Fish Audio S2!词级精细 AI 语音控制

Fish Audio S2 为表现力丰富的 TTS 带来了开放域行内标签、词级 AI 语音控制以及 80 种语言支持。查看实际示例,了解其工作原理。
2026 年 3 月 | Fish Audio S2 现已发布
目录
-
什么是 Fish Audio S2?
-
S2 能做什么 —— 30 秒快速了解
-
Fish Audio S2 中的行内标签
-
实际示例
-
S2 性能如何 —— 基准测试结果
-
80 种语言
-
开源
-
如何开始使用
-
常见问题解答 (FAQ)
大多数 AI 语音工具会为你提供一种声音,并让你在全局层面调整情绪 —— 更冷静、更有活力或更温暖。Fish Audio S2 在表现力 TTS 方面采用了不同的方法。你可以直接在脚本中使用自然语言进行词级语音指导。如果你熟悉 S1 中的 Fish Audio 情感标签,S2 通过开放域行内控制极大地扩展了这一理念。
在实践中,它是这样的:
我以为我准备好了。[声音颤抖] 但我没有。
[温柔的声音] 慢慢来。不着急。
这是本周第三次了。[叹气] 我真的需要解决这个问题。
无需设置面板。无需 SSML。无需后期制作。你将指令写进文本,S2 负责呈现。
快速摘要
Fish Audio S2 引入了行内标签,用于词级的表现力 TTS 控制。
-
使用自然语言编写的开放域标签 —— 无固定词汇表
-
句中插入,实现精确的时机和语气转换
-
支持约 80 种语言
-
开源模型权重、微调代码和推理栈
无需调整全局语音设置,S2 让你直接在脚本内部指导表达方式。
什么是 Fish Audio S2?
https://www.youtube.com/watch?v=NIcXTOSdOXc
Fish Audio S2 是来自 Fish Audio 的第二代 TTS 模型。它在约 80 种语言的超过 1000 万小时音频上进行了训练,并引入了行内标签控制:直接嵌入在脚本任何位置的自然语言指令,让你在词或短语级别对语音表达方式进行精细指导。
该模型已在 GitHub 和 HuggingFace 开源,并可通过 Fish Audio API 和 APP 使用。
S2 能做什么 —— 30 秒快速了解
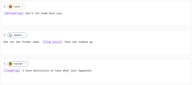
S2 的行内标签是放置在文本中任何位置的方括号指令:
[窃窃私语] 别让他们听到你。
她放下了文件夹。[长停顿] 然后她抬起头。
[笑着说] 我完全不知道刚才发生了什么。
标签会影响其之后的内容。在需要发生转变的确切位置放置标签 —— 除非你希望从句首开始,否则不要放在句首。
你不是在从固定菜单中选择。你编写描述,S2 负责解释:
[用一种已经做过一千次的、沉着稳重的语气]
请把手放在我能看到的地方。
[过度开朗,明显是在强颜欢笑]
一切都很好。完全没问题。
如果你能向配音演员描述出来,S2 就可以尝试实现。
Fish Audio S2 中的行内标签
行内标签是 Fish Audio S2 的核心控制机制。它们是嵌入在 [方括号] 中的自然语言指令,你可以直接将其嵌入到脚本中,在任何单词、任何位置指导语音的表达方式。
语法
在要受影响的词或短语之前立即放置 [方括号] 标签。标签可以放在任何地方 —— 句首、句中或句末。
[窃窃私语] 我不想进去。
我不想 [窃窃私语] 进去。
两者都有效。第一种是整行耳语。第二种是从“进去”开始耳语。位置即意义。
用你的语言编写标签
标签不一定要用英语。S2 理解涵盖 80 种语言的自然语言指令 —— 因此你可以使用与脚本相同的语言编写标签。
日本語 (Japanese)
[囁き声で] 誰にも聞かせないで。
[ため息をついて] もう一度やり直そう。
中文 (Chinese)
[低声说] 不要让他们听见。
[叹气] 我真的不知道该怎么办了。
español (Spanish)
[susurrando] No dejes que te escuchen.
[enojado] ¿Cómo pudiste hacer eso?
한국어 (Korean)
[속삭이며] 아무도 모르게 해줘.
