如何使用 AI 变声器 — 内容创作者完整指南

了解如何使用 AI 变声器在几秒钟内将任何录制的音频转换为新声音 — 无需下载。本指南包含分步说明以及针对创作者、播客和视频制作人的实际应用案例。
AI 变声器可以将任何录制的音频转换为完全不同的声音 — 对于内容创作者来说,这改变了一切。
想象一下,在午夜疲惫不堪、嗓音嘶哑时录制了一段旁白,然后在早餐前将其转换成清晰、圆润的旁白声音。或者在不聘请任何配音演员的情况下,用角色的声音为视频配音。或者独自一人构建一个拥有多个独特声音的完整播客。
这并非未来的功能。这是当今 AI 变声器已经可以实现的操作。在本指南中,我们将向您展示具体的操作方法 — 特别是 Fish Audio 的 Voice Changer,它完全在浏览器中运行,并拥有超过 2,000,000 个社区声音模型库。
→ 免费试用 Fish Audio Voice Changer — 无需下载,无需信用卡
什么是 AI 变声器?
AI 变声器是一种工具,它可以获取现有的音频录音,并将说话者的声音转换为不同的声音 — 在保留原始语音的时间点、情感和节奏的同时,完全替换人声特征。
这与移调器或音频滤镜有着本质的区别。移调器是通过机械方式提高或降低频率。而 AI 变声器会分析输入音频的完整声学特征(音色、共鸣、说话模式),并使用基于真人语音训练的目标声音模型重建输出。
结果是:文字、节奏和情感仍然属于您。但声音变成了别人的。
简单来说:AI 变声器让您保留所说的内容和表达方式,同时改变听起来像谁的声音。
AI 变声器 vs. 语音克隆:有什么区别?
这两个术语经常被混淆,但它们描述的是完全不同的工作流程:
AI 变声器 (AI Voice Changer) — 您已经录制了音频。您知道想说什么以及想怎么说。您只是想要一个不同的声音来传达这些文字。变声器会获取您现有的录音并将其转换为目标声音。
语音克隆 (Voice Cloning) — 您想要捕捉并复制特定的声音本身。您上传一段声音的参考音频,AI 会构建一个持久、可重复使用的模型,您可以在未来的项目中反复使用该模型 — 包括文本转语音生成。
最简单的理解方式:
-
变声器 = 我有音频。我想更换其中的声音。
-
语音克隆 = 我想构建一个可以反复使用的声音模型。
对于大多数创作者来说,当您已经有录音并需要改变声音时,变声器是更快、门槛更低的工具。而当您需要该声音在未来的数十个输出中保持一致时,语音克隆则是正确的选择。
Fish Audio 同时提供这两种功能 — 并且它们被设计为可以在同一个工作流中协同工作。
如何使用 Fish Audio Voice Changer(分步指南)
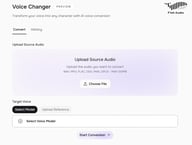
Fish Audio 的 Voice Changer 完全基于浏览器 — 无需安装软件、插件,也无需配置。以下是完整的工作流程:
第 1 步:打开变声器
访问 fish.audio/app/voice-changer。您将进入带有音频上传区域的“转换”标签页。
第 2 步:上传源音频
点击 选择文件 并上传您想要转换的录音。支持的格式包括:WAV、MP3、FLAC、OGG、M4A、OPUS — 每个文件最大支持 100MB。
这是您的原始输入:旁白素材、播客片段、叙述草稿 — 任何单人声的音频录音。
💡 为了获得最佳效果:请使用清晰、干净的音频 — 无背景音乐、无混响、无叠加的人声。AI 是在转换声音,而不是在清理声音设计。如果您的源音频有背景噪音,请考虑先使用 Fish Audio 的 Audio Separation 工具进行处理。
第 3 步:选择目标声音
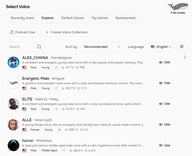
在“目标声音”下,您有两个选项:
-
选择模型 — 浏览 Fish Audio 拥有超过 2,000,000 个社区声音模型的库。按语言、性别、风格或使用场景进行筛选。这是获得完全不同声音的最快途径。
