Метод мультидикторности | Нативный (на уровне модели S2 Pro) | Последовательная генерация блоков |
| Лимит символов | Зависит от тарифа | Без лимита (через главы) |
| Количество дикторов | До 5 | Неограниченно |
| Контроль пауз между блоками | ❌ | ✅ Точный, для каждого блока |
| Управление главами | ❌ | ✅ |
| Вид временной шкалы | ❌ | ✅ |
| Лучше всего для | Коротких диалогов, рекламы, демо | Аудиокниг, подкастов, сценариев игр |
Ключевое техническое различие: TTS использует нативную мультидикторную возможность S2 Pro — несколько дикторов обрабатываются на уровне модели за одну генерацию. Story Studio достигает мультидикторного вывода путем последовательного соединения отдельно сгенерированных блоков, каждый со своим назначенным голосом.
Если вы создаете 30-секундный рекламный ролик с двумя дикторами или короткий клип, используйте TTS — это быстрее и не требует настройки проекта. Если ваш сценарий длиннее, включает много реплик или требует точного тайминга, выбирайте Story Studio.
Варианты использования — что можно создать с помощью мультидикторного TTS?
Аудиокниги с несколькими персонажами
Книги с одним диктором хороши для нон-фикшн. В художественной литературе с диалогами следить за сюжетом, когда всех персонажей читает один голос, становится трудно. С мультидикторным TTS каждый персонаж получает свой голос: глубокий старческий голос для одного, энергичный и молодой для другого. Структура глав в Story Studio идеально ложится на книжные главы, позволяя создавать полноценные произведения без участия актеров озвучки.
Диалоги в стиле подкаста
Формат подкаста с двумя ведущими — одна из самых популярных аудиоструктур. С помощью мультидикторного генератора диалогов вы можете создавать такой контент на основе сценария — по одному голосу на каждого ведущего с настраиваемыми паузами, имитирующими естественную беседу. Это особенно полезно для создателей контента, которые хотят выпускать регулярные аудио без записи в студии.
E-Learning и обучающий контент
Обучающие материалы воспринимаются гораздо лучше, когда они поданы в виде диалога, а не монолога. Обмен репликами между учителем и учеником, разбор сценария или формат вопросов и ответов могут быть озвучены двумя или более голосами, что помогает лучше усваивать информацию.
Диалоги в играх и голоса персонажей
Сценарии игр часто содержат сотни и тысячи строк для множества персонажей. Используя Story Studio в качестве многоперсонажного генератора голосов, разработчики игр могут создавать озвучку для прототипов, демо или финальных версий — при этом за каждым NPC закрепляется стабильный голос на протяжении всей игры.
От сценария к аудио — за один сеанс
Раньше создание многоперсонажного аудио означало поиск актеров, координацию записей и долгие часы монтажа. С мультидикторным TTS весь этот процесс превращается в один сеанс: найдите голоса в Discovery, организуйте их в Коллекцию, соберите сценарий блок за блоком и экспортируйте.
Для короткого контента Text to Speech позволит получить результат за считанные минуты. Для крупных проектов — аудиокниг, серий подкастов, игровых диалогов — Story Studio даст структуру и контроль тайминга, необходимые для профессионального звучания.
🎧 Создайте свой первый диалог на 2 диктора менее чем за 2 минуты →
🎙 Превратите свой сценарий в аудиокнигу с полным актерским составом ИИ-голосов →
", "image_alt": "Баннер руководства Fish Audio по мультидикторному синтезу речи", "article_tags": ["РУКОВОДСТВО"], "faq": [{"question": "Сколько голосов можно использовать в одном проекте?", "answer": "Ограничений на количество дикторов ни в TTS, ни в Story Studio нет. При необходимости вы можете назначить отдельный голос для каждого блока."}, {"question": "Доступен ли мультидикторный TTS в бесплатном плане?", "answer": "Вы можете использовать мультидикторные функции на бесплатном тарифе в пределах лимитов кредитов и символов вашего плана. Полную разбивку см. на fish.audio/plan."}, {"question": "В чем разница между TTS и Story Studio для мультидикторного контента?", "answer": "TTS предназначен для короткого контента — быстрая генерация, не требует настройки проекта, ограничен лимитом символов на одну генерацию. Story Studio создана для крупных проектов с точным контролем пауз, управлением главами, временной шкалой и без ограничений по длине контента."}, {"question": "Можно ли использовать мультидикторное аудио для коммерческих проектов?", "answer": "Права на использование зависят от модели голоса и вашего тарифного плана. Проверьте лицензию конкретного голоса на его странице и ознакомьтесь с условиями коммерческого использования для разных тарифов на fish.audio/plan."}, {"question": "Можно ли повторно использовать одну и ту же настройку голосов в разных проектах?", "answer": "Да — сохраните голоса в Коллекцию (Collection) в Discovery, и эта коллекция появится в панели выбора голоса в каждом новом проекте TTS или Story Studio. Вам не придется искать их снова."}, {"question": "Что если в моем сценарии больше персонажей, чем сохраненных голосов?", "answer": "Вы всегда можете воспользоваться поиском в Discovery прямо во время работы над проектом. Панель выбора голоса в TTS и Story Studio включает вкладку Explore, позволяя находить и прослушивать новые голоса, не покидая проект."}]}```

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