[화나서] 어떻게 그럴 수가 있어.
同样的逻辑也适用:在受影响的词或短语之前立即放置标签,使用任何对你的脚本来说自然的语言。
经过验证的标签
S2 接受任何自然语言描述,但这些标签在默认情况下能持续产生强大的效果。标签从出现点开始生效,直到下一个标签或句子结束。
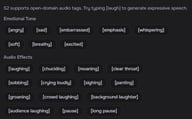
呼吸与反应
| 标签 | 描述 |
|---|---|
[breathing] | 明显的吸气或呼气 |
[panting] | 沉重的、快速的呼吸(如跑步后) |
[sigh] | 听得见的叹息 |
[sniffing] | 抽鼻涕或闻东西的声音 |
[clears throat] | 短促的清嗓子声音 |
发声
| 标签 | 描述 |
|---|---|
[laughter] | 语音中带有笑声或独立的笑声 |
[chuckling] | 轻微的、低沉的笑声 |
[cough] | 单次或多次咳嗽 |
[crying] | 带有抽泣或呜咽的语音 |
语速与节奏
| 标签 | 描述 |
|---|---|
[slight pause] | 短暂的中断(约 0.5 秒) |
[long pause] | 较长的停顿(约 1.5-2 秒) |
[speaking fast] | 增加语速 |
[speaking slowly] | 降低语速 |
语音风格
| 标签 | 描述 |
|---|---|
[whispering] | 降低音量,增加气息感 |
[shouting] | 提高音量,增加力度 |
[mumbling] | 降低清晰度,显得含糊 |
[monotone] | 移除音调起伏 |
情感
| 标签 | 描述 |
|---|---|
[happy] | 语调上扬,明亮 |
[sad] | 语调下降,沉重 |
[angry] | 语气紧绷,有力 |
[scared] | 声音颤抖,不稳定 |
[excited] | 高能量,语调变化快 |
其他
| 标签 | 描述 |
|---|---|
[pitch up] | 提高声音的音调 |
[pitch down] | 降低声音的音调 |
[singing] | 尝试以旋律感朗读文本 |
自由格式描述
除了上面的标签列表外,S2 还接受开放式描述。写下你会对配音演员说的话:
[说话很慢,几乎有些犹豫]
[专业的广播音调]
[精疲力竭,长班结束后的状态]
[音调上扬]
[声音因哭泣而沙哑,努力听起来正常]
由于 S2 是在开放式描述上训练的,新型标签的泛化效果很好 —— 你不仅限于训练期间见过的示例。
组合标签
在一段文字中链接多个标签以创建表达方式的转变:
[温柔的声音] 我不确定该说什么。[长停顿] [大声说] 但随后我想通了。
在句子之间使用反应标签以实现自然过渡:
这是本周第三次了。[叹气] 我真的需要解决这个问题。
将反应标签与情感标签结合使用,可以使情感更具真实感:
[叹气] [伤心] 我真的不知道该怎么办了。
实际示例
有声读物旁白
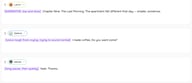
[旁白,低沉且缓慢] 第九章。最后的清晨。那天公寓的感觉变得不同了 —— 莫名地变小了。
莎拉:[声音因哭泣而沙哑,努力听起来正常] 我煮了咖啡。你想喝吗?
丹尼尔:[长停顿,然后安静地] 好。谢谢。
播客

今天我们要探讨的是我花了三个月时间才弄明白的一件事。
[轻笑] 我之前一直搞错。我的制作人可以证明这一点。
游戏对话
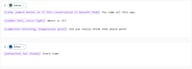
反派:[冷静,几乎是厌烦的,仿佛这次谈话有失身份] 你竟一路找过来了。
反派:[突然暴怒,声音紧绷] 它在哪儿?
反派:[恢复镇定,冷得可怕] 你真的以为那样会有用吗?
英雄:[筋疲力尽,但语气坚定] 每次都有用。
语音代理

[友好,温暖] 嗨 —— 感谢致电。今天我能为您做些什么?
