多角色文字转语音 — 完整多发言人指南 (Fish Audio)

单声音 TTS 在对话、有声读物和播客中显得平淡。本指南将向您展示如何在 Fish Audio 上查找和组织声音,然后利用 TTS 和 Story Studio 中的多发言人功能制作自然的多角色音频 —— 无需传统的录音流程。
2026 年 3 月 | Fish Audio 多发言人 TTS 现已在 S2 Pro 上推出
目录
- 什么是多发言人文字转语音?
- 第 1 步 — 通过 Discovery 查找合适的声音
- 第 2 步 — 在文字转语音中使用多发言人
- 第 3 步 — 在 Story Studio 中使用多发言人
- TTS vs Story Studio — 您应该使用哪一个?
- 应用场景 — 您可以用多发言人 TTS 制作什么?
- 从脚本到音频 — 一站式完成
- 关于多发言人 TTS 的常见问题
大多数文字转语音工具只提供一种声音。一个叙述者。从头到尾一种语调。对于单发言人的解说视频,这没问题。但一旦您的脚本涉及两个角色对话、主持人与嘉宾,或者具有不同角色的故事 —— 单一的声音会让对话变得平淡、单调。听众很快就会失去兴趣。
多角色文字转语音解决了这个问题。为每个发言人分配不同的 AI 声音,控制他们之间的停顿时间,结果就是听起来像真实的对话。Fish Audio 作为一个完整的文字转语音对话生成器 —— 涵盖了从声音发现到多章节导出的所有功能。本指南将带您了解完整的工作流程:如何发现和组织声音,如何将多发言人功能用于短内容的文字转语音工具,以及如何在 Story Studio 中扩展到完整规模的制作。
什么是多发言人文字转语音?
多发言人文字转语音是一种 TTS 工作流程,其中脚本的不同部分被分配给不同的 AI 声音 —— 每个声音都有自己的语调、性别、年龄和说话风格 —— 然后生成为一个连续的音频输出。
传统的 TTS 工具是围绕单一叙述模型构建的:一个声音,一个文本输入,一个音频文件。这种设计适用于单人叙述的有声读物、配音或公告。但在涉及对话时,它就完全失效了。要使用传统工具制作双人对话,您必须分别生成每个发言人的音频,然后在编辑器中手动拼接 —— 调整时间、匹配音量,并希望转换处听起来不像两个不同的录音。
问题不仅仅在于额外的步骤。如果没有专门的控制,发言人之间的停顿时间几乎不可能调整正确。真实的对话是有节奏的:回应前的沉默、打断时的轻微重叠、回答难题前较长的停顿。如果没有对发言人间隙的精确控制,即使配音再好,对话听起来也会很生硬。
多发言人 TTS 工具同时解决了这两个问题。每个发言人都有自己的声音和自己的文本块。发言人之间的间隙是可调的。最终输出是一个连贯的音频文件 —— 时间节奏已经内置其中。
多发言人文字转语音允许您:
- 为脚本中的每个发言人分配不同的 AI 声音
- 控制每个发言人之间的时机和停顿
- 将整个对话生成为一个连续的音频文件
- 从两人对话扩展到完整演员阵容 —— 无需额外的导出或手动编辑
第 1 步 — 通过 Discovery 查找合适的声音
在构建多发言人项目之前,您需要声音。Fish Audio 的 Discovery 页面是您查找声音的地方 —— 库中有成千上万种声音,筛选工具至关重要。
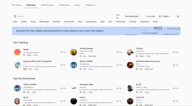
搜索和筛选
Discovery 页面顶部有一个搜索栏,下方是快速筛选标签,右侧是排序和语言控制。
如果您已经知道要寻找什么,可以按名称搜索。按“推荐”或“趋势”排序可以发现其他创作者常用的声音。语言过滤器会将整个库筛选为针对您目标语言训练的声音。
顶部的快速筛选标签涵盖了最常见的属性 —— 男性、女性、年轻人、中年人、叙述、社交媒体、深沉、柔和、专业、戏剧性、神秘、动漫 —— 并且您可以组合使用。选择“女性 + 年轻人 + 叙述”将立即缩小范围,找到符合该特征的声音。

为了获得更多控制,请打开筛选面板(右上角的滑块图标)。这为您提供了:
- 语言 — 缩小到特定语言,支持多语言匹配
- 标签 — 声音创建者添加的自由形式标签
- 性别 — 男性、女性、中性
- 年龄 — 年轻人、中年人、老年人
- 应用场景 — 对话、叙述、角色声音、社交媒体、教育、广告等
- 声音特质 — 深沉、低沉、中等、高亢、柔和、明亮以及 48 个以上的额外描述词
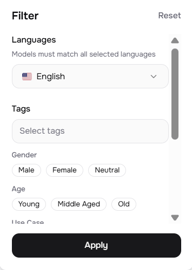
对于多发言人项目,“应用场景”和“声音特质”筛选器特别有用。如果您正在构建播客风格的对话,您可能需要一个“对话 + 柔和”的声音和一个“叙述 + 深沉”的声音 —— 区分度足够大,听众无需查看文稿即可分辨出他们。
