Fish Audio S2! Controle de Voz por IA de Grão Fino ao Nível da Palavra

O Fish Audio S2 traz tags inline de domínio aberto, controle de voz por IA ao nível da palavra e suporte a 80 idiomas para TTS expressivo. Veja como ele funciona com exemplos reais.
Março de 2026 | Fish Audio S2 já está disponível
Índice
-
O Que É o Fish Audio S2?
-
O Que o S2 Pode Fazer — Em 30 Segundos
-
Tags Inline no Fish Audio S2
-
Exemplos Reais
-
Desempenho do S2 — Resultados de Benchmark
-
80 Idiomas
-
Código Aberto
-
Como Começar
-
FAQ
A maioria das ferramentas de voz por IA oferece uma voz e permite ajustar o tom em um nível global — mais calmo, mais enérgico, um pouco mais caloroso. O Fish Audio S2 adota uma abordagem diferente para o TTS expressivo. Você direciona a voz ao nível da palavra, em linguagem simples, diretamente dentro do seu roteiro. Se você já está familiarizado com as tags de emoção do Fish Audio no S1, o S2 expande essa ideia drasticamente com controle inline de domínio aberto.
É assim que isso se parece na prática:
Eu achei que estava pronto. [voz falhando] Eu não estava.
[voz suave] Não tenha pressa. Não há urgência.
Essa foi a terceira vez esta semana. [suspiro] Eu realmente preciso consertar isso.
Sem painéis de configurações. Sem SSML. Sem pós-produção. Você escreve a direção no texto, e o S2 a renderiza.
Resumo Rápido
O Fish Audio S2 introduz tags inline para controle de TTS expressivo ao nível da palavra.
-
Tags de domínio aberto escritas em linguagem natural — sem vocabulário fixo
-
Posicionamento no meio da frase para transições precisas de tempo e entonação
-
Suporte para aproximadamente 80 idiomas
-
Pesos do modelo, código de fine-tuning e pilha de inferência em código aberto
Em vez de ajustar configurações globais de voz, o S2 permite que você direcione a entrega diretamente dentro do seu roteiro.
O Que É o Fish Audio S2?
https://www.youtube.com/watch?v=NIcXTOSdOXc
O Fish Audio S2 é o modelo TTS de segunda geração da Fish Audio. Ele foi treinado em mais de 10 milhões de horas de áudio em aproximadamente 80 idiomas e introduz o controle por tags inline: instruções em linguagem natural incorporadas diretamente no seu roteiro em qualquer posição, oferecendo uma direção detalhada sobre como a fala é entregue ao nível da palavra ou frase.
O modelo tem código aberto no GitHub e no HuggingFace, e está disponível através da API e do APP da Fish Audio.
O Que o S2 Pode Fazer — Em 30 Segundos
As tags inline do S2 são instruções entre colchetes colocadas em qualquer lugar do seu texto:
[sussurrando] Não deixe que eles te ouçam.
Ela colocou a pasta sobre a mesa. [pausa longa] Então ela olhou para cima.
[rindo] Eu não tenho a menor ideia do que acabou de acontecer.
As tags afetam o que vem depois delas. Coloque a tag no ponto exato onde a mudança deve ocorrer — não necessariamente no início da frase, a menos que seja lá onde você a deseja.
Você não está escolhendo de um menu fixo. Você escreve a descrição, e o S2 a interpreta:
[o tom calmo e medido de alguém que já fez isso mil vezes]
Por favor, coloque as mãos onde eu possa vê-las.
[excessivamente alegre, claramente forçando]
Tudo está completamente bem. Totalmente bem.
Se você consegue descrever para um dublador, o S2 pode tentar executar.
Tags Inline no Fish Audio S2
As tags inline são o principal mecanismo de controle no Fish Audio S2. São instruções em linguagem natural entre [colchetes] que você incorpora diretamente no seu roteiro para direcionar como a fala é entregue — em qualquer palavra, em qualquer ponto.
Sintaxe
Coloque uma tag entre [colchetes] imediatamente antes da palavra ou frase que ela deve afetar. As tags podem ir a qualquer lugar — início, meio ou fim de uma frase.
[sussurrando] Eu não queria entrar.
Eu não queria entrar [sussurrando] lá.
Ambos funcionam. O primeiro sussurra a linha inteira. O segundo sussurra a partir de "lá". O posicionamento é o significado.
Escreva Tags no Seu Idioma
As tags não precisam ser em inglês. O S2 entende instruções em linguagem natural em 80 idiomas — então você pode escrever tags no mesmo idioma do seu roteiro.
日本語 (Japonês)
[囁き声で] 誰にも聞かせないで。
[ため息をついて] もう一度やり直そう。
中文 (Chinês)
[低声说] 不要让他们听见。
[叹气] 我真的不知道该怎么办了。
español (Espanhol)
[susurrando] No dejes que te escuchen.