[共情,从容] 听到这个我很遗憾。让我帮您查询一下。
[自信] 好消息 —— 我已经看清了问题所在,我现在就为您处理好。
获得最佳效果的建议
S2 的行内标签表现力很强,但其呈现效果取决于你如何使用它们 —— 以及你所使用的语音。这些建议基于实际测试总结。

将动作标签与情感标签配对。 像 [喘气]、[耳语] 和 [大喊] 这样的标签本身会有效果,但如果没有情感语境,效果可能会显得平淡。将它们与情感标签结合使用,可以产生更一致、更自然的效果:
[喘气] [疲惫] 我已经跑了二十分钟了。
[耳语] [恐惧] 别动。别发出一点声音。
[大喊] [愤怒] 我告诉过你会发生这种事!

描述性标签后务必紧跟文本。 像 [声音因哭泣而沙哑,努力听起来正常] 这样的描述性标签需要一段话来朗读 —— 不要让它孤立存在。标签指导其后内容的表达方式;如果后面没有文本,输出可能会不可预测。
✅ [声音因哭泣而沙哑,努力听起来正常] 我煮了咖啡。你想喝吗?
❌ [声音因哭泣而沙哑,努力听起来正常]
在编写脚本前先测试语音。 不同的语音对同一个标签的反应强度不同。天生冷静的语音表现出的变化比表现力丰富的语音更微妙。如果标签没有达到预期的效果,在调整标签之前,先尝试更换不同的语音 —— 问题通常出在语音本身,而不是指令。
由简入繁,层层递进。 一个位置恰到好处的 [叹气] 或 [长停顿] 就能完全改变一句话。只有当简单的版本不够用时,才添加更多标签。过多的标签会互相竞争,削弱效果。
即将推出:从多次生成中挑选你最喜欢的。 S2 将支持一次生成同一行的多个版本,因此你可以比较并选择最合适的表达方式 —— 类似于图像生成工具让你从一批图中进行选择。这将使微调表演变得更加容易,无需每次手动调整标签。
S2 性能如何 —— 基准测试结果
S2 的行内控制不仅仅是一个 UX 功能 —— 它还与公共语音基准测试中的强劲表现相呼应。这些基准测试衡量了现代 TTS 系统的语音自然度、发音准确度和指令遵循能力。
在 Audio Turing Test(语音图灵测试)上,S2 得分为 0.515 —— 超过 Seed-TTS 24%,超过 MiniMax-Speech 33%。在 EmergentTTS-Eval 上,它在副语言学(paralinguistics)方面取得了特别强劲的结果(91.61% 胜率),这直接反映了行内标签执行的质量。
在 Seed-TTS Eval 上,S2 在所有评估模型(包括闭源系统)中取得了最低的字错率(WER):Qwen3-TTS (0.77% / 1.24%)、MiniMax Speech-02 (0.99% / 1.90%) 和 Seed-TTS (1.12% / 2.25%)。
来源:Fish Audio S2 发布公告,作者 Shijia Liao,首席科学家
80 种语言
S2 在涵盖约 80 种语言的超过 1000 万小时音频上进行了训练。在涵盖 24 种语言的 MiniMax 多语言测试集中,S2 在 11 种语言中取得了最佳字错率,并在 17 种语言中取得了最佳说话人相似度 —— 在大多数基准测试项中优于 MiniMax 和 ElevenLabs。
已确认表现强劲的语言包括:阿拉伯语、粤语、中文、捷克语、荷兰语、英语、芬兰语、法语、德语、希腊语、印地语、印度尼西亚语、意大利语、日语、韩语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、泰语、土耳其语、乌克兰语、越南语。
开源
与大多数商业 TTS 系统不同,Fish Audio S2 完全开源 —— 包括模型权重、微调代码和生产级基于 SGLang 的推理引擎 —— 允许开发者自行托管、微调和大规模部署。
-
GitHub: github.com/fishaudio/fish-speech
-
HuggingFace: huggingface.co/fishaudio/s2-pro
-
SGLang 推理: SGLang-Omni
单张 H200 GPU 上的生产性能:
-
实时因子 (RTF): 0.195
-
首字音频延迟: ~100ms
-
吞吐量: 3,000+ 声学 token/秒
对于大规模语音克隆,S2 将参考音频 token 放在系统提示词中。当在不同请求中重用同一语音时,SGLang 的 KV 缓存实现了 86.4% 的平均前缀缓存命中率 —— 使重复语音克隆的开销几乎可以忽略不计。
如何开始使用
-
在 APP 游乐场中尝试 —— fish.audio 直接支持 S2 行内标签。在脚本的任何位置放置
[方括号]并生成。 -
通过 API 集成 —— 可通过 Fish Audio API 使用。有关端点和身份验证的信息,请参阅 API 参考。
-
自行托管模型 —— 权重和推理栈已在 GitHub 和 HuggingFace 开源。
-
即将推出: Fish Audio APP 和 API 将支持多说话人对话生成。
-
有关行内标签语法、放置规则和提示的完整指南:→ 如何使用 Fish Audio S2 行内标签
-
如果你来自 S1,想了解这两个系统的关系:→ Fish Audio S1 情感标签 —— 完整指南
常见问题解答 (FAQ)
TTS 中的行内标签是什么?