点赞、书签以及保存到合集
当您找到想要再次访问的声音时,有几种保存方式。 搜索结果中每个声音卡片上的心形图标是快速点赞 —— 它会将声音添加到您的“点赞”选项卡中以供日后参考。
为了更稳妥的保存,请打开声音的详情页面并点击“书签”。书签标记的声音出现在“书签”选项卡中,与您的点赞分开,并且可以在 TTS 和 Story Studio 的声音选择器中直接访问。
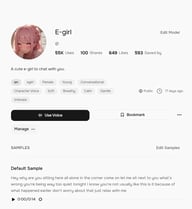
对于项目级别的组织,合集是最强大的选项。点击顶部导航栏中的合集,然后点击创建合集来设置一个命名的组 —— 例如,“播客用途”或“有声读物项目 A”。给它一个标题和描述,然后点击“创建”。

要将声音添加到合集,请打开声音的详情页面,点击书签按钮旁边的三点菜单 (⋯),然后选择添加到合集。如果您已经创建了合集,它会出现在下拉菜单中 —— 点击即可添加。
当您在 TTS 或 Story Studio 中工作时,合集的优势就体现出来了。当您打开选择声音面板时,您的合集将作为顶部的选项卡出现 —— 紧邻“最近使用”、“探索”、“默认声音”、“我的声音”和“书签”。无需在每次使用时从头搜索,您的项目声音已经分组就绪。
第 2 步 — 在文字转语音中使用多发言人
Fish Audio 的文字转语音工具支持在单次生成中使用多个发言人。它是短到中等长度内容的正确选择 —— 对话片段、广告、简短的播客开场白、演示脚本,以及任何您需要快速、精美输出且无需章节管理的内容。如果您还没有找到合适的声音,请先浏览 Discovery 库。
访问 fish.audio/app/text-to-speech/。
设置您的第一个发言人
当您打开 TTS 时,您会看到一个带有声音选择器的单个文本块。点击声音名称打开选择声音面板并选择您的第一个发言人。在文本块中输入或粘贴第一个发言人的台词。
您还可以使用行内情感标签来塑造表达方式 —— [sad](悲伤)、[emphasis](强调)、[excited](兴奋) —— 直接放置在受影响词语之前的文本中。
添加更多发言人
点击第一个文本块下方的 + 添加发言人。会出现一个新的文本块,带有其独立的声音选择器。为该发言人选择不同的声音,输入其台词,这两个块将按在屏幕上出现的顺序生成为一个连续的音频文件。
您可以添加的发言人数量没有上限。每个文本块都是独立的:不同的声音、不同的文本,如果需要还可以有不同的情感标签。实际上,大多数对话项目使用 2-4 个不同的声音效果较好 —— 既有足够的样性保证清晰,又不会变得难以跟上。 在右侧面板中,您可以在生成之前微调音量、速度、响度归一化和文本规范化(这能提高数字、货币和类似格式文本的朗读准确性)。
字符限制以及何时切换到 Story Studio
请留意屏幕底部的字符计数器。限制取决于您的计划 —— 请查看 Fish Audio 价格和计划 了解您级别的具体限额。对于短篇和中篇内容,TTS 是更快速、更简单的工作流程。但如果您正在制作更长篇的内容 —— 完整的有声读物章节、多环节播客、游戏对话脚本 —— Story Studio 能为您提供真正需要的工具。
第 3 步 — 在 Story Studio 中使用多发言人
Story Studio 是专为长篇音频制作而构建的。TTS 优化了快速生成,而 Story Studio 则为您提供了一个结构化环境,按块对多个声音进行排序 —— 并能精确控制发言人之间的时机,以及针对复杂项目的章节组织。每个块都使用其分配的声音独立生成,最终导出时将它们缝合成一个连续的文件。 访问 fish.audio/app/story-studio/。
创建新项目
点击 Story Studio 主屏幕上的 + 项目。创建项目对话框将打开,包含以下设置:
- 项目名称 — 为您的项目命名
- 默认声音 — 默认分配给新文本块的声音(您可以按块更改)
- 语音模型 — 目前为 S2 Pro(最新)
- 文本规范化 — 启用后,可提高数字、货币、日期和类似文本的朗读准确性
- 响度归一化 — 归一化各文本块的音量水平,以获得一致的输出
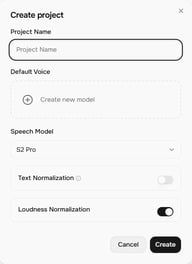
点击创建打开项目编辑器。
添加文本块并切换声音
您的项目会开启一个默认章节,并且第一个文本块已经就位。第一个发言人的声音以彩色头像的形式显示在每个块的左侧。