[enojado] ¿Cómo pudiste hacer eso?
한국어 (Coreano)
[속삭이며] 아무도 모르게 해줘.
[화나서] 어떻게 그럴 수가 있어.
A mesma lógica se aplica: coloque a tag imediatamente antes da palavra ou frase que ela deve afetar, em qualquer idioma que pareça natural para o seu roteiro.
Tags Bem Testadas
O S2 aceita qualquer descrição em linguagem natural, mas estas tags produzem resultados consistentemente fortes de imediato. As tags se aplicam a partir do ponto em que aparecem até a próxima tag ou o fim da frase.
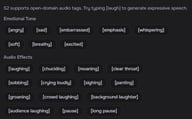
Respiração e Reações
| Tag | Efeito |
|---|---|
[breathing] | Adiciona som de respiração audível |
[sigh] | Um suspiro audível antes de falar |
[gasp] | Um suspiro de surpresa ou choque |
[clears throat] | Som de pigarro |
Sons Vocais
| Tag | Efeito |
|---|---|
[laughing] | Fala enquanto ri |
[chuckling] | Risadinha leve durante a fala |
[crying] | Fala com voz de choro |
[panting] | Fala ofegante |
[mumbling] | Fala de forma menos clara, resmungando |
Ritmo
| Tag | Efeito |
|---|---|
[long pause] | Insere uma pausa significativa |
[short pause] | Insere uma breve hesitação |
[speaking slowly] | Diminui a velocidade da fala |
[speaking fast] | Aumenta a velocidade da fala |
Estilo de Voz
| Tag | Efeito |
|---|---|
[whispering] | Reduz o volume para um sussurro |
[shouting] | Aumenta a intensidade para um grito |
[soft voice] | Tom de voz suave e gentil |
[loud voice] | Tom de voz alto e projetado |
Emoção
| Tag | Efeito |
|---|---|
[angry] | Entrega agressiva ou irritada |
[happy] | Tom brilhante e alegre |
[sad] | Tom pesado e melancólico |
[excited] | Entrega de alta energia |
[scared] | Voz trêmula ou temerosa |
Outros
| Tag | Efeito |
|---|---|
[high pitch] | Aumenta o tom da voz |
[low pitch] | Diminui o tom da voz |
Descrições de Forma Livre
Além da lista de tags acima, o S2 aceita descrições abertas. Escreva o que você diria a um dublador:
[falando devagar, quase hesitante]
[tom de transmissão profissional]
[exausto, final de um turno muito longo]
[tom mais agudo]
[voz rouca de tanto chorar, tentando parecer normal]
Como o S2 é treinado em descrições abertas, novas tags generalizam bem — você não está limitado aos exemplos vistos durante o treinamento.
Combinando Tags
Encadeie tags ao longo de um trecho para criar mudanças na entrega:
[voz suave] Eu não tinha certeza do que dizer. [pausa longa] [voz alta] Mas então eu percebi.
Use tags de reação entre frases para transições naturais:
Essa foi a terceira vez esta semana. [suspiro] Eu realmente preciso consertar isso.
Combinar uma reação com uma tag de emoção ancora o sentimento fisicamente:
[suspiro] [triste] Eu simplesmente não sei mais.
Exemplos Reais
Narração de Audiolivro
[NARRADOR, baixo e lento] Capítulo Nove. A Última Manhã. O apartamento parecia diferente naquele dia — menor, de alguma forma.
SARAH: [voz rouca de tanto chorar, tentando parecer normal] Eu fiz café. Você quer um pouco?
DANIEL: [pausa longa, então calmamente] Quero. Obrigado.
Podcast

Hoje estamos analisando algo que passei três meses tentando entender.
[risadinha] Eu continuei errando. Meu produtor pode confirmar isso.
Diálogo de Jogo
VILÃO: [calmo, quase entediado, como se esta conversa estivesse abaixo dele] Você veio de tão longe.
VILÃO: [fúria repentina, voz tensa] Onde está?
VILÃO: [compostura retornando, perigosamente silencioso] Você realmente achou que isso funcionaria?
HERÓI: [exausto, mas firme] Todas as vezes.
Agente de Voz

[amigável, caloroso] Olá — obrigado por ligar. Como posso te ajudar hoje?
[empático, sem pressa] Sinto muito em ouvir isso. Deixe-me abrir os dados aqui.
[confiante] Boas notícias — consigo ver exatamente o que aconteceu e vou resolver isso para você agora mesmo.
Dicas para Obter os Melhores Resultados
As tags inline do S2 são expressivas, mas o quanto elas aparecem depende de como você as usa — e com qual voz você está trabalhando. Estas dicas são baseadas em testes práticos.