行内标签是直接嵌入在文字转语音脚本中的简短指令,用于控制特定词或短语的朗读方式 —— 表达方式、情感、语速或音质。与应用于整个生成的全局语音设置不同,行内标签允许你指导句子中的各个瞬间。Fish Audio S2 使用 [方括号] 作为行内标签,并接受自由格式的自然语言描述。
什么是 Fish Audio S2?
Fish Audio S2 是来自 Fish Audio 的第二代 TTS 模型。它支持通过放置在脚本任何位置的 [方括号] 中的自然语言标签进行精细的行内控制,并在约 80 种语言的超过 1000 万小时音频上进行了训练。它在 GitHub 和 HuggingFace 上开源,并可通过 Fish Audio API 和 APP 游乐场使用。
行内标签在 S2 中如何工作?
在要受影响的词或短语之前立即放置 [方括号] 标签。你可以使用经过验证的标签(如 [窃窃私语]、[叹气] 或 [长停顿]),也可以编写任何自由格式的自然语言描述。标签适用于随后的所有内容,直到下一个标签或句子结束。
Fish Audio S2 开源吗?
是的。模型权重、微调代码和基于 SGLang 的推理引擎都在 github.com/fishaudio/fish-speech 和 huggingface.co/fishaudio/s2-pro 开源。
S2 支持多少种语言?
S2 在约 80 种语言上进行了训练。在 24 种语言的多语言基准测试中,S2 在 11 种语言中取得了最佳字错率,并在 17 种语言中取得了最佳说话人相似度,优于 MiniMax 和 ElevenLabs。
S2 是否支持 S1 的 () 圆括号语法?
不支持。S2 原生使用 [方括号]。当选择 S2 时,Fish Audio Web UI 会自动将 () 转换为 [],但如果你直接使用 API,请使用方括号。
S2 支持多说话人对话吗?
多说话人生成即将登陆 Fish Audio APP 和 API。模型原生支持该功能 —— 请关注后续发布。
Fish Audio S1 和 S2 有什么区别?
S1 使用 (圆括号) 中预设的情感标签固定词汇,且放在句首。S2 使用 [方括号] 中的开放域自然语言标签,可以出现在脚本的任何位置 —— 句中、词间或句首。S2 还接受自由格式描述,而非封闭的关键词列表,因此你不受预定义情感的限制。有关完整分析,请参阅 Fish Audio S1 情感标签指南。
Fish Audio S2 可以取代 SSML 吗?
对于大多数表现力用例,是的。Fish Audio S2 可以通过自然语言行内标签复制许多 SSML 风格的控制 —— 你无需编写像 <prosody rate="slow"> 这样的 XML 标记,而是直接在脚本中编写 [说话缓慢]。像 [耳语]、[长停顿] 和 [愤怒] 这样的标签涵盖了最常见的 SSML 表现功能,而无需专门的标记语言知识。
Fish Audio S2 行内标签与其他 TTS 系统兼容吗?
不兼容。Fish Audio S2 的行内标签语法是该模型特有的。其他 TTS 系统使用 SSML 或其专有格式。然而,即使语法不同,潜在的表现力概念(停顿、音调转换、语音暗示)在不同系统之间在概念上是可以转换的。
相关资源:

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
阅读Sabrina Shu的更多内容