-
上传参考 — 有特定的声音目标吗?上传该声音的一段参考音频剪辑(最长 10 分钟),AI 将使用它作为转换目标。这是使 Fish Audio 脱颖而出的一项功能。(请确保您拥有上传的任何参考音频的权利 — 见下方的负责任使用说明。)
第 4 步:开始转换
点击 开始转换。AI 将处理您的文件并生成转换后的输出。
第 5 步:下载音频
转换完成后,将新音频下载为 MP3 文件 — 您可以将其直接拖入视频编辑器、播客软件或 DAW 中。
您的转换记录保存在 历史记录 标签页下,因此您可以重新查看并下载之前的任务,而无需重新开始。
→ 打开 Fish Audio Voice Changer 并转换您的第一个文件
⚠️ 负责任使用:在使用“上传参考”选项时,您必须拥有或获得使用该声音的明确许可。切勿在未经他人同意的情况下上传他人的录音。Fish Audio 平台专为使用自己声音或经过妥善授权的音频的创作者而设计。滥用变声技术(包括冒充或创建误导性内容)是 Fish Audio 服务条款所禁止的,并可能违反相关法律。
费用是多少?
Fish Audio Voice Changer 适用于所有方案,包括免费方案。
免费账户包含每月积分分配。Voice Changer 的计费标准为 每分钟 3,000 积分,按秒计费 — 因此,30 秒的剪辑消耗 1,500 积分,60 秒的剪辑消耗 3,000 积分。
对于高工作量的工作流(例如转换多个剧集、长篇叙述或批量视频配音),付费方案可解锁更多积分。请参阅 Fish Audio 定价 了解当前的方案详情。
内容创作者的 4 个真实应用案例

1. YouTube 旁白:无需重新录制即可修复糟糕的素材
每个 YouTuber 都有过这种感觉:你录制了一段扎实的素材,内容精炼,节奏准确 — 但那天你的声音听起来平淡、沉闷,或者状态不对。旧的解决方案是安排另一次录音。新的解决方案是使用变声器。
将现有的音频通过 Fish Audio Voice Changer 处理,选择一个符合你品牌风格的模型进行转换。输出结果保留了你精确的时间点和表达方式 — 每一个停顿,每一个强调 — 且声音更加清晰、一致。
这也开启了一种大多数创作者尚未考虑的有意识的预制作流程:快速且随意地录制所有草稿音轨,因为你知道稍后会进行转换。你不再担心自己的声音状态,而开始专注于内容本身。变声器成为了一种制作工具,而不仅仅是修复工具。
对于具有特定人设或角色声音的频道,变声器让你无论录音条件如何,都能在每次上传中保持一致的声音。
2. 播客制作:在每一集中保持一致的品牌声音
播客听众对音频的一致性非常敏感。如果主持人第一集听起来神采奕奕,而第 47 集中听起来疲惫不堪,这会产生微妙的摩擦感,随着时间的推移会削弱听众的信任。
变声器解决了这个问题,它可以让你将每一集的音频转换为一致的目标声音模型(你的“广播音”),无论你录音当天的状态如何。其结果是让你的所有往期节目都拥有统一的收听体验。
对于叙事类播客和广播剧,应用案例更为广泛:独立创作者可以为剧本中的每个角色配音,然后将每个角色的台词转换为独特的声音模型。零配音预算,实现多角色演出。
3. 视频配音:无需重新录制即可更换人声
传统的配音(更换视频中的声音)需要预订录音室、聘请配音人才,并花费数小时进行同步。AI 变声器将整个工作流程压缩到了几分钟内。
用你自己的声音录制一段与视频同步的草稿音轨。然后使用 Fish Audio Voice Changer 将其转换为目标声音。时间点会锁定在你原始的表达上,因此同步会自动保持。
这对于本地化工作流特别有用:录制一次,即可转换为多种角色声音或区域语调。配合 Fish Audio 的 Text to Speech 处理脚本和 Audio Separation 隔离现有音轨,你就可以在一个平台上拥有完整的配音管线。
4. 隐私和人设构建