Combine tags físicas com uma tag de emoção. Tags como [ofegante], [sussurrando] e [gritando] funcionarão sozinhas, mas o efeito pode parecer monótono sem um contexto emocional. Combiná-las com uma tag de emoção produz resultados mais consistentes e naturais:
[ofegante] [cansado] Estou correndo há vinte minutos.
[sussurrando] [assustado] Não se mexa. Não faça nenhum som.
[gritando] [irritado] Eu te disse que isso ia acontecer!

Sempre siga uma tag descritiva com texto. Uma tag descritiva como [voz rouca de tanto chorar, tentando parecer normal] precisa de uma linha para falar — não a deixe sozinha. A tag direciona a entrega do que vem a seguir; sem texto depois dela, o resultado pode ser imprevisível.
✅ [voz rouca de tanto chorar, tentando parecer normal] Eu fiz café. Você quer um pouco?
❌ [voz rouca de tanto chorar, tentando parecer normal]
Teste sua voz antes de roteirizar. Diferentes vozes respondem à mesma tag com intensidades diferentes. Uma voz com um registro naturalmente calmo mostrará mudanças mais sutis do que uma voz expressiva. Se uma tag não estiver soando como esperado, tente uma voz diferente antes de ajustar a própria tag — o problema geralmente é a voz, não a instrução.
Comece simples, depois adicione camadas. Um único [suspiro] ou [pausa longa] bem posicionado pode mudar uma frase completamente. Adicione mais tags apenas quando a versão simples não for suficiente. O excesso de tags pode entrar em conflito consigo mesmo.
Em breve: escolha sua favorita entre várias gerações. O S2 suportará a geração de múltiplas versões da mesma linha de uma só vez, para que você possa comparar e escolher a entrega que melhor se adapta — semelhante a como as ferramentas de geração de imagem permitem selecionar de um lote. Isso tornará significativamente mais fácil encontrar a performance certa sem ajustar manualmente as tags todas as vezes.
Desempenho do S2 — Resultados de Benchmark
O controle inline do S2 não é apenas um recurso de UX — ele também se correlaciona com um forte desempenho em benchmarks públicos de fala. Esses benchmarks medem a naturalidade da fala, a precisão da pronúncia e a capacidade de seguir instruções em sistemas TTS modernos.
No Audio Turing Test, o S2 obteve 0,515 — superando o Seed-TTS em 24% e o MiniMax-Speech em 33%. No EmergentTTS-Eval, ele alcança resultados particularmente fortes em paralinguística (91,61% de taxa de vitória), o que reflete diretamente a qualidade da execução das tags inline.
No Seed-TTS Eval, o S2 alcança a menor taxa de erro de palavras (WER) entre todos os modelos avaliados, incluindo sistemas de código fechado: Qwen3-TTS (0,77% / 1,24%), MiniMax Speech-02 (0,99% / 1,90%) e Seed-TTS (1,12% / 2,25%).
Fonte: Post de lançamento do Fish Audio S2 por Shijia Liao, Cientista-Chefe
80 Idiomas
O S2 é treinado em mais de 10 milhões de horas de áudio abrangendo aproximadamente 80 idiomas. No conjunto de testes multilíngue da MiniMax, que cobre 24 idiomas, o S2 alcança a melhor taxa de erro de palavras em 11 idiomas e a melhor similaridade de locutor em 17 — superando tanto o MiniMax quanto o ElevenLabs na maior parte do benchmark.
Idiomas com forte desempenho confirmado incluem: Alemão, Árabe, Cantonês, Chinês, Checo, Coreano, Espanhol, Finlandês, Francês, Grego, Hindi, Holandês, Indonésio, Inglês, Italiano, Japonês, Polonês, Português, Romeno, Russo, Tailandês, Turco, Ucraniano, Vietnamita.
Código Aberto
Ao contrário da maioria dos sistemas TTS comerciais, o Fish Audio S2 é totalmente de código aberto — pesos do modelo, código de fine-tuning e um mecanismo de inferência baseado em SGLang pronto para produção — permitindo que desenvolvedores hospedem por conta própria, façam ajustes finos e implementem em escala.
-
GitHub: github.com/fishaudio/fish-speech
-
HuggingFace: huggingface.co/fishaudio/s2-pro
-
Inferência SGLang: SGLang-Omni
Desempenho de produção em uma única GPU H200:
-
Fator de Tempo Real (Real-Time Factor): 0,195
-
Tempo para o primeiro áudio: ~100ms
-
Rendimento (Throughput): 3.000+ tokens acústicos/s
Para clonagem de voz em escala, o S2 coloca tokens de áudio de referência no prompt do sistema. O cache KV do SGLang alcança uma taxa média de acerto de cache de prefixo de 86,4% quando a mesma voz é reutilizada em várias requisições — tornando a sobrecarga de clonagem de voz repetida quase insignificante.