要添加新发言人的台词,请点击任何现有文本块下方的 + 按钮。一个新的文本块会出现。点击新块左侧的彩色声音头像打开选择声音面板并分配不同的声音。在块中输入第二个发言人的台词。
对脚本中的每一次交流重复此操作。每个文本块代表一个发言人的轮次。右侧面板显示了项目中使用到的声音 —— 这是当前分配给所有文本块的声音实时列表,方便您一目了然地管理您的演员阵容。
精细调整发言人间停顿
在每对文本块之间,您会看到一个显示当前间隙的小停顿气泡 —— 例如 0.35s。点击它即可调整该特定发言人对之间的停顿持续时间。
这是 Story Studio 实现对话真实感最重要的功能之一。人类对话不是一系列完美衔接的语句。回答前的片刻沉默代表思考时间。在情感回应前较长的停顿会增加分量。调整好这些间隙是决定音频听起来是制作出来的还是真实发生的关键。即使是 0.2-0.5 秒的调整,也能显著改变对话的自然程度 —— 值得单独调整每一次交流,而不是将所有间隙都保持在默认值。单独调整每个块间停顿,以匹配场景节奏。
为长项目添加章节
在编辑器的左侧,您会看到章节面板。默认情况下,每个项目都以一个“默认章节”开始。点击 + 即可添加新章节。
章节允许您将长项目分解为可导航的部分 —— 每章一个有声读物部分,每节一个播客环节,或者每个游戏脚本场景。每个章节都有自己的文本块序列,并可以独立处理。最终导出时会按顺序将所有章节合并为一个输出。
对于超过几百字对话的任何内容,章节是您保持 Story Studio 项目井然有序且易于编辑的方式。
TTS vs Story Studio — 您应该使用哪一个?
| 文字转语音 (TTS) | Story Studio | |
|---|---|---|
| 多发言人方法 | 原生(S2 Pro 模型层级) | 顺序文本块生成 |
| 字符限制 | 取决于订阅计划 | 无限制(多章节) |
| 发言人数量 | 最多 5 个 | 无限制 |
| 发言人间停顿控制 | ❌ | ✅ 精确,按块控制 |
| 章节管理 | ❌ | ✅ |
| 时间轴视图 | ❌ | ✅ |
| 最佳用途 | 短对话、广告、演示 | 有声读物、播客、游戏脚本、长篇制作 |
核心技术区别:TTS 使用 S2 Pro 的原生多发言人能力 —— 多个发言人在单次生成中由模型层级处理。Story Studio 通过将分别生成的文本块(每个块分配了自己的声音)按顺序排列成一个连续文件来实现多发言人输出。
如果您正在生成一段包含两个发言人的 30 秒广告或简短的对话剪辑,请在 TTS 中开始 —— 它更快且无需项目设置。如果您的脚本较长,涉及多次交流,或者需要精确控制发言人之间的时机,请改用 Story Studio。
应用场景 — 您可以用多发言人 TTS 制作什么?
多角色的有声读物
单叙述者有声读物在非虚构类作品中表现良好。对于包含对话的虚构作品,单一声音阅读所有角色会变得难以跟进。利用多发言人 TTS,场景中的每个角色都有自己的声音 —— 一个角色声音深沉苍老,另一个声音年轻充满活力。Story Studio 的章节结构直接对应书籍章节,使得无需传统选角和录音流程即可制作全长作品变得触手可及。
播客风格的对话
双主持人播客格式是现存最知名的音频结构之一。利用用于对话的多发言人 AI 语音生成器,您可以从书面脚本中制作这种格式 —— 为每个主持人分配一个声音,并控制模拟自然轮换交流的停顿。这对于希望在不安排录音环节的情况下定期制作音频内容的创作者特别有用。
在线学习和培训内容
当教学内容以对话而非独白形式呈现时,参与度会显著提高。师生交流、情景模拟或问答格式都可以通过两个或更多声音进行编写和制作 —— 帮助学习者通过对话而非被动叙述来处理信息。
游戏对话和角色声音
游戏脚本通常包含跨多个角色的成百上千行内容。将 Story Studio 用作多角色语音生成器,游戏开发商和叙事设计师可以为原型、演示或正式制作生成配音对话 —— 确保每个 NPC 在每一行台词中都保持一致的声音,而无需传统的录音流程。
从脚本到音频 — 一站式完成
制作多角色音频过去意味着预订配音演员、协调录音时间,并花费数小时进行后期制作以拼接素材。有了多发言人 TTS,整个工作流程缩短为一个环节:在 Discovery 中寻找声音,将其组织到合集中,逐块构建脚本并导出。
对于短内容,文字转语音 让您在几分钟内达成目标。对于更长篇的制作 —— 有声读物、播客系列、游戏对话 —— Story Studio 为您提供了结构和时机控制,以制作出听起来像是由真人演出的作品。

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.