并非每个创作者都想在互联网上使用真实声音 — 出于隐私原因、人设构建需要,或者仅仅是因为他们创建的角色声音与本人不同。
变声器支持创作者与人设之间的清晰分离:你用自己的声音自然录制,捕捉真实的表达和能量,然后在后期转换为人设的声音。你的真实声音从未出现在最终内容中。表演是真实的,而身份保持私密。
为什么 Fish Audio Voice Changer 与众不同
2,000,000+ 声音模型 vs 其他产品
以下是 Fish Audio 的声音模型库与领先替代方案的对比:
| Fish Audio | ElevenLabs | Kits.AI | |
|---|---|---|---|
| 声音模型库 | 2,000,000+ | 10,000+ | 数百个(专注于音乐) |
| 上传参考音频作为目标 | ✅ | ✅ | ❌ |
| 主要使用场景 | 通用内容创作 | 通用内容创作 | 音乐制作 |
| 无需下载 | ✅ | ✅ | ✅ |
| 模型质量基准 | S2 Pro (公开数据) | 可查阅 | 未发布 |
数据截至 2026 年 4 月。可能会有变动 — 请在各供应商网站上核实当前方案。
Fish Audio 社区模型库的规模并非微小的差距,而是质的飞跃。拥有涵盖数百种语言、口音、风格和角色的 200 万种声音,你不是在缩减后的候选名单中挑选,而是在真正的目录中搜索。
上传任何声音作为目标
大多数 AI 变声器只提供固定的库供你选择。Fish Audio 的 上传参考 功能颠覆了这一模式:你提供声音,AI 进行转换。
这意味着如果你心中有特定的声音 — 符合你品牌的音调、你一直在开发的某个角色、或者你听过并想要匹配的某种风格 — 你将不再受限于任何库的内容。你来设定目标。
由 Fish Audio S2 Pro 驱动
其核心运行的是 Fish Audio S2 Pro 模型 — 该模型在 Seed-TTS 基准测试评估中实现了最低的词错率 (Word Error Rate),优于所有测试系统,包括闭源竞争对手。在音频图灵测试 (Audio Turing Test) 中,S2 Pro 得分为 0.515,超过 Seed-TTS 24%,超过 MiniMax-Speech 33%。
如需深入了解技术细节,Fish Audio S2 技术报告 已在 arXiv 上公开发布。
在实践中,这意味着你转换后的音频听起来非常自然。这种转换保留了情感细微差别 — 例如带着紧迫感说出的句子与带着冷静说出的同一句之间的区别 — 而低质量模型则会使这些特征完全变平。
完整音频工作流的一部分
Voice Changer 并非孤立存在。Fish Audio 的完整平台还包括:
-
Voice Cloning — 从短样本构建可重复使用的声音模型
-
Text to Speech — 用任何声音从任何脚本生成语音
-
Story Studio — 多角色叙事音频制作
-
Audio Separation — 从任何音频文件中分离人声
-
Speech to Text — 高准确度转写音频
套件中的每个工具都可以互相配合。一个典型的制作流程可能是:Audio Separation(分离人声)→ Voice Changer(转换声音)→ 下载并同步。无需切换平台,无需在文件格式间折腾。
接下来有什么计划?
Fish Audio Voice Changer 已经上线 — 但它仍在不断扩展。Voice Changer 的 API 访问正在开发中,这将允许开发者和制作团队将语音转换直接集成到他们自己的工具、流水线和应用程序中。
如果您正在构建可以使用程序化语音转换的产品(如自动化配音管线、内容本地化工具、语音驱动的应用程序),请关注 Fish Audio Weekly Update 获取最新信息。

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
阅读Sabrina Shu的更多内容