Como Começar
-
Experimente no APP
playground— o fish.audio suporta tags inline do S2 diretamente. Coloque[colchetes]em qualquer lugar do seu roteiro e gere. -
Integre via API — Disponível através da Fish Audio API. Consulte a referência da API para endpoints e autenticação.
-
Hospede o modelo por conta própria — Os pesos e a pilha de inferência são de código aberto no GitHub e no HuggingFace.
-
Em breve: Geração de diálogos com múltiplos locutores no APP e na API da Fish Audio.
-
Para um guia completo da sintaxe das tags inline, regras de posicionamento e dicas: → Como Usar Tags Inline do Fish Audio S2
-
Vindo do S1 e quer entender como os dois sistemas se relacionam: → Tags de Emoção do Fish Audio S1 — Guia Completo
FAQ
O que são tags inline em TTS?
Tags inline são instruções curtas incorporadas diretamente em um roteiro de conversão de texto em fala (TTS) para controlar como uma palavra ou frase específica é falada — a entrega, emoção, ritmo ou qualidade vocal naquele ponto exato. Diferente das configurações globais de voz que se aplicam a toda a geração, as tags inline permitem direcionar momentos individuais dentro de uma fala. O Fish Audio S2 usa [colchetes] para tags inline e aceita descrições em linguagem natural de forma livre.
O que é o Fish Audio S2?
O Fish Audio S2 é o modelo TTS de segunda geração da Fish Audio. Ele suporta controle inline refinado via tags de linguagem natural em [colchetes] colocadas em qualquer lugar de um roteiro, treinado em mais de 10 milhões de horas de áudio em cerca de 80 idiomas. É de código aberto no GitHub e HuggingFace, e está disponível através da API e do APP~~ playground~~ da Fish Audio.
Como funcionam as tags inline no S2?
Coloque uma tag em [colchetes] imediatamente antes da palavra ou frase que ela deve afetar. Você pode usar tags bem testadas como [sussurrando], [suspiro] ou [pausa longa], ou escrever qualquer descrição em linguagem natural de forma livre. As tags se aplicam a tudo o que segue até a próxima tag ou o fim da frase.
O Fish Audio S2 é de código aberto?
Sim. Os pesos do modelo, o código de fine-tuning e o mecanismo de inferência baseado em SGLang são de código aberto em github.com/fishaudio/fish-speech e huggingface.co/fishaudio/s2-pro
Quantos idiomas o S2 suporta?
O S2 é treinado em aproximadamente 80 idiomas. Em um benchmark multilíngue de 24 idiomas, o S2 alcançou a melhor taxa de erro de palavras em 11 idiomas e a melhor similaridade de locutor em 17, superando o MiniMax e o ElevenLabs.
O S2 suporta a sintaxe de parênteses () do S1?
Não. O S2 usa [colchetes] nativamente. A interface web da Fish Audio traduz automaticamente () para [] quando o S2 é selecionado, mas se você estiver usando a API diretamente, use colchetes.
O S2 suporta diálogo com múltiplos locutores?
A geração com múltiplos locutores chegará em breve ao APP e à API da Fish Audio. O modelo suporta isso nativamente — fique atento ao lançamento.
Qual é a diferença entre o Fish Audio S1 e o S2?
O S1 usa um vocabulário fixo de tags de emoção predefinidas em (parênteses), colocadas no início das frases. O S2 usa tags de linguagem natural de domínio aberto em [colchetes] que podem aparecer em qualquer lugar do roteiro — no meio da frase, entre palavras ou no início. O S2 também aceita descrições de forma livre em vez de uma lista fechada de palavras-chave, portanto você não está limitado a emoções predefinidas. Para uma análise completa, consulte o Guia de Tags de Emoção do Fish Audio S1.
O Fish Audio S2 pode substituir o SSML?
Para a maioria dos casos de uso expressivo, sim. O Fish Audio S2 pode replicar muitos controles do estilo SSML através de tags inline em linguagem natural — em vez de marcação XML como <prosody rate="slow">, você escreve [falando devagar] diretamente no roteiro. Tags como [sussurrando], [pausa longa] e [irritado] cobrem as funções expressivas mais comuns do SSML sem exigir conhecimento de marcação especializada.
As tags inline do Fish Audio S2 são compatíveis com outros sistemas TTS?
Não. A sintaxe das tags inline no Fish Audio S2 é específica do modelo. Outros sistemas TTS usam SSML ou seus próprios formatos proprietários. No entanto, os conceitos expressivos subjacentes — pausas, mudanças de tom, pistas vocais — traduzem-se conceitualmente ao alternar entre sistemas, mesmo que a sintaxe seja diferente.
Recursos relacionados:

Sabrina is part of Fish Audio's support and marketing team, helping users get the most out of AI voice products while turning launches, updates, and customer insights into clear, practical content.
Leia mais de Sabrina Shu






